
e-Statの国勢調査の地区町村レベルの統計データであれば、Excelファイルなどで一括で入手可能です。しかしながら、小地域(町丁・字等)になるとCSVファイルで小分けにされており、ダウンロードするのは大変です。
しかし、APIであれば連続的に一括で取得することが可能です。
今回は小地域(町丁・字等)の国勢調査のデータをAPIでダウンロードしてみたいと思います。
APIを使う前準備
e-StatのAPIを使うためには、e-Statへの登録が必要となります。登録することで、APIにアクセスする際に必要となるアプリケーションIDを取得することが可能です(マイページの「API機能(アプリケーションID発行)」にてアプリのURLと名称を入力すれば発行できます)。
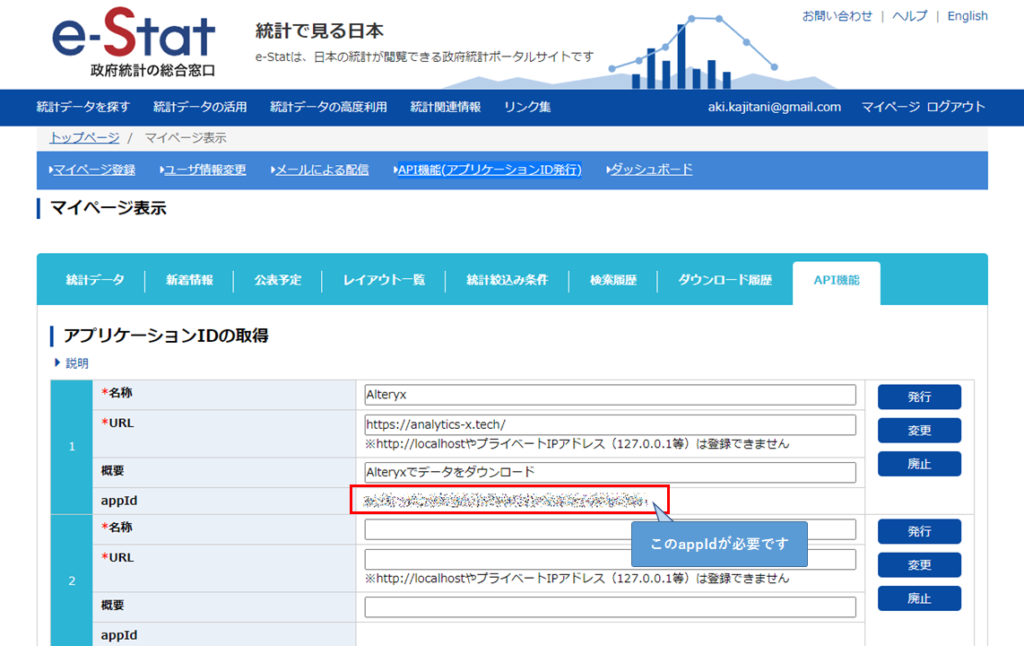
APIを使うのに必要になるもの
まず、最初に開発ガイドを眺めたほうが良いのですが、結論として何があれば目的のデータにたどり着けるのでしょうか?
まず、統計データを取得するには「統計データ取得API」を使用します。ここがゴールですね。
「統計データ取得API」で欲しいデータを指定するには、「統計表ID」が必要になります。「統計表ID」は、「統計表情報取得API」から検索することが可能です。「統計表情報取得API」には、「政府統計コード」が必要になります。
ということで、出発点は「政府統計コード」となります。しかしながら、この「政府統計コード」はなぜかPDFファイルでの配布となっています(なんでやねん!)。
ということで、今回は「国勢調査」のデータがほしいので、PDFファイルを「国勢調査」で検索すると、「政府統計コード」は「00200521」であることが判明します。これと調査年度がわかれば「統計表情報取得API」を使うことが可能です。
それでは順を追って行きましょう。
統計表情報取得APIを使う
統計表情報取得APIのエンドポイントのURLは以下のようなものになります。
http(s)://api.e-stat.go.jp/rest/<バージョン>/app/getStatsList?<パラメータ群>これは、XML形式としてデータを取得するためのURLです(取得形式によってURLが異なります)。小地域はバージョン3.0にしか入っていないとのことなので、3.0を使います(ちなみに、旧バージョンも並行して提供されています)。
また、すべてのAPIで共通なパラメータとして以下を与えます。
| パラメータ名 | 内容 | 与えるパラメータ |
|---|---|---|
| appId | アプリケーションID | appId=[ご自身のappId] |
| lang | 言語 | lang=J |
その他以下のようなパラメータを渡します。
| パラメータ名 | 内容 | 与えるパラメータ | コメント |
|---|---|---|---|
