
このページは解答編です。
↓ネ
↓タ
↓バ
↓レ
↓防
↓止
答えと解説
設問はこちらでした。
P-080: 商品データ(product.csv)のいずれかの項目に欠損が発生しているレコードを全て削除した新たな商品データを作成せよ。なお、削除前後の件数を表示させ、079で確認した件数だけ減少していることも確認すること。
解答ワークフローは以下のようになります。
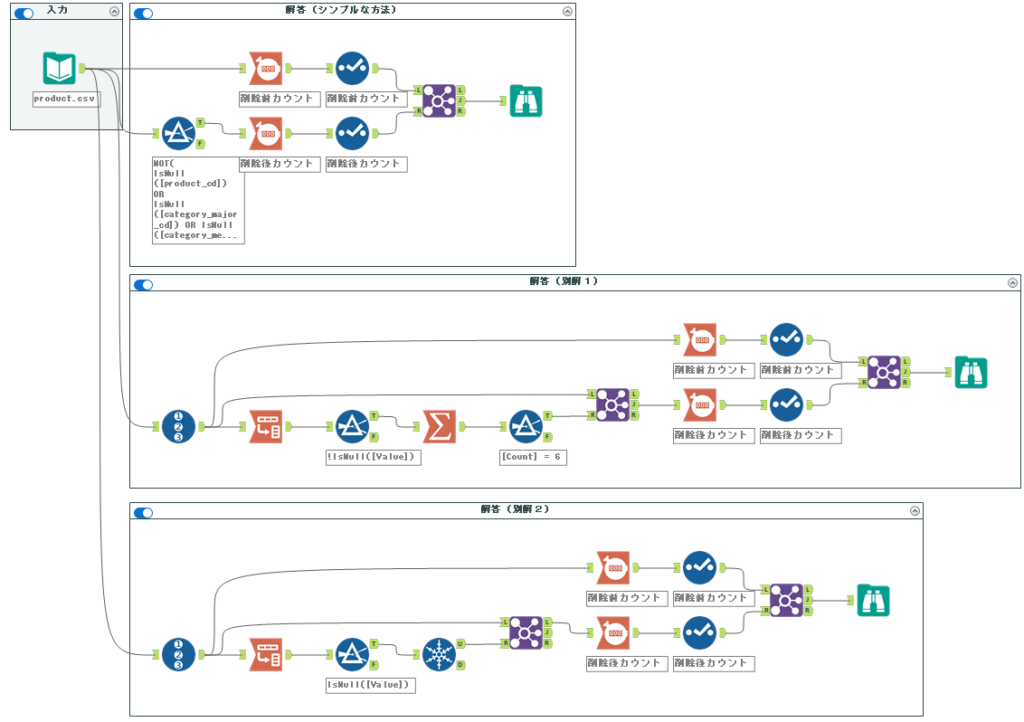
今回は、欠損値が1フィールドでも存在するレコードがあれば除外する、ということになります。
シンプルな方法
まず、シンプルにフィルターツールを地道に使っていく方法をやってみましょう。
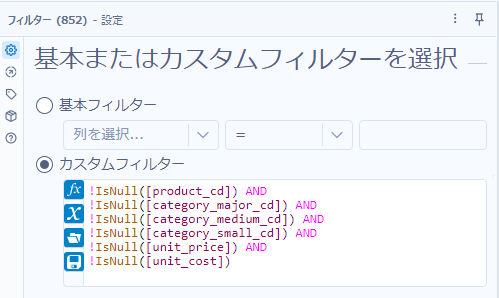
各フィールドがNullでなければ良いということなので、「!IsNull([フィールド名])」という計算式がまず使えます。これを各フィールドに対して実行し、AND条件で繋げればOKです。つまり、以下のような計算式となります。
!IsNull([product_cd]) AND
!IsNull([category_major_cd]) AND
!IsNull([category_medium_cd]) AND
!IsNull([category_small_cd]) AND
!IsNull([unit_price]) AND
!IsNull([unit_cost])フィールド数が多いとなかなかめんどくさいです。
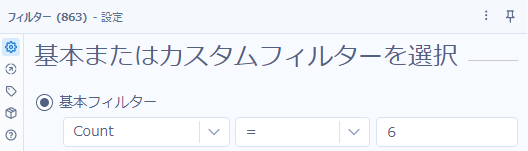
これをフィルターツールのカスタムフィルターで表現しましょう。
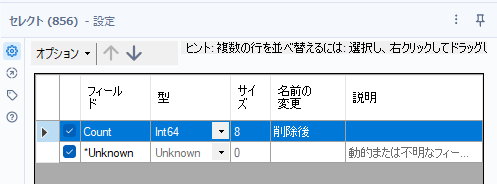
あとは、レコードカウントツールでカウントを取り、セレクトツールでフィールド名を「削除後」と変更します。
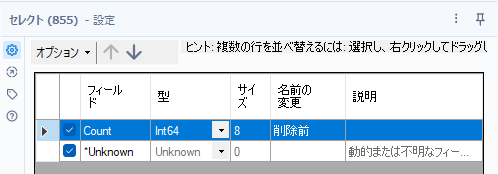
また、削除前のカウントは、product.csvの直後にレコードカウントツールを接続し、さらにセレクトツールでフィールド名を「削除前」とします。
