
※過去記事はこちら。AlteryxユーザーのためのAdvent of Codeの始め方、1日目、2日目
3日目です。
タイトルは「Rucksack Reorganization」、リュクサックの再編成、とのこと。
3問目は、Part2のところでちょっとまたもや英語で惑わされましたが、それを除くと比較的素直な問題かと思います・・・。
今回は、文字列の中に共通して出現する文字をある組み合わせから抜き出し、文字に合わせてポイントを付与し、合計を取るというのが共通した内容です(問題文としては、リュックサックがありその中にものが入っている、というストーリーですが・・・)。
入力データとしては、以下のようになっています。
vJrwpWtwJgWrhcsFMMfFFhFp
jqHRNqRjqzjGDLGLrsFMfFZSrLrFZsSL
PmmdzqPrVvPwwTWBwg
wMqvLMZHhHMvwLHjbvcjnnSBnvTQFn
ttgJtRGJQctTZtZT
CrZsJsPPZsGzwwsLwLmpwMDwPart1では、各行の前半と後半にそれぞれ分割し、前半と後半で一致する文字を抜き出します(必ず1文字のみが一致します)。つまり、1行目であれば前半の「vJrwpWtwJgWr」と「hcsFMMfFFhFp」に分割でき、一致する文字は赤で色付した「p」です。
Part2では、3行をひとまとまりとして、その中で各行にそれぞれ一致する文字が1文字のみある、ということになっています。
vJrwpWtwJgWrhcsFMMfFFhFp
jqHRNqRjqzjGDLGLrsFMfFZSrLrFZsSL
PmmdzqPrVvPwwTWBwg上のリストであれば、赤で色付けした「r」となります。
文字列に対してのポイントとしては、小文字のアルファベットa~zはそれぞれ1~26ポイントが与えられます。大文字A~Zは、それぞれ27ポイントから52ポイントとなります。これはPart1,2共通のシステムです。
最終的に抽出したアルファベットの点数の合計を取ります。
・ネ
・
・タ
・
・バ
・
・レ
Part1を解いてみる
今回のよう問題は、文字列をばらして結合することで一致する文字を探していく必要がありますが、文字列をばらす際に、文字数が一定ではないので縦方向にばらすのが普通です。その際に元々のデータがばらばらになってしまうため、それを防ぐためにIDをつけるのが通常のやり方です(レコードIDツールを最初に使っていきます)。
前半後半に分割するのは、Left関数、Right関数を文字列の長さの半分でやってしまうのが手っ取り早いと思います。
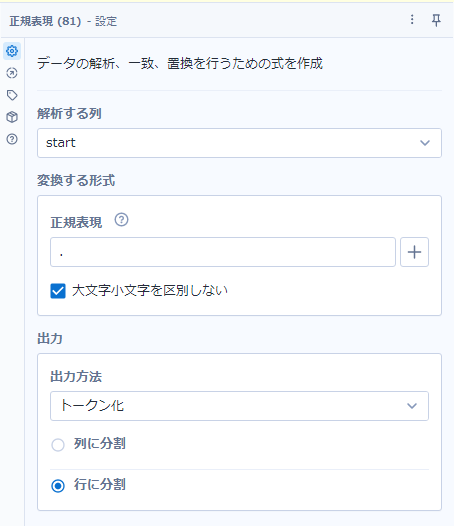
一番の問題の文字列を1文字ずつ分割する方法ですが、これは覚えておいてほしい方法ですが、正規表現ツールをトークンモードで使います。このとき、正規表現のパターンとしては「.」(ドット)のみとなります。そして出力方法は「行」となります。つまり以下のような設定です。
これはAoCではちょくちょく使う手法です(普通のデータ整理ではあまり使わないと思います)。
さて、これ前半と後半両方必要なのでそれぞれで行い、レコードIDと文字列で結合すれば欲しいアルファベットが抽出されます。
あとは得点ですが、手動でアルファベットと得点の表を作っても良いですし(めんどくさいですが)、正直Excelでぱぱっと作った方が手っ取り早いかもしれません。
