
このページは解答編です。
↓ネ
↓タ
↓バ
↓レ
↓防
↓止
答えと解説
設問はこちらでした。
P-092: 顧客データ(customer.csv)の性別について、第三正規形へと正規化せよ。
※正規化後のテーブルは先頭から10件を抽出すること
解答ワークフローは以下のようになります。
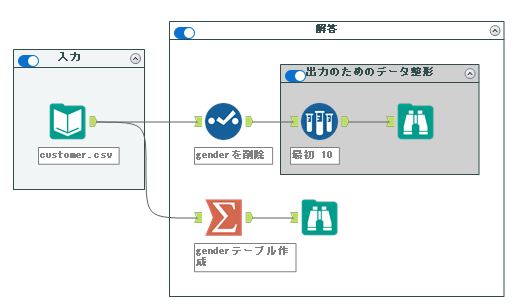
今回もリレーショナル・データベースで標準的に行われている正規化を行う問題です。
正規化とは
リレーショナル・データベースは、データを管理しやすくするため、関連する項目でまとめられた複数のテーブルで作成されていることが多いです。これらのテーブルは「正規化」されています。
例えば、今回の問題であれば、customer.csvにはgenderとgender_cdというフィールドがありますが、gender_cdが決まればgenderは一意に決定されます(例えば、gender_cdが0であれば「男性」であることが決まっています)。
customer.csvから見れば、gender_cdさえあればgenderは特定できます。そのため、genderはある意味不要です(いつでもgender_cdとgenderの対応表が参照できれば)。
このように、別々にできるテーブルはなるべく別々にしたものが、第3正規化となります。
逆に、元々のcustomer.csvは第2正規化されたテーブルといえるでしょう。
ちなみに、第1正規化というのは、1つのレコードに一つの行しかない状態が第1正規化です。
逆順に解説しましたが、改めて流れを追って説明してみたいと思います。
第1正規化
以下は正規化されていないテーブルです。

これは、まず1つの行に複数のデータが入っているようなケースがあります。つまり以下の赤い部分のような状態です。データベースは1行に1データと決まっていますので、これでは具合が悪いです。

1行に1データという形にしたものが、以下のテーブルになります。

これが第1正規化となります。
第2正規化
次に、第2正規化です。第2正規化の定義としては、部分関数従属している列を整理するということです。
先程のテーブルは、左側の顧客情報と右側の販売情報の2つからできています。つまり以下のイメージです。

右側の部分にcustomer_idをつけてしまえば2つのテーブルに分割することが可能です。つまり以下のような形になります。

これが第2正規化です。右側の販売情報のうち、顧客情報はcustomer_idによって判別が可能です。このような関係は部分関数従属と呼ばれています。
第3正規化
第3正規化は、関数従属している列を整理します。
よくよく見ると、左側のテーブルは、gender_cdとgenderと1:1関係になっているものがあります。つまり、まだテーブルに分解できるものがある、ということです。このようなものをすべてなくしていきましょう。

これをさらに分割すれば以下のようになります(左側に着目していましたが、右側のテーブルも正規化可能です)。

実際のワークフロー作成
それでは実際のワークフローを作っていきましょう。
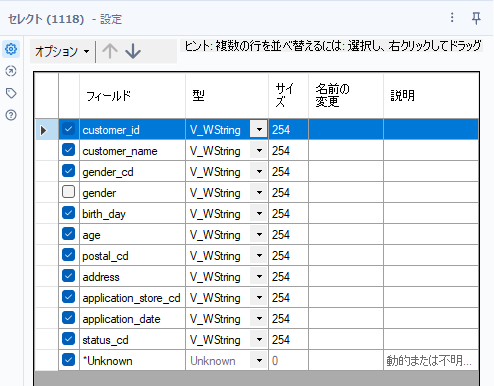
まず、genderはgender_cdがあれば判別つくので、genderをcustomer.csvから削除しましょう。セレクトツールで簡単に削除可能です。
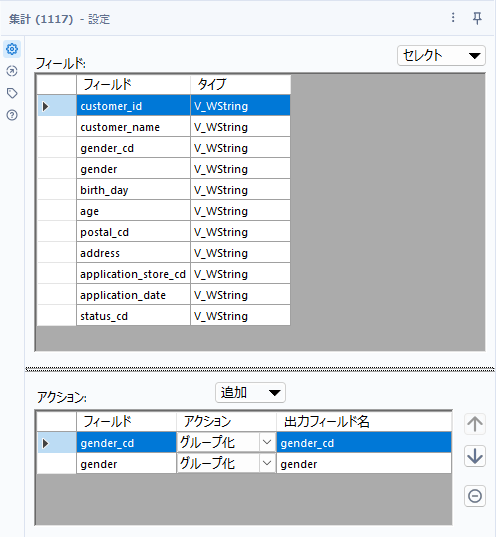
次に、customer.csvからgenderテーブルを作っていきます。単純にgender_cdとgenderの関係性がわかるテーブルができれば良いだけなので、この2つの項目でユニークなものが取れればOKです。
つまり、集計ツールを使うのであればgender_cdとgenderそれぞれでグループ化すれば良いです。
元のテーブルの方は、サンプリングツールなどで先頭から10レコード抽出すれば完了です。
まとめ
今回は正規化を行う問題でした。何かしら自動的にできれば良いのですが、よくテーブルの状況を見ながら作成する必要があります。ただし、子テーブルを作成する際は、集計ツールでグループ化すれば良いだけですので、難しくはありません。

コメント