
このページは解答編です。
↓ネ
↓タ
↓バ
↓レ
↓防
↓止
答えと解説
設問はこちらでした。
P-089: 売上実績がある顧客を、予測モデル構築のため学習用データとテスト用データに分割したい。それぞれ8:2の割合でランダムにデータを分割せよ。
※全体のレコード数を「TotalCount」、学習データのレコード数を「Count」とし、学習データの割合を出力すること(フィールド名は「学習データ割合」とする)
解答ワークフローは以下のようになります。
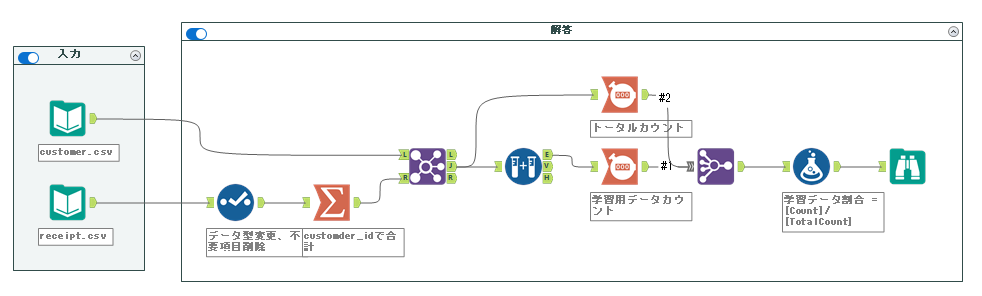
問題は言葉少なく記載されていますが、customer.csvに対して売上実績がある顧客を抽出する必要があるためreceipt.csvも使っていきます。
また、機械学習のための学習用データ、テストデータの分割にはサンプル作成ツールが使えます。名前が似たサンプルなんちゃらというツールがいくつかあるので紛らわしいですが、サンプル作成ツールはこれ以外の用途にはあまり使わないかと思います。
サンプル作成ツール

サンプル作成ツールはまさに機械学習を使う時の基本のツールです。機械学習で予測などする際は、学習データ、検証データ、ホールド(予備)データという形で3つにわけることが多いです。
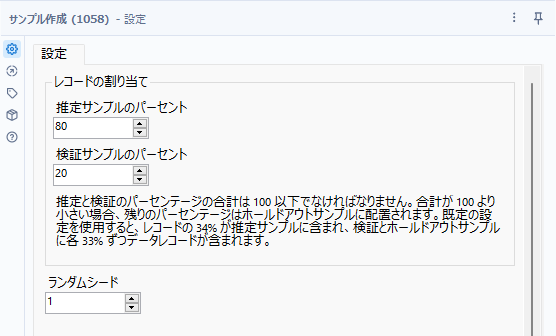
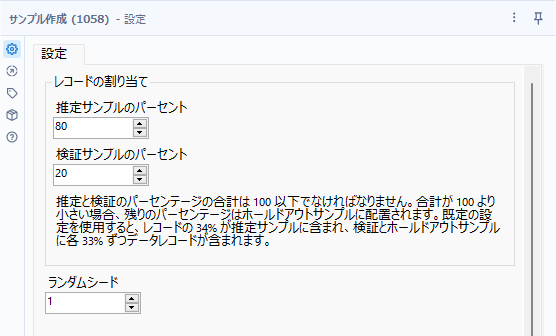
設定はシンプルで、以下のとおりです。
| オプション名称 | 値 | 内容 |
|---|---|---|
| 推定サンプルのパーセント | 数値 | 学習用に使うデータ。E出力から出力されます。一般的には60%~80%程度 |
| 検証サンプルのパーセント | 数値 | 検証用に使うデータ。V出力から出力されます。一般的には20%程度。推定サンプルと検証サンプルを合計して100%にならない場合は、余った分はホールドとしてH出力に出力されます。 |
| ランダムシード | 数値 | 基本的にランダムでデータは出力されますが、シード値を指定することが可能です。そのため、毎回出力結果は同じです(シード値を変えると別のランダムパターンになります) |
実際のワークフローを作る
それでは、まずreceipt.csvから手を付けていきましょう。
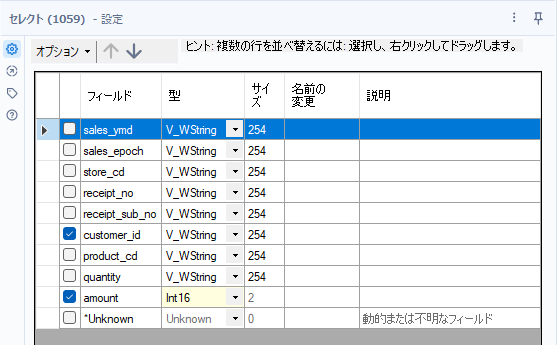
