
このページは解答編です。
↓ネ
↓タ
↓バ
↓レ
↓防
↓止
答えと解説
設問はこちらでした。
P-091: 顧客データ(customer.csv)の各顧客に対し、売上実績がある顧客数と売上実績がない顧客数が1:1となるようにアンダーサンプリングで抽出せよ。
※売上実績がある顧客、ない顧客の状況を示すフィールド名を、is_buy_flagとし、売上実績あればYes、なければNoを格納すること
※解答は、最終的にYes、Noのカウントを出力すること
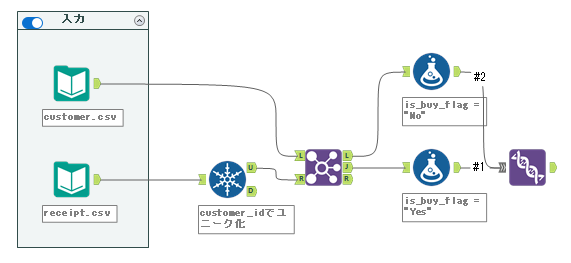
解答ワークフローは以下のようになります。
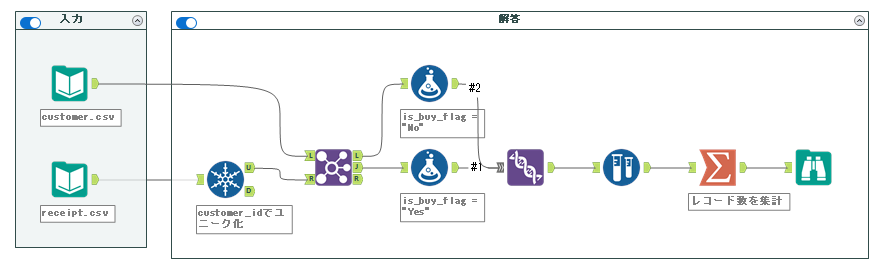
今回も予測モデル構築の前準備といった趣の問題となります。
アンダーサンプリングとは
予測するデータに偏りがある場合、良いモデルが構築できません。その場合、多数派のデータを削除し、少数派のデータと数を近くすることで予測モデルの精度を上げることができます。このような処理をアンダーサンプリングと言います。
これをAlteryxで実現するのが、オーバーサンプルフィールドツールです。
オーバーサンプルフィールドツール

予測するデータに偏りがある場合に少数派のデータを計算で増やすような手法をオーバーサンプリングといいますが、このツールの名前が似ているため非常に紛らわしいかと思います。実際にこのツールができることは「アンダーサンプリング」です。間違えないようにお願いします!
例えば、住宅ローンをほとんどの人は返すと思いますが、一部の人は返せないことがあるかと思います。おそらく「返す人>>返さない人」となっており、返さない人を予測したいのに予測するために入手したデータはほとんどが「返す人」なのではないかと思います。
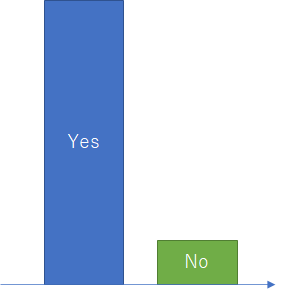
このような場合、返す人の予測は行いやすいのですが、返さない人の予測は難しい、ということになってしまいます。
このような場合にアンダーサンプリングする(多数派のYesのデータをサンプリングして数を減らします)ことで、データ量として同じくらいにして学習し、予測精度のアップにつなげることが可能です。
