
このページは解答編です。
↓ネ
↓タ
↓バ
↓レ
↓防
↓止
答えと解説
設問はこちらでした。
P-087: 顧客データ(customer.csv)では、異なる店舗での申込みなどにより同一顧客が複数登録されている。名前(customer_name)と郵便番号(postal_cd)が同じ顧客は同一顧客とみなして1顧客1レコードとなるように名寄せした名寄顧客データを作成し、顧客データの件数、名寄顧客データの件数、重複数を算出せよ。ただし、同一顧客に対しては売上金額合計が最も高いものを残し、売上金額合計が同一もしくは売上実績がない顧客については顧客ID(customer_id)の番号が小さいものを残すこととする。
解答ワークフローは以下のようになります。
複雑な条件で名寄せをする問題です。しかしながら、現実的にはこれくらいの処理が必要になってくるかと思います。ただし、現実世界ではこれくらい最初から要件が整っていればよいのですが、往々にして後から後から条件が判明する、というケースもよく見る光景かと思います・・・。
問題文には出てきませんが、「同一顧客に対しては売上金額合計が最も高いものを残し、売上金額合計が同一もしくは売上実績がない顧客については顧客ID(customer_id)の番号が小さいものを残すこととする。」という記述がある通り、receipt.csvを組み合わせて解く必要があります。
それでは、まず後半の条件を達成するために、顧客IDごとに売上を集計していきましょう。そのためにまずセレクトツールでデータ型を変更していく必要があります。
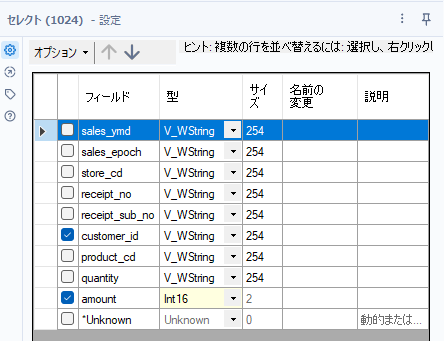
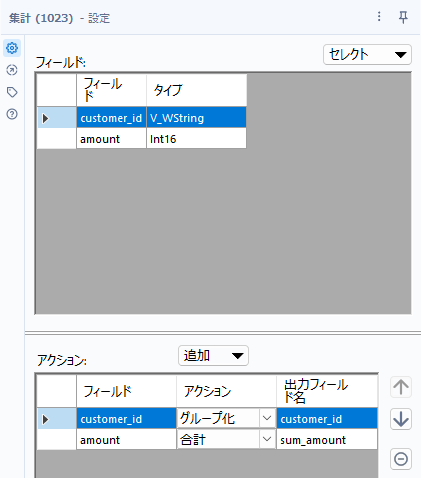
次に、集計ツールを使ってcustomer_idごとに合計していきましょう。customer_idでグループ化し、amountの合計を取ります。
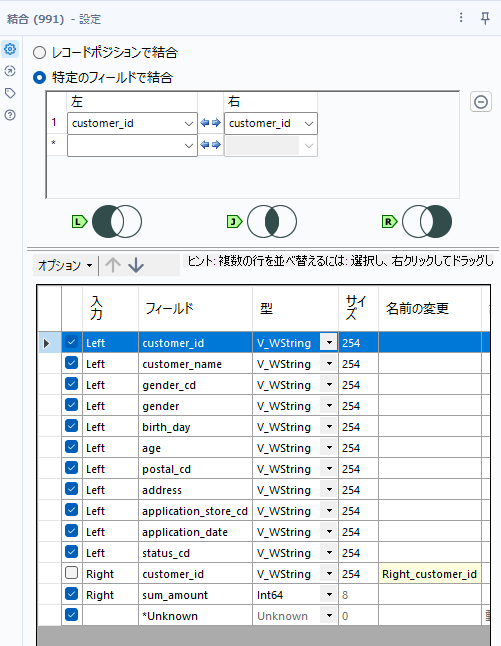
この集計したデータをcustomer.csvに結合していきましょう。結合ツールを使います。キーフィールドはもちろんcustomer_idです。