まず集計のためにセレクトツールを使ってデータ型の変更と不要項目の削除を行っていきます。amountは数値型(Int16)にしていきます。
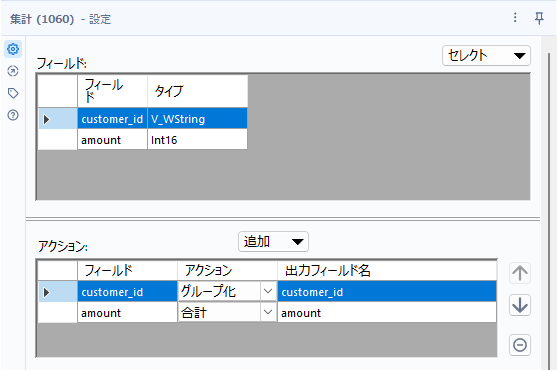
続いて、集計ツールで集計を行いましょう。customer_idでグループ化し、amountの合計を取ります。
その後、customer.csvと結合ツールを使って結合していきます。customer.csvから結合ツールのL入力、集計の結果はR入力に接続し、キーフィールドはcustomer_idで結合を行います。不要な項目は削除しておきましょう。
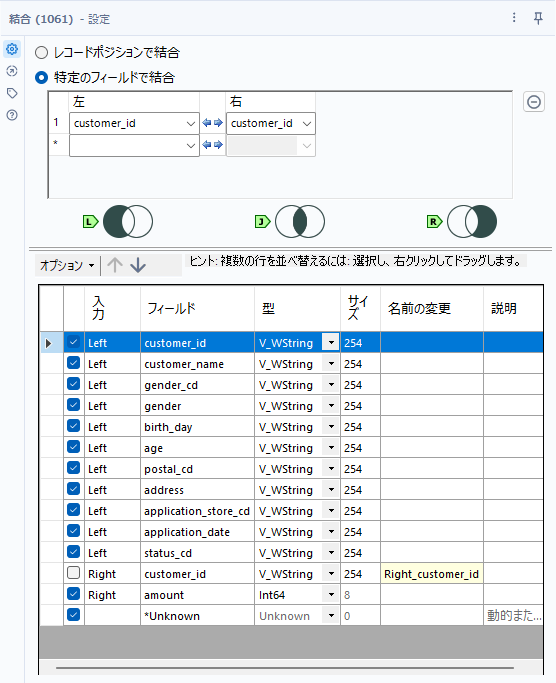
この段階では以下のように接続されています。
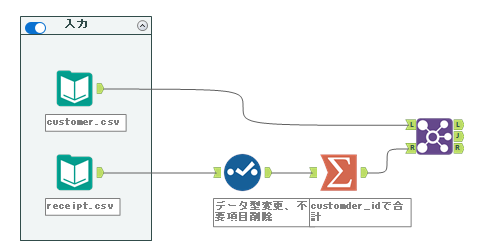
欲しいデータはJ出力のデータです。今回は、売上実績がある顧客のデータを使いたい、ということなので、receipt.csvにデータがある顧客がまさに売上実績のある顧客となります。
ということで、J出力にサンプル作成ツールを接続します。設定は問題文の通りで、推定サンプルのパーセントは「80」、検証サンプルのパーセントは「20」とします。
基本的には、これで目的は達成されるのですが、実際に分割されたカウント数の割合を出していきましょう。結合ツールのJ出力とサンプル作成ツールのE出力にそれぞれレコードカウントツールを接続し、カウントを出していきます。その後、複数結合ツールでカウントデータをまとめます。
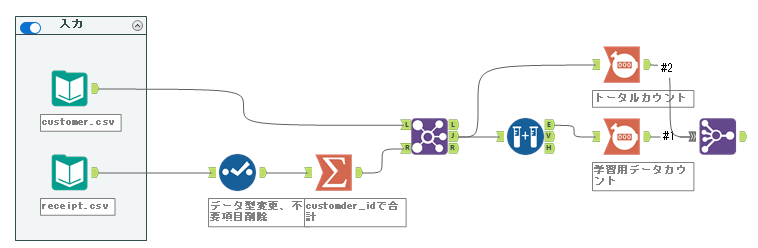
レコードポジションで結合します。それぞれフィールド名は変えておきましょう(フィールドの順番も)。
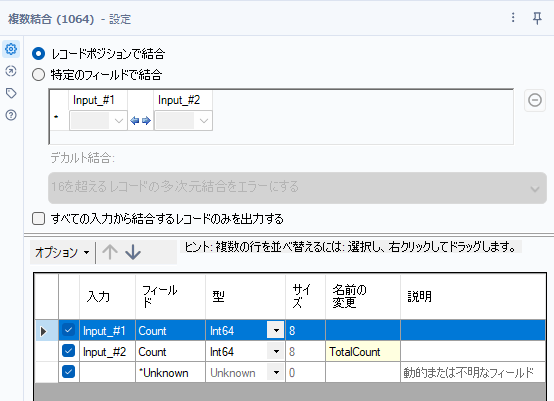
最後にフォーミュラツールで割合を計算していきましょう。フィールド名は「学習データ割合」とし、データ型は数値型(Double)とします。
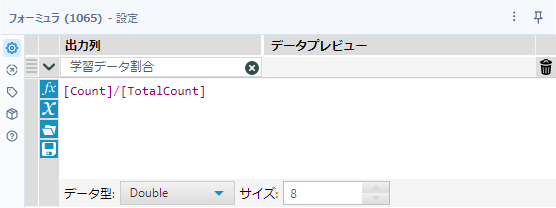
[Count]/[TotalCount]これで完了です。
まとめ
機械学習の際のデータの準備の触りをやるような問題でした。通常、機械学習を行うにはここから線形回帰やランダムフォレストなどのツールを接続していく形となります。

コメント