さて、実際の設定は以下のようになります。
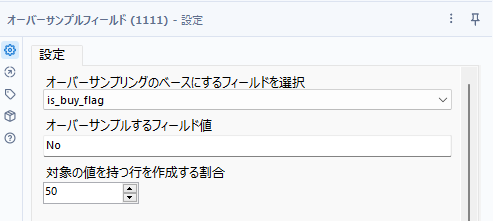
| 設定項目名 | 値/型 | 説明 |
|---|---|---|
| オーバーサンプリングのベースにするフィールドを選択 | 文字列フィールド | アンダーサンプリングする対象フィールド |
| オーバーサンプルするフィールド値 | 文字列型 | 少数派のデータの値を指定 |
| 対象の値を持つ行を作成する割合 | 整数(1~100) | 少数派のデータの占めるレコードの割合 |
つまり、住宅ローンで考えた場合、少数派の「返さない人」を表すラベルを「オーバーサンプルするフィールド値」に指定します。
実際のワークフロー作成
それでは実際のワークフローを作っていきましょう。今回は、売上のある顧客とない顧客の顧客数が半分ずつになるようにアンダーサンプルする必要があります。実際のデータとしては、かなりの顧客の販売実績がないということになります。
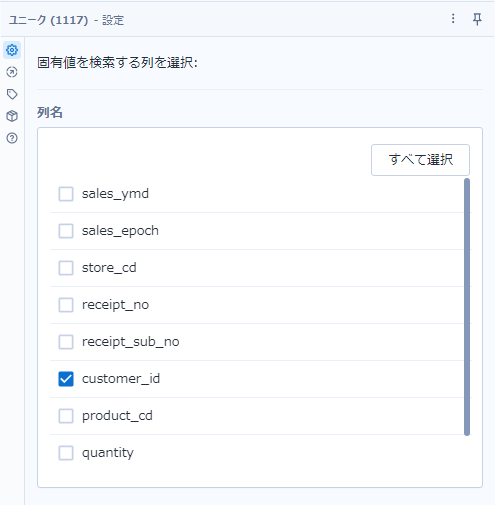
まず、販売実績のある顧客をreceipt.csvから抽出します。これは、customer_idに対してユニークツールを適用していきます(customer_idのみにチェックを入れます)。
次に、customer.csvとこのデータを結合します。結合ツールを使っていきましょう。
キーフィールドは「customer_id」です。R入力(receipt.csvだったもの)側のデータ自体は使わないためすべてチェックを外してオッケーです。
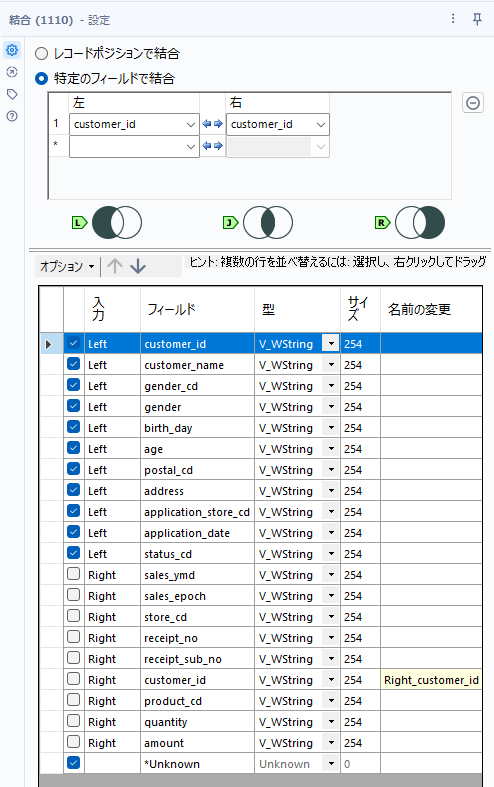
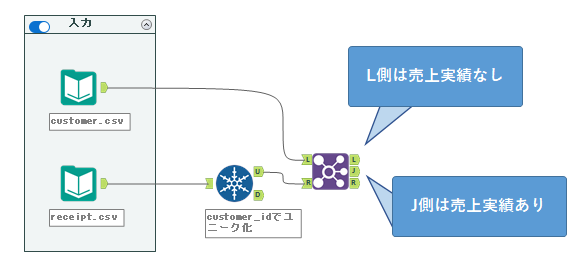
さて、ここで結合ツールの出力を見ていきます。R入力から入ってきたデータは売上実績があったものなので、customer_idがマッチしたJ出力のデータは売上実績があったものとなります。L出力側はマッチしなかったため、売上がなかったものとなります。
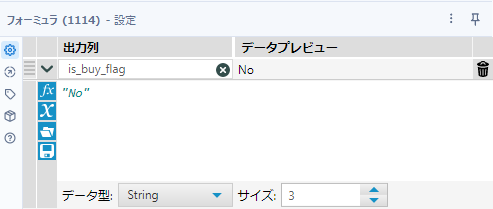
