
このページは解答編です。
↓ネ
↓タ
↓バ
↓レ
↓防
↓止
答えと解説
設問はこちらでした。
P-010: 店舗データ(store.csv)から、店舗コード(store_cd)が”S14″で始まるものだけ全項目抽出し、10件表示せよ。
解答ワークフローは以下のようになります。
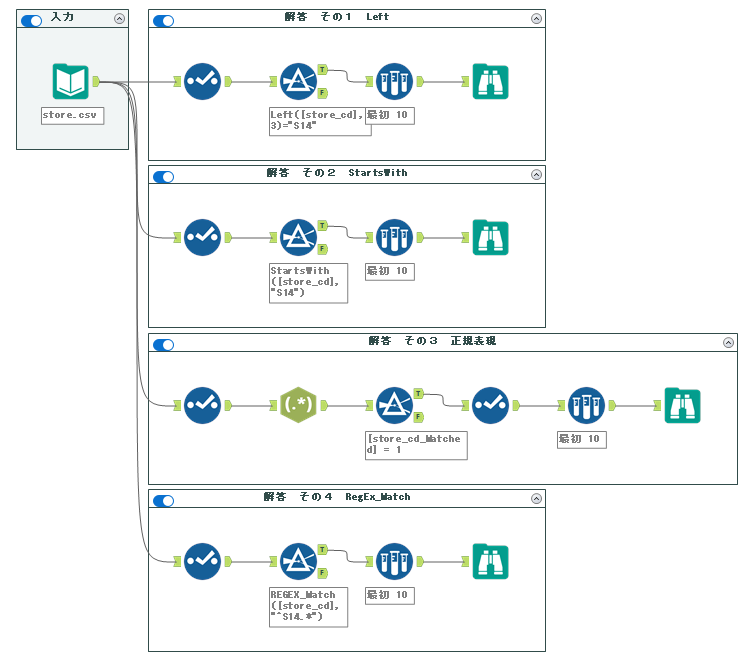
単純な内容ですが、様々な解法があります。基本的にはフィルターツールを使いますが、判定方法は様々です。
- Left関数で切り取って比較
- StartsWith関数
- 正規表現ツール
- REGEX_Match関数
1. Left関数で切り取って比較
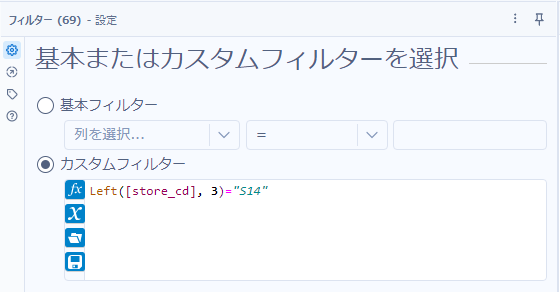
「店舗コード(store_cd)が”S14″で始まる」ということなので、頭から3文字切り取って比較することが可能です。このような場合は、Left関数が利用可能です。Left関数の使い方は、
Left(対象文字列, 切り取る文字数)
となります。つまり、今回であれば以下の通りとなります。
Left([store_cd], 3) = "S14"フィルタツールの設定としては以下の通りとなります。
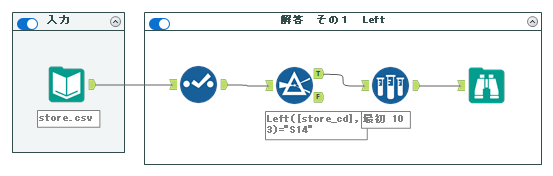
ワークフローとしては以下の通りとなります。
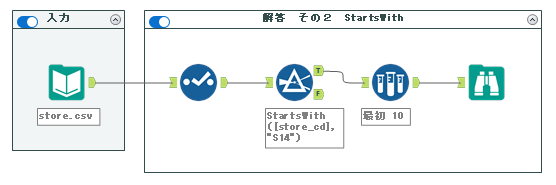
2. StartsWith関数
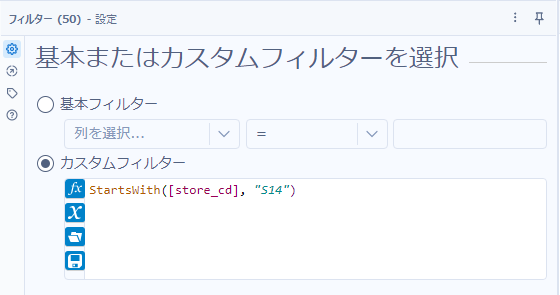
「店舗コード(store_cd)が”S14″で始まる」ということなので、StartsWith関数が利用可能です。最もスタンダードな手法がこちらになります。関数の使い方としては、
StartsWith(検索先文字列, 検索文字列)
となります。つまり、今回であれば以下のようになります。
StartsWith([store_cd], "S14")フィルターツールの設定は以下のとおりとなります。
ワークフローは以下の通りとなります。
3. 正規表現ツール
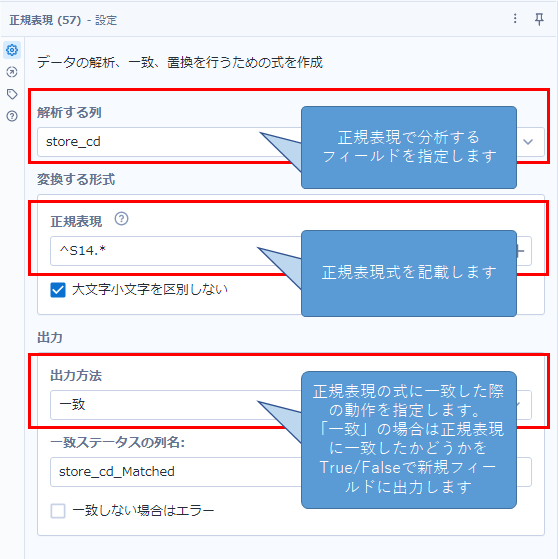