| surveyYears | 調査年月 | surveyYears=2020 | 今回は2020年度のデータを取得 |
| statsCode | 政府統計コード | statsCode=00200521 | 政府統計コード一覧から取得したコード。国勢調査は「00200521」 |
| searchKind | 検索データ種別 | searchKind=2 | 小地域・地域メッシュは「2」 |
これにより、以下のようなURLとなります。
https://api.e-stat.go.jp/rest/3.0/app/getStatsList?appId=[appId]&lang=J&statsCode=00200521&surveyYears=2020&searchKind=2appIdなどは利用する人によって異なるため、あまりフォーミュラツールに埋め込むのはよくありません。また、年度も今後変わる可能性があるので外だしにしておきましょう。テキスト入力ツールに値を入れてそこを出発点としたいと思います。
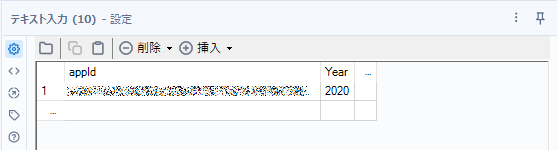
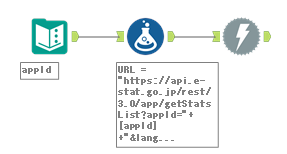
ここからフォーミュラツールに接続します。フォーミュラツールでは以下のようにURLを作成します。
"https://api.e-stat.go.jp/rest/3.0/app/getStatsList?appId="+[appId]+"&lang=J&statsCode=00200521&surveyYears="+ToString([Year])+"&searchKind=2"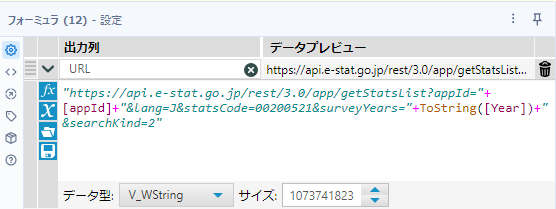
このURLを使ってダウンロードツールでアクセスします。以下のような設定になります。

出力は、フィールドに文字列とします。
その他必要な設定としては、「ペイロード」タブにて、HTTPアクションを「GET(またはFTP)」とします(基本的にはデフォルト設定です)。
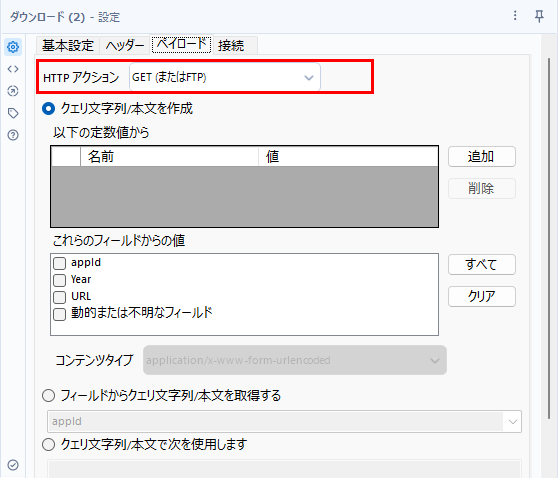
その他設定は不要です。ここまでで以下のようなワークフローとなります。
落としたデータを加工していく
まず不要な項目をセレクトツールで削除します。これを行わないとXMLパースツールでパースする際に無駄にフィールドの値がコピーされ、メモリを消費します。
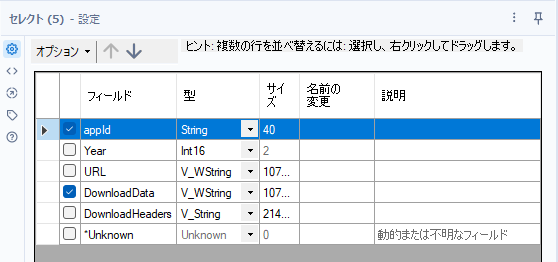
appIdは後で使うので取っておきましょう。
それでは、ダウンロードできたデータを加工していきましょう。今回XML形式で落としたのでXMLパースツールを使います。基本的にデフォルト設定でオッケーです。
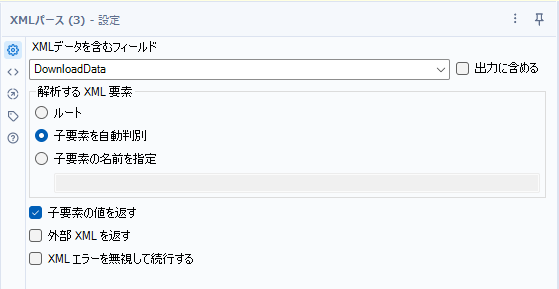
