
このページは解答編です。
↓ネ
↓タ
↓バ
↓レ
↓防
↓止
答えと解説
設問はこちらでした。
P-077: レシート明細データ(receipt.csv)の売上金額を顧客単位に合計し、合計した売上金額の外れ値を抽出せよ。なお、外れ値は売上金額合計を対数化したうえで平均と標準偏差を計算し、その平均から3σを超えて離れたものとする(自然対数と常用対数のどちらでも可)。結果は10件表示せよ。
※標準偏差は、ワークフローを簡略化するためn-1で割る標準偏差を使用すること
※スケール化(標準化)すること(フィールド名はscaleとする)
解答ワークフローは以下のようになります。
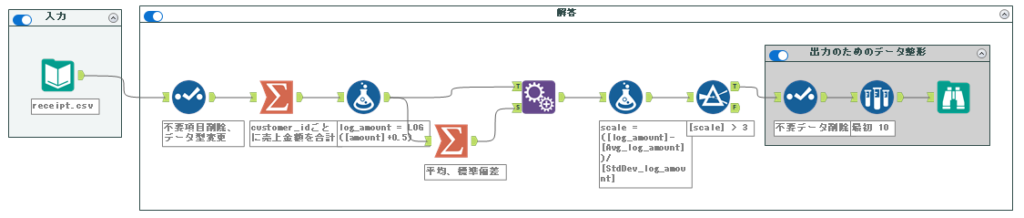
59問目で行った標準化、61,62問目で行った対数化を組み合わせて解く問題です。問題文だけ見ると、なんだかややこしそうな問題に見えますが、地道に解けばそれほどでもありません。
まず、最初に対数化を行っていく必要があります。
最初にセレクトツールを使って、集計のためにデータ型の変更と不要項目の削除を行いましょう。
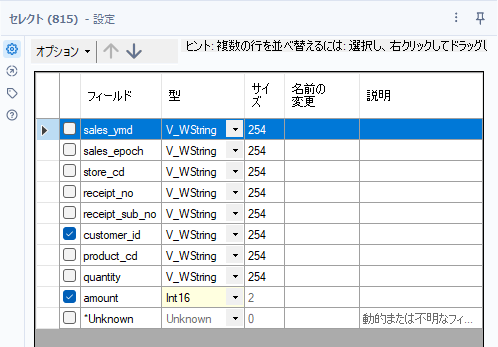
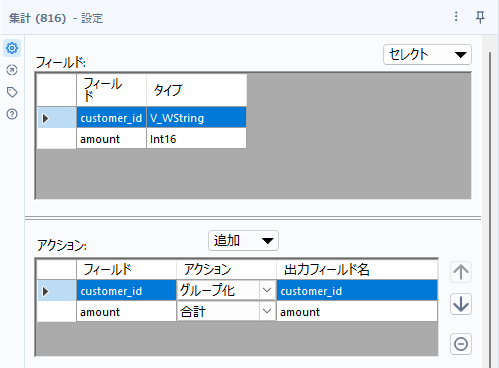
次に、customer_idごとに売上金額(amount)の合計を求めるところが最初の出発点です。集計ツールにて、customer_idでグループ化し、amountの合計を計算します。
ここで、まず対数化をしていきましょう。ここでは、自然対数(底がeの対数)を使って、自然対数化します。フォーミュラツールを使っていきますが、基本的に0はないですが、売上金額に0.5を足して対数化します。
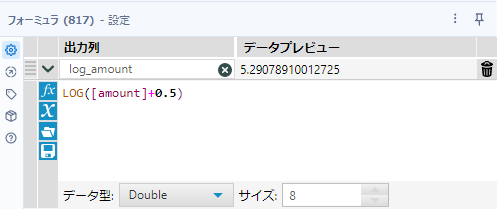
フォーミュラツールの出力アンカーのデータを①としましょう。
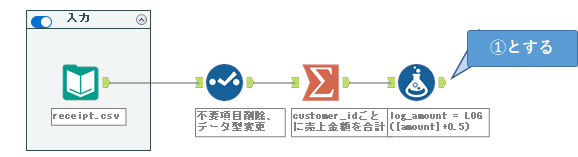
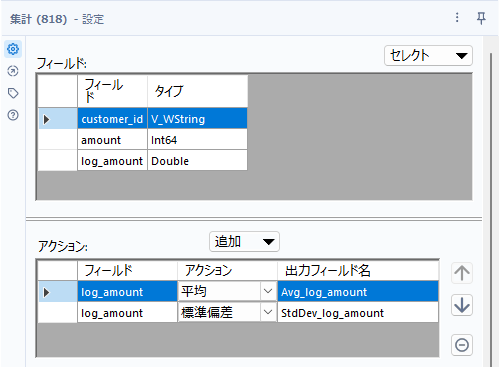
ここから、得られたlog_amountに対して平均と標準偏差を求めていきます。標準偏差はデータサイエンス100本ノックではnで割る標準偏差で計算していますが、ワークフロー簡略化のためにn-1で割る標準偏差を使っていきましょう。もちろん、ここでは集計ツールを使います。間違えて単なるamountを集計しないようにしましょう。今回はは自然対数化したamount(log_amount」です。
ここで得た値を元のデータに結合していきます。つまり、フィールド付加ツールを使用し、以下のように結線します。
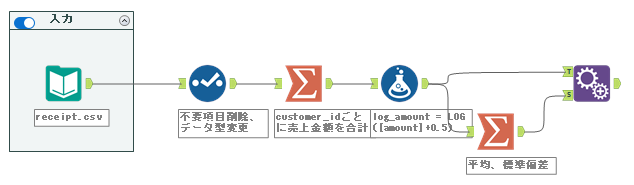
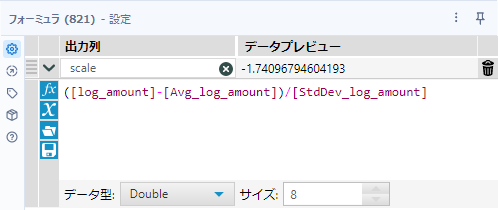
ここからスケール化(標準化)します。標準化の計算式は、59問目で行ったとおり以下のとおりです。

つまり、フォーミュラツールでは以下のようにセットします。フィールド名は「scale」、データ型は数値型(Double)です。
ここで、元の抽出条件を見てみたいと思います。
「なお、外れ値は売上金額合計を対数化したうえで平均と標準偏差を計算し、その平均から3σを超えて離れたものとする」
が、外れ値の定義でした。ここで、「σ」は標準偏差のことです。標準化することでσは1となるため、3σは3となります。つまり、scaleフィールドの値が3を超えるデータを抽出すれば外れ値の抽出ができる、ということになります。
最後にフィルターツールを使って、基本フィルターでシンプルに「>3」と設定します。
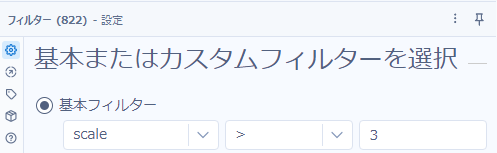
最後に不要項目を削除し、サンプリングツール等で先頭から10レコードを抽出すれば完了です(が、該当するレコードは1つのみでした)。
やることがいくつかあるので大変かもしれませんが、極端に複雑でもないので、地道にやればできたのではないかと思います。
まとめ
今回は、問題分が若干複雑で、さらに標準化、対数化といくつかやることがあったので複雑な問題に見えたかもしれません。各要素はそれほど複雑ではないので、統計を扱うときに出てくる言葉の定義など覚えながら進めていただければ幸いです。

コメント