なお、売上がない顧客もいるため、結合ツールのL出力側にもデータが出てきています。もちろんこのようなデータも使う必要があるので、ユニオンツールで結合しましょう。以下のように接続します。
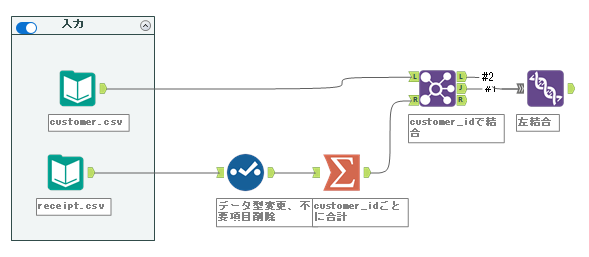
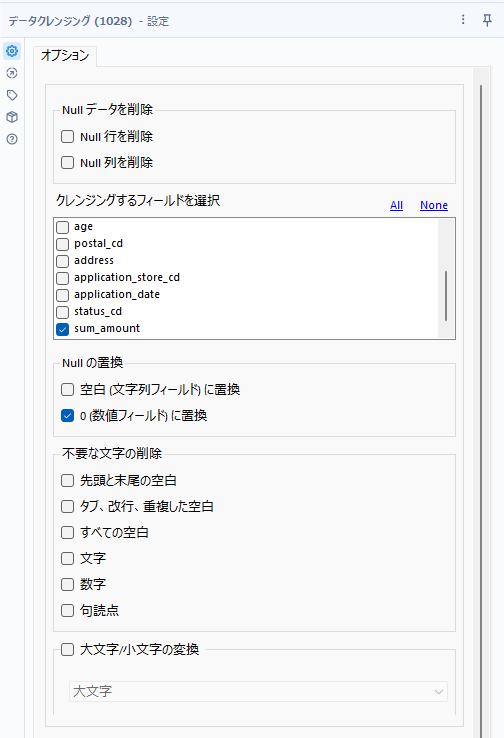
L出力のデータは売上(sum_amount)がNullになっているため、0に置き換えて行きたいと思います。フォーミュラツールなどでもできますが、今回はデータクレンジングツールを使っていきたいと思います。「sum_amount」フィールドのみにチェックを付け、Nullの置換の「0に置換」を選択しましょう。
ちなみに、速度重視ならフォーミュラツールを使うことをおすすめします。
ここまででデータの準備が完了しました。ここからいよいよ核心部分となります。基本的な手法として、ユニークなものを残すためにソートツールとサンプリングツールを使っていきます。サンプリングツールのグループ化機能を使い、ユニークにしたいフィールドをグループ化として設定し、先頭から1件を抽出することでユニークなデータを得られます。この際に、条件に合わせて並べ替え、残したいデータを先頭に持ってくることで、指定した条件でのデータの抽出(名寄せ)が可能となります。
名寄条件を改めて見てみましょう。「名前(customer_name)と郵便番号(postal_cd)が同じ顧客は同一顧客とみなして1顧客1レコードとなるように名寄せした名寄顧客データを作成し、顧客データの件数、名寄顧客データの件数、重複数を算出せよ。ただし、同一顧客に対しては売上金額合計が最も高いものを残し、売上金額合計が同一もしくは売上実績がない顧客については顧客ID(customer_id)の番号が小さいものを残すこととする。」というものです。
同一顧客とみなすのは、customer_nameとpostal_cdです(上の条件の赤い部分です)。つまり、サンプリングツールを使用する際にグループ化するのはこの2つの項目です。
次に、残したいものとして、は「売上金額が高いものが1番。売上金額が同一もしくは0の場合は顧客IDが小さいもの」(上の条件の緑の部分)となるので、売上金額の降順、顧客IDの昇順に並び替えることになります。