これにより、中身のデータが各フィールドにパースされますが、ここで一番必要なのは、次のステップで使う「統計表ID」です。これは、「Id」という項目で得られます。
その他、「TITLE」というフィールドには、データの種別が格納されますが、都道府県名も一緒にくっついて出てきます。列分割ツールでデータ種別と県名を分割してみましょう。今回は区切り文字を「\s」とし、列に分割し、列数は「2」とします。
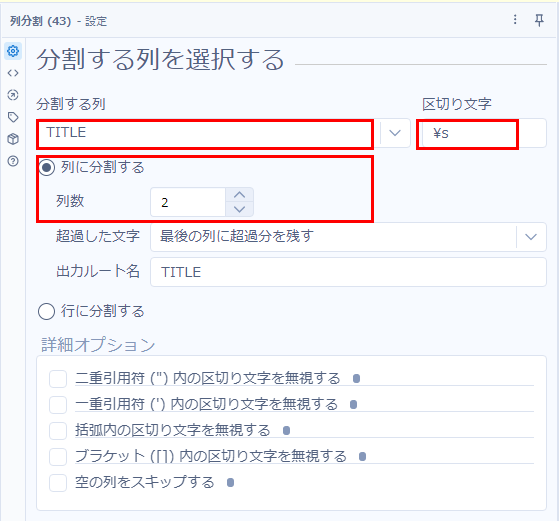
これにより、タイトルをユニークで取ると、どのようなデータが取得できるのかわかります。つまり以下のような内容が取得可能なようです。
- 世帯の家族類型別一般世帯数
- 世帯の経済構成別一般世帯数
- 世帯人員別一般世帯数
人口及び世帯※これは小地域ではなくメッシュでの提供でした- 住宅の建て方別世帯数
- 住宅の所有の関係別一般世帯数
- 年齢(5歳階級、4区分)別、男女別人口
- 産業(大分類)別及び従業上の地位別就業者数
- 男女別人口総数及び世帯総数
- 職業(大分類)別就業者数
それぞれ取得できる項目が異なるので、それぞれ個別にダウンロードして加工する必要があります。
また、「OVERALL_TOTAL_NUMBER」というフィールドには、格納されているレコード数が格納されます。ちなみに、各都道府県ごとに「統計表ID」が異なるため、別々のレコードとして出てきます。
ここでポイントなのが「OVERALL_TOTAL_NUMBER」でして、e-StatのAPIは一度に取得できるレコード数は10万件と決まっています。ですので、10万件を超える場合は、StartPositionオプションでダウンロードするレコードの場所を指定する必要があります。つまり、1レコードから、10万件ごとに新たなレコードを作って新たなURLを生成する必要があります。このような場合に使えるのが「行生成」ツールです。設定は以下のような形になります。
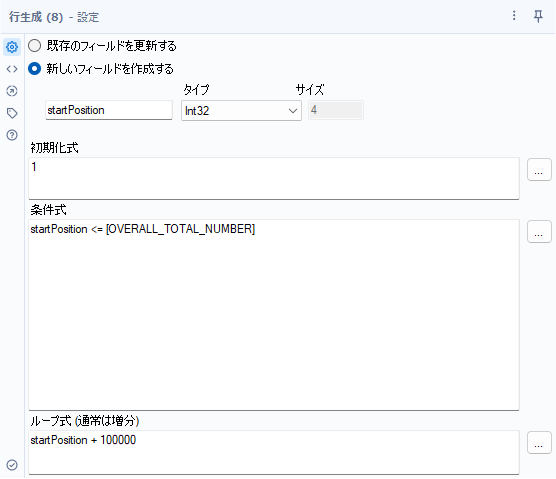
ここで、一旦欲しい「統計表ID」がすべて手に入ったことになります。ここまでのワークフローは以下のとおりです。
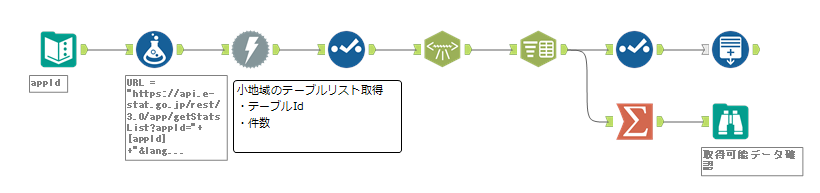
長くなってきたので、一旦ここで切りたいと思います。次回はサンプルとして「男女別人口総数及び世帯総数」を取得していきたいと思います。
基本単位区はどこにいった?
基本単位区は、「男女別人口及び世帯数-基本単位区」のみがありそうですが、CSVでの提供に限られているようです(すみません、全てを見切れていないかもしれません)。うまく検索すれば一括ダウンロードが可能なので、そちらを利用する手もありそうです。ただ、ファイルパスは類推しにくいものになっているので、何かしら手段を考える必要がありそうです。
コメント