ここでデータにラベルを付けていきましょう。まず、J出力の方にフォーミュラツールを接続します。こちらは売上実績ありなので、フィールド名は「is_buy_flag」とし、値は「”Yes”」とします。データ型は文字列型(String、サイズは3)としています。

続いて、L出力にもフォーミュラツールを接続します。こちらは売上実績なしなので、フィールド名は「is_buy_flag」とし、値は「”No”」とします。データ型は文字列型(String、サイズは3)としています。
それぞれのデータストリームにラベルがついたので、これをユニオンツールで結合しましょう。以下のようなワークフローになっていると思います。
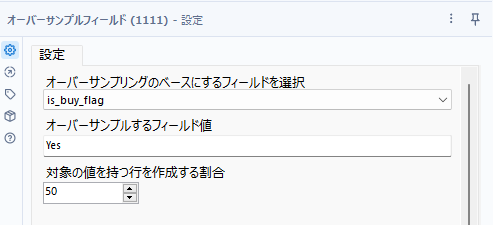
ここでようやくオーバーサンプルフィールドツールのご登場です。対象のフィールド名は「is_buy_flag」、オーバーサンプルするフィールド値は、購入実績ありのデータになるので、「Yes」を指定。対象の値を持つ行を作成する割合、については半々なので「50」とします。
基本的にこれで完了です。
参考にレコードのカウントを見ていきましょう。購入実績ありのデータは8,306件、購入実績なしのデータは13,665件。多い方の購入実績のデータがオーバーサンプルフィールドツールで削られて、最終的には全部で16,612件(それぞれのデータは半分ずつの8,306件)のデータとなります。
ちなみに、多いデータを削除するのは非常に簡単ですが、少ないデータを増やす場合どうやって増やすのか?単なるコピーで良いの?ということになり、減らすほうが簡単なので、このようにデータに偏りがある場合はアンダーサンプリングがお手軽です。
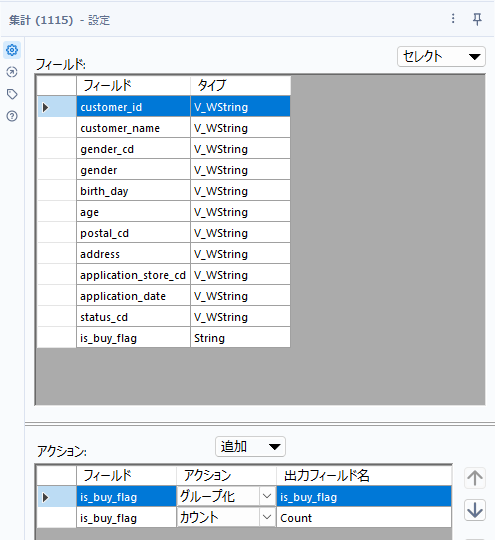
さて、最後は件数のカウントを取っていきます。集計ツールを使って、is_buy_flagでグループ化し、それぞれのカウントを計算します。
これで完了です。
まとめ
今回も予測データの前準備といった形の処理を行いました。今回はアンダーサンプリングですが、オーバーサンプリングしたければSMOTE(Synthetic Minority Oversampling TEchnique)を使う必要があり、この場合はPythonツールの出番です。

コメント