これらを結合ツールで結合します。オプションとして、「レコードポジションで結合」で結合します。
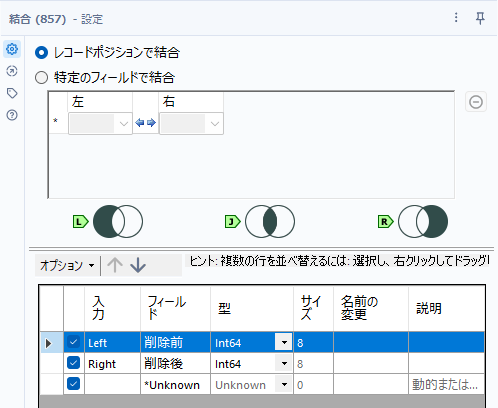
このオプションは、レコードの先頭からの位置が同じものを横に並べていきます。
これで完了となります。実際のワークフローは以下の通りとなります。
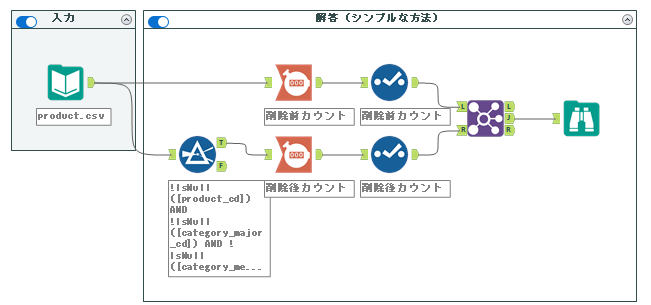
シンプルではありますが、フィルターツールの設定の際に、フィールド数が多いと非常に大変です。
別解1:動的にやってみる(Nullがないもののみにする)
次に、各レコードを一度縦持ちにした後、フィルターでNullを除外した後、各レコードのカウントを取ると、Nullではないフィールドの数が得られます。これが全体のフィールド数より少ないレコードを除外する、という方法になります。
まず、最初に各レコードが何行目に位置するのか、IDをつけます。これにはレコードIDツールを使います。
次に、RecordIDフィールド以外すべて縦持ちにします。これには、転置ツールを用います。
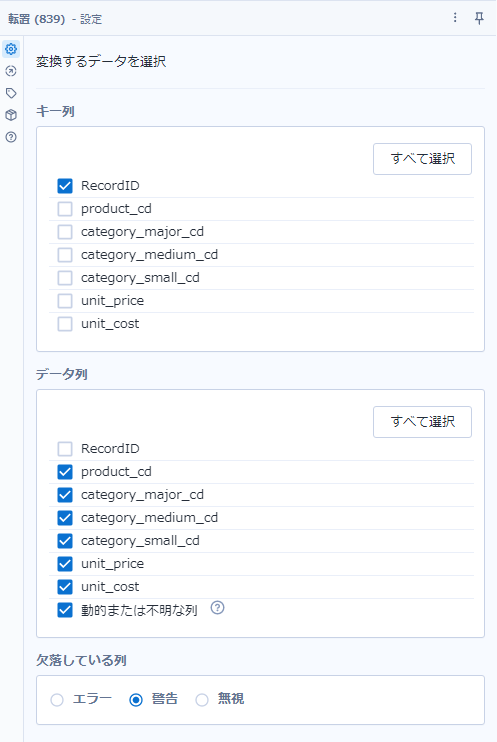
これで、各フィールドが縦持ちになる(キー列とした「RecordID」以外に、「Name」「Value」という2つのフィールドで構成されるようになります)ので、「Value」列からNullをフィルターツールを使って取り除きます。
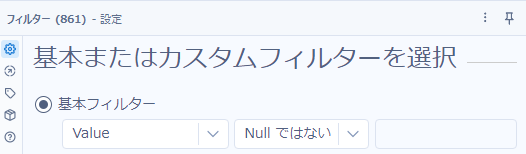
これにより、今回であれば元々6フィールドあったので、各RecordIDに対して6レコードずつ生成されていると思います。ただ、Nullを除外しているので、6レコードにならないRecordIDが出てきます。今回は、6レコード揃っているRecordIDを特定し、元々のデータストリームのRecordIDと合致させれば欲しいデータが得られます。
つまり、まず各RecordIDでグループ化してカウントを取ります。