若干高度な手法になりますが、正規表現ツールを使うこともできます。まずは使い方を見てみましょう。基本的な使い方としては、「解析する列」に正規表現で分析したいフィールドを指定します。次に、出力方法を選びます。出力方法としては、「置換」「トークン化」「解析」「一致」とありますが、今回のように正規表現式に一致しているかどうかを出力したい場合は「一致」を選択します。
正規表現ツールで一番難しいのは正規表現の式を作成することです。
今回は、「店舗コード(store_cd)が”S14″で始まる」ということなので、「^S14.*」という式になっていますが、それぞれ以下のような意味となります。
^ : 行頭であることを示します
S14 : 「S14」という文字列です
.* : 0文字以上の文字列を示します(「.」は文字1文字(アルファベットでも記号でも数字でもなんでもよいです)、「*」は直前の文字0以上の繰り返し、を意味します)
これにより、「行頭からS14で始まる文字列」という形になります。実際のツールの設定は以下の通りです。
実際のワークフローは以下のようになります。
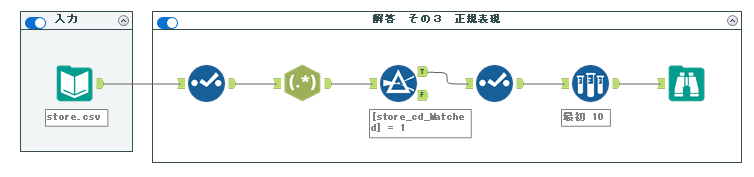
正規表現ツールの出力を「一致」設定にすると、設定したフィールド名(今回であれば、「store_cd_Matched」)が作成され、マッチしていればTrue、していなければFalseが出力されます。このフィールドに対してフィルタをかけています。その後、不要になった「store_cd_Matched」をセレクトツールで削除しています。
4. REGEX_Match関数
こちらも若干高度な方法になりますが、正規表現ツールを使う代わりに、REGEX_Match関数を使うことで使用するツールの数を減らす方法をご紹介します。
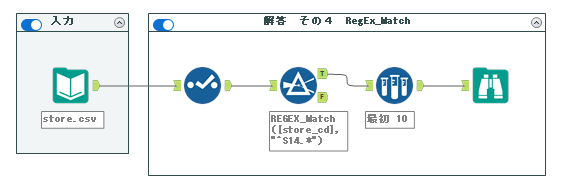
フィルターツールで使うREGEX_Match関数は以下のように使います。
REGEX_Match(検索文字列, 正規表現式)
今回であれば以下のようになります。
REGEX_Match([store_cd], "^S14.*")ここで設定する正規表現式は、解答その3の正規表現ツールに設定した式と同様です。

コメント