今回は、行生成ツールを使っています。これで1~52までの数字を生成し、その後フォーミュラツールにてCharFromInt関数を使ってアルファベットに変換します。つまり以下のような関数を使っています。
IF [Point]<=26 THEN
CharFromInt([Point]+96)
ELSE
CharFromInt([Point]+38)
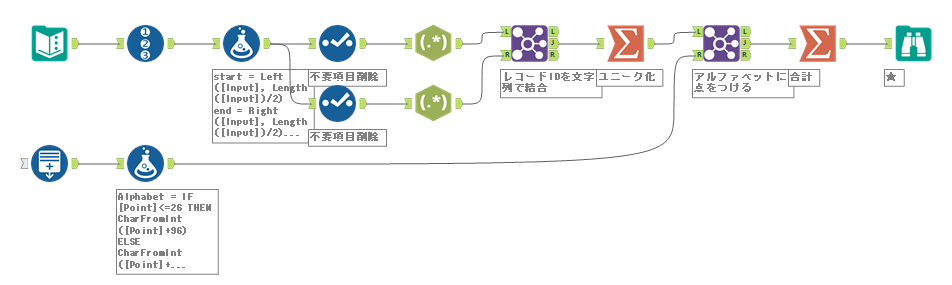
ENDIFワークフローとしてはこちらのような形です。
Part2を解いてみる
Part2も基本的なやり方はほぼ同じです。今までは同じ行の中でマッチングを取りましたが、Part2は3つのマッチングを取る必要があります。また、3行ごとにグループ化する必要があります。
今回はグループ化にタイルツールを使いました(複数行フォーミュラでも可能です)。今回インプットデータは全部で300行あるので、3行ごとにグループ化するにはタイルの数を100にすればオッケーです
その後インプットデータを文字ごとに分割します。先程の正規表現ツールを使った手法で行います。
あとは、フィルターツールを使ってTileSequenceNumごとに3行を個別のデータストリームにし、複数結合ツールで結合していきます。これは、結合条件としては、Tile_Num(グループ番号)と個別の文字列とすることで、3つの行でマッチングした文字列のみが抜き出されます。
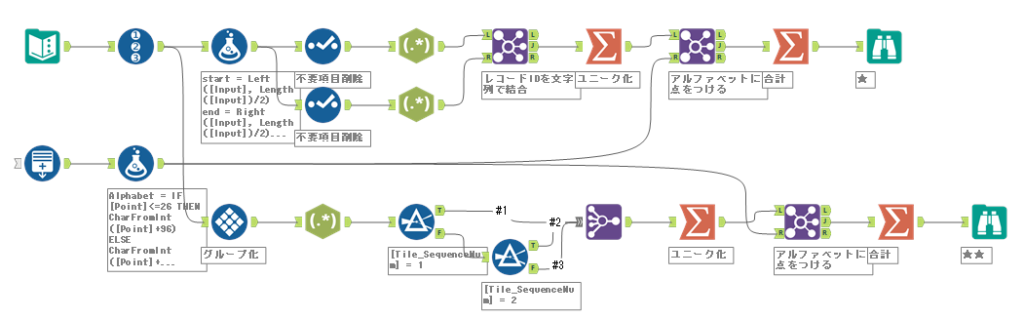
あとは、抽出した文字をユニークにして得点を付与して合計を取ったら完了です。ワークフローとしては以下の通りとなります。
ところで、このグループ化から結合まで正直若干冗長に感じますが、これを解決する方法があります。ラボラトリーというカテゴリにひっそりと佇むツール「列作成」ですが、これはアレンジツールの逆ができるツールです。元ACEで現AlteryxのNicole Johnsonがよく使っているのを知っていたのですが実はあまり使い所がわかっておらず、だったのですが、今回も彼女が使っていたので使ってみました。
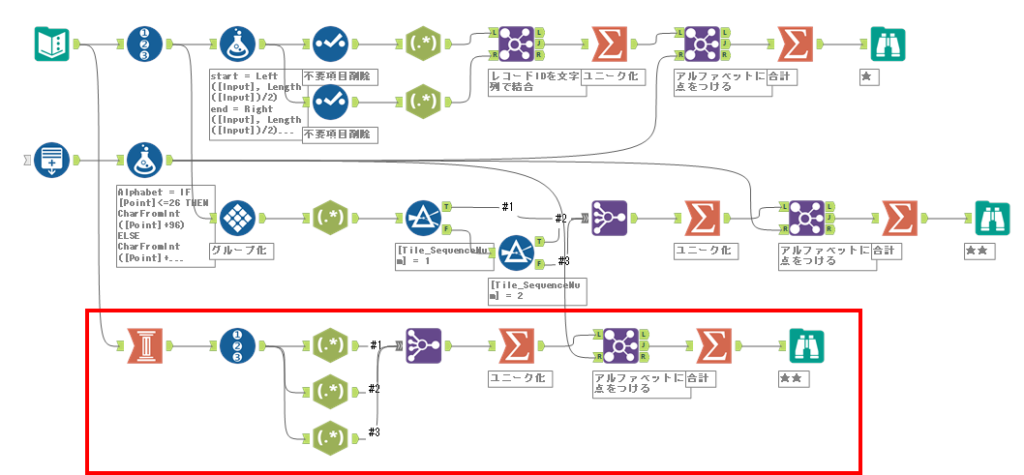
これいいですね・・・。非常にすっきりしたフローになりました。なぜ未だにラボラトリーカテゴリなのかわかりません(フラットファイルのデータ成形などには使えそうな気がします)。
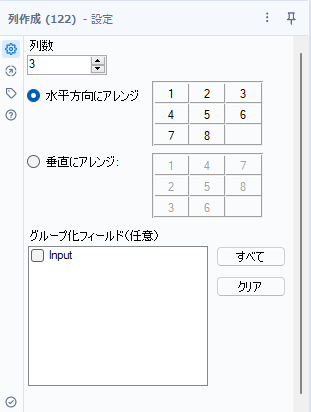
設定は以下の通り、縦に並んでるのを横に指定列並べて次の行に行く、といった感じになります。
つまり以下のようになります。
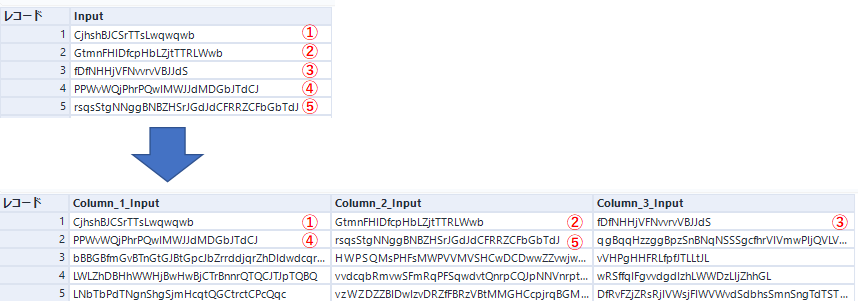
今回のようなケースにはぴったりのツールです!
まとめ
- 3日目はよくあるデータ成形の問題でした。
- 最速の人でも16分程度かかっていますが、早くて20分くらいで解けているようです。
- 個人的には、Part2でちょっと迷いました。全体から一つだけ一致するのがある?と誤解していたところでロスしました・・・。頭から3つなら全然もっとさくっといけたのに・・・。
- 個人タイム:Part1 12分18秒、Part2 27分21秒

コメント