
このページは解答編です。
↓ネ
↓タ
↓バ
↓レ
↓防
↓止
答えと解説
設問はこちらでした。
P-060: レシート明細データ(receipt.csv)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、売上金額合計を最小値0、最大値1に正規化して顧客ID、売上金額合計とともに10件表示せよ。ただし、顧客IDが”Z”から始まるのものは非会員を表すため、除外して計算すること。
※出力は、フィールド名をscale_amountとし、customer_idの昇順とすること
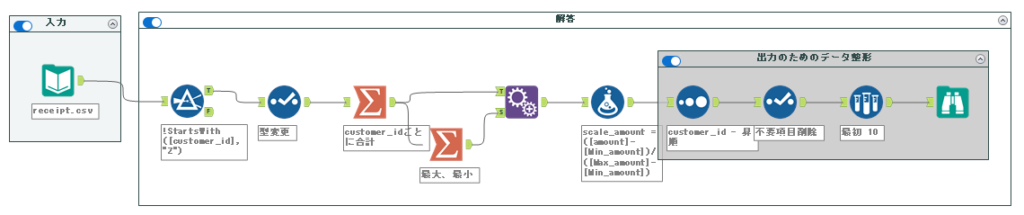
解答ワークフローは以下のようになります。
今回は、正規化を行う問題です。
データのばらつきを確認するための指標になりますが、正規化は、最小値を0とし、最大値を1とするスケーリング方法となります。似たようなものとして、59問目で行った標準化というものがあり、こちらは平均値を0、分散を1とするスケーリング方法です。いずれも機械学習のデータの前処理等でよく使われます。正規化ははずれ値に弱いという弱点があるので、場合によって使い分ける必要があります。
正規化の計算方法
正規化の計算方法ですが、定義として「最小値を0、最大値が1になるようにスケーリングする」ということになります。つまり、標準化したいフィールドの各値に対して最小値を引き、(最大値-最小値)で割れば良い、ということになります。定義としては以下の通りとなります。

ということなので、最小値と最大値を求める必要があるわけです。
実際のワークフロー
それでは、実際のワークフローを作っていきましょう。途中までは59問目の標準化と同じやり方になります。
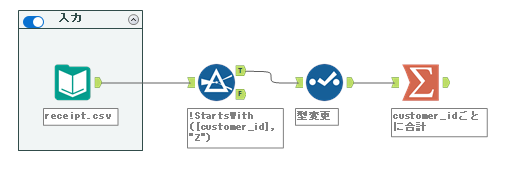
まず、顧客ID(customer_id)がZで始まるレコードをフィルターツールで取り除きます。カスタムフィルターで、「!StartsWith([customer_id], “Z”)」で取り除けます。
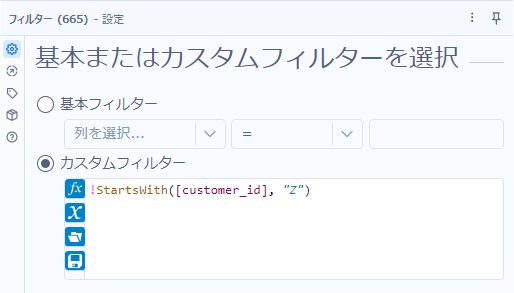
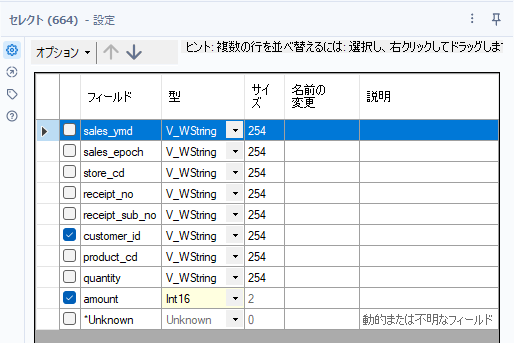
!StartsWith([customer_id], "Z")次に、amountについて型変更を行います。セレクトツールを使い数値型(Int16)に変更します。ついでに不要なフィールドも削除しておきましょう。
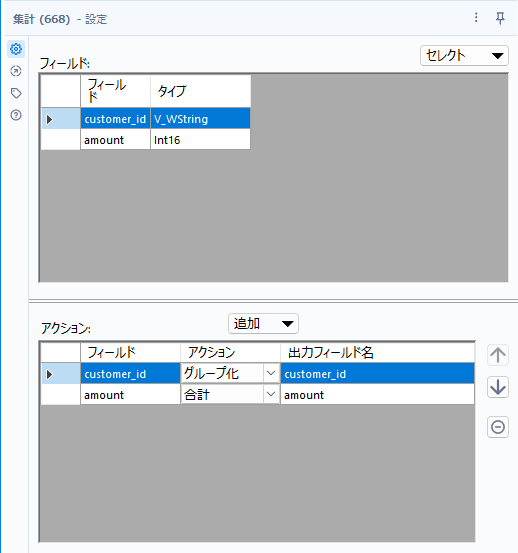
その後、customer_idごとにamountを合計します。もちろん集計ツールを使いますが、customer_idでグループ化し、amountの合計を取ります。
ここからはこのデータを使っていく形になります。標準化とここまではやり方は同じです。このデータを①としましょう。
正規化
まず、最小値、最大値を取ります。
まず、集計ツールを使い、amountに対して最大値、最小値を取ります。
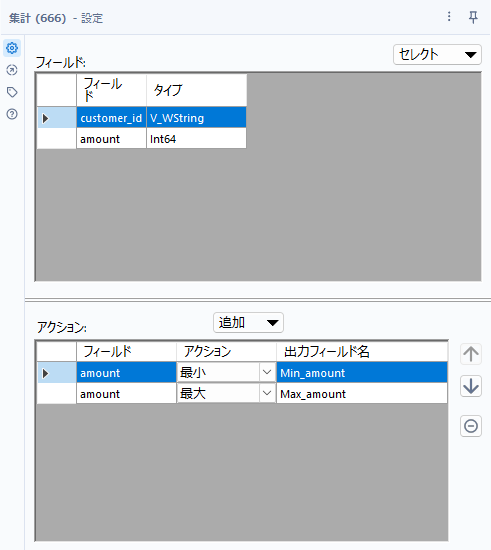
これらの値を①に付与します。フィールド付加ツールを使います。接続自体は以下のようになります。
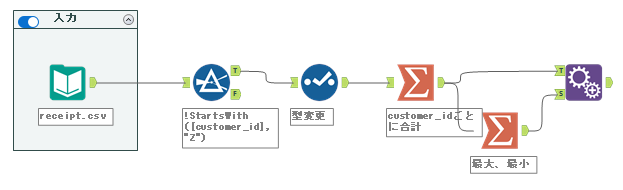
その後、標準化の計算をしていきます。フォーミュラツールを使います。
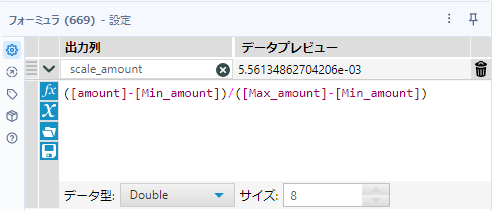
([amount]-[Min_amount])/([Max_amount]-[Min_amount])あとは、customer_idの昇順に並べ、不要な項目を削除し、先頭から10レコードを取得します。最終的なワークフローは以下の通りとなります。
まとめ
今回は、正規化を行う問題でした。定義がわかっていればそれほど難しい問題ではありません。

コメント