このカウントが6個ずつあるものだけ抽出します。実はこのやり方はここだけ動的ではありませんが、今回はこのままにしておきましょう。動的に行う方法を考えてみていただければと思います。
ここからレコードIDツール直後のデータと結合します。この場合のキーフィールドはRecordIDフィールドです。
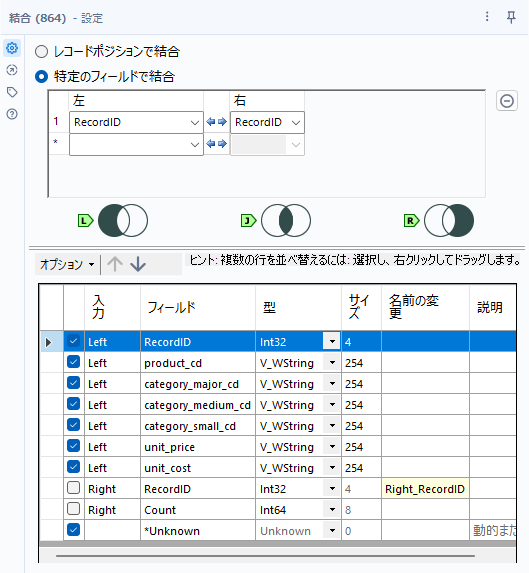
ここでは、右側から来たデータは不要なのでチェックをはずします。
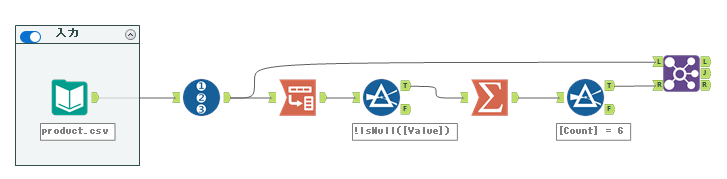
この段階では上のようなワークフローとなっています。
この結合ツールのJ出力に、レコードカウントツールとセレクトツールを接続することで、削除後のカウントが得られます。

後は、削除前のカウントを取れればいいので、レコードIDツール以前であればどこに接続しても良いのですが、レコードカウントツールでカウントを取り、さらにセレクトツールで名称を変更します。
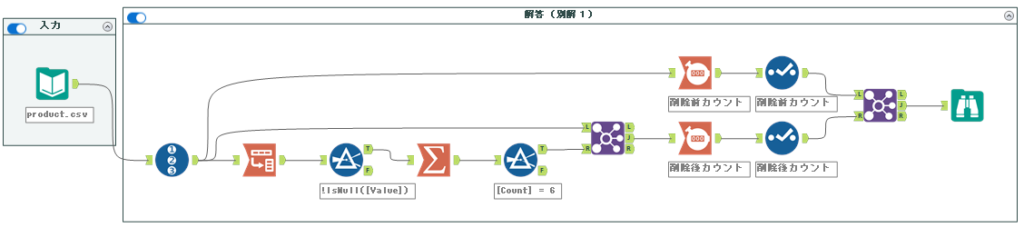
最終的なワークフローは以下の通りとなります。
別解2:動的にやってみる(Nullが発生しているものを除外)
次に、別解1と似た手法で別のやり方でやってみましょう。
前回は、Nullがないレコードを残す、という方法でしたが、今度はNullがあるレコードを除外する、という方法になります。なお、途中までは別解1と同じです。
まず、最初に各レコードが何行目に位置するのか、IDをつけます。これにはレコードIDツールを使います。
次に、RecordIDフィールド以外すべて縦持ちにします。これには、転置ツールを用います。
これで、各フィールドが縦持ちになる(キー列とした「RecordID」以外に、「Name」「Value」という2つのフィールドで構成されるようになります)。
ここまでは別解1と同様ですが、ここから異なるアプローチを取っていきます。
今回は、「Value」列でNullがあるもののみフィルターツールを使って抽出します。後にNullがあるRecordIDのレコードのみ結合ツールで除外していくためです。