ということで、まずはソートツールの設定です。
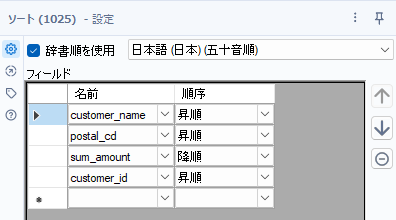
あとで確認しやすくするため、customer_nameとpostal_cdでも昇順でソートしていますが、なくても結果は同じです。その他、sum_amountの降順、customer_idの昇順で並べ替えします。sum_amountとcustomer_idの順序は守るようにしてください。
次に、サンプリングツールを使います。「最初のN行」を選択し、Nは「1」、列でグループ化するオプションは、「customer_name」と「postal_cd」にチェックを入れます。
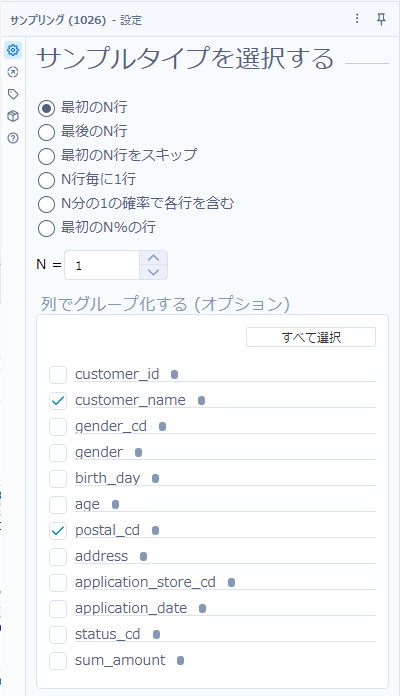
これで欲しいデータは得られました。
最終的な解答としてはそれぞれのカウントとカウントの差分を取っていきますので、それぞれレコードカウントツールを接続していきましょう。
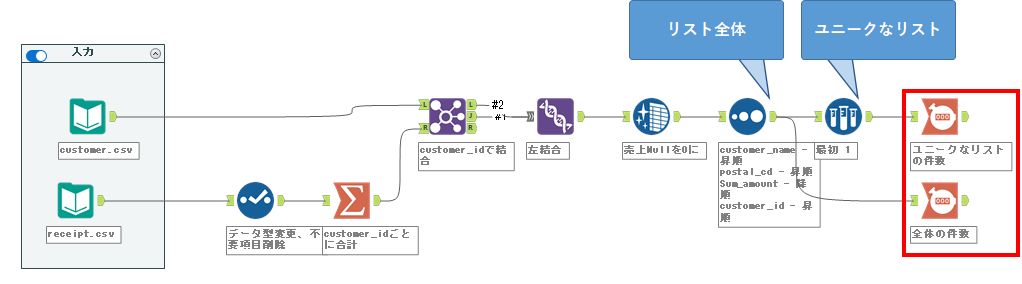
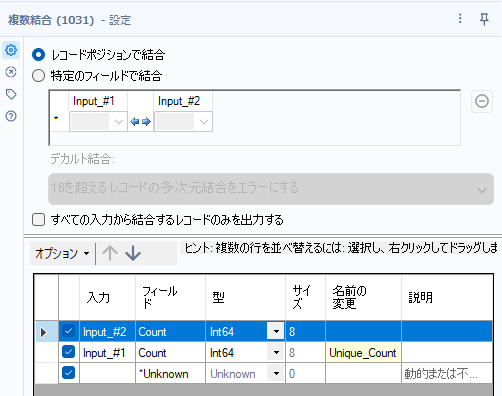
あとはこれをまとめて引き算で計算するだけです。1レコードのみのデータを結合する場合はフィールド付加ツール、結合ツール、複数結合などどれでも可能です。今回は、複数結合ツールを使います。名前を適切な形にします(フィールドの位置も変えています)。
その後、フォーミュラツールで差分を取ります。フィールド名は「diff」、データ型は数値型にしましょう。
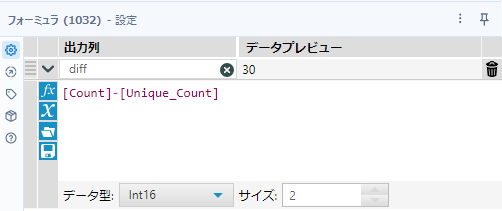
[Count]-[Unique_Count]これで完了です。
まとめ
名寄の問題でした。条件が複雑になると、ユニークツールだけでは対応できず、ある程度ワークフローを作り込む必要があります。現実の名寄せであれば最低限これくらいの条件はあるかと思います。さらに複雑なケースも考えられます。ソートツールとサンプリングツールを使ってデータの抽出方法は応用が効くので覚えておいていただければと思います。

コメント