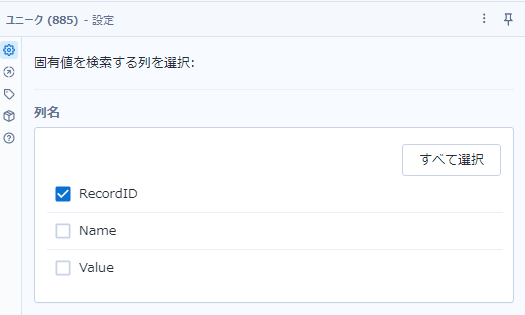
ここでユニークツールを使って重複するレコードを除外します。実はユニークツールを使わなくても結果は同じです。ここではRecordIDフィールドに対してユニークを取ります。
ここからがポイントですが、結合ツールを使っていきます。L入力側はレコードIDツールの出力アンカーから接続します。R入力側は上のユニークツールの出力アンカーとなります。つまり、以下のようになります。
設定は以下の通り(別解1の結合ツールと設定は同じです)。
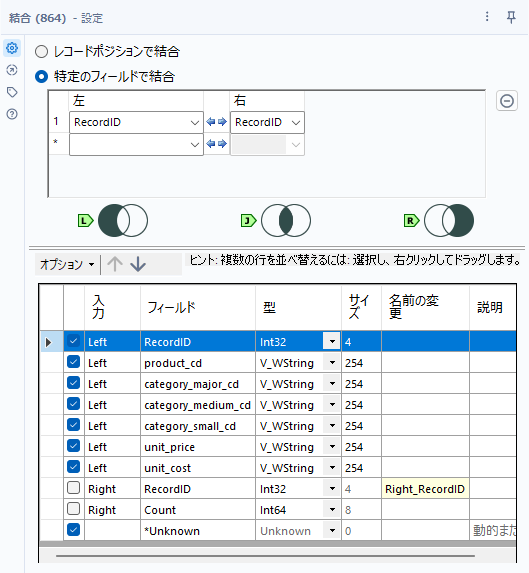
さて、このJ出力に出てきているデータはなんでしょうか?Nullを持つレコードと結合しているので、Nullが存在しています。つまり、削除対象のレコードです。逆に、Nullを持たないレコードはどこに出てきているのか?正解はL出力です。
参考に、J出力の結果を見てみると、以下のようにNullが存在しています。

ここからL出力にレコードカウントツールを接続し、セレクトツールで名前を変更していきます。
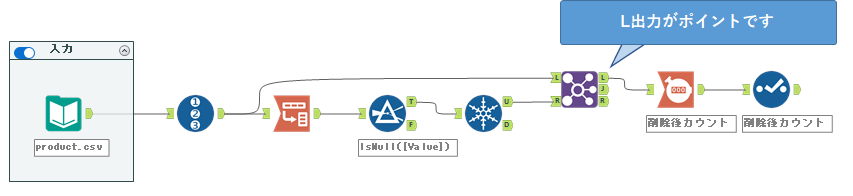
後は、別解1と同じように削除前カウントを取り、結合して終了です。最終的なワークフローは以下の通りとなります。
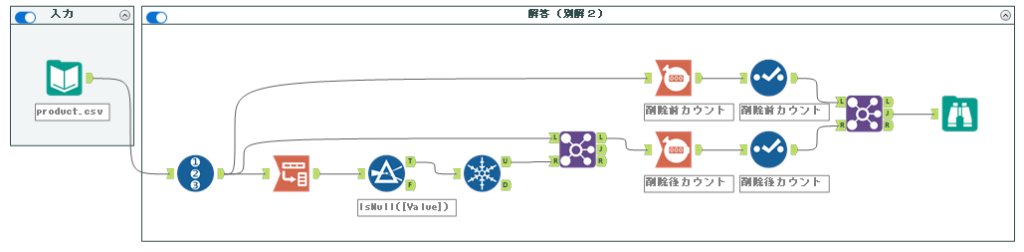
素直に行うなら、すべてのフィールドがNullがないという前提で進める別解1が本道に見えますが、実はNullがあればNGという別解2の方がツールも少なく処理できる、というところが工夫のしがいがあるところです。
まとめ
今回は欠損値が1つでもあるフィールドを除外するという問題でした。1行すべてがNullなら削除、ということであればデータクレンジングツールが使えるのですが、一部のみということであれば地道に行うしかありません。
実際のデータ加工でも、別解2のパターン(除外リストを作成し、結合ツールで取り除く)は比較的よく使うので、活用してみてください。

コメント