WEB上のリソースを取得する場合、API(RestAPI)が提供されている場合はそちらを使うことで安定して情報の取得が可能ですが、APIが提供されていない場合はスクレイピングを行う必要があります。
世間一般的にはPythonでBeautifulSoupなどを使ってスクレイピングするのが一般的かと思いますが、Alteryxの場合はどうするのか、ご紹介したいと思います。
AlteryxでWEBスクレイピングを行う方法
基本的にはダウンロードツールを最初に使います。ダウンロードツールでWEBページにアクセス(ローカルにファイルとして落とす)し、その後は正規表現ツール等を使って必要な情報を得ていく、というのがAlteryxでのスタンダードな方法となります。
ダウンロードツール

ダウンロードツールはWEBへアクセスする機能を提供します。APIを呼び出す場合もこのツールを使いますが、WEBスクレイピングを行う場合はもっとシンプルに使うことができます。
基本的にはテキスト入力ツールやデータ入力ツールにアクセス先のURLを記載しておき、そのデータをダウンロードツールに入力していきます。ログイン等が必要でなければそのままデータがダウンロードされてきます。例えば、以下のようなワークフローになります。
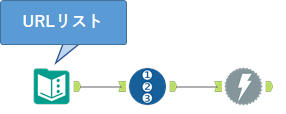
ダウンロードツールの設定は以下のようになります。基本的には「URL」の「フィールド」にアクセス先のURLが格納されたフィールドを指定するだけです。
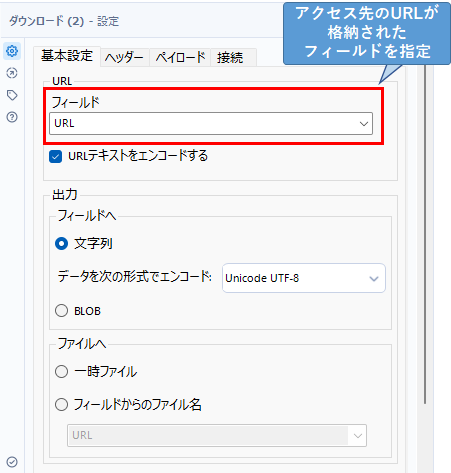
アクセスするURLが画像などのバイナリファイルの場合は、「出力」の「フィールドへ」で「BLOB」を選択します。通常のホームページの場合は、「文字列」でオッケーです。
正規表現ツール

正規表現ツールは、文字列から欲しいデータをパターン一致させ抜き出すツールです。非常に強力なツールではありますが、「正規表現」と呼ばれる記法を理解する必要があります。この記法に慣れるのに若干時間がかかるため、初心者には若干ハードルが高いツールとなっています。しかしながら、そのハードルを超えると非常に簡単に欲しい物が得られるようになるため、使いこなすことができるようになったときのリターンが非常に大きいツールです。
なお、正規表現はフォーミュラツールでも利用可能ですが、WEBのスクレイピングでは正規表現ツールを使った方が圧倒的に楽です。
実際に試してみる
それでは、簡単なデータの抽出を行ってみたいと思います。
今回は、Alteryx CommunityのウィークリーチャレンジのIndexページから各チャレンジのリンクを抜き出してみたいと思います。
テキスト入力ツールに「URL」というフィールドを作成し、先程のウィークリーチャレンジのIndexページのURLを貼り付けます。その後ダウンロードツールに「URL」フィールドを設定することでデータ(HTMLページ)をダウンロードすることができます。このデータから正規表現ツールでURLだけ抜き出してくるわけですが、まずそこまでのワークフローは以下のとおりです。
ダウンロードツールでダウンロードすると、「DownloadData」「DownloadHeaders」というフィールドが自動的に作成され、「DownloadData」に情報が格納されます。また、「DownloadHeaders」はHTTPアクセスを行った際のヘッダ情報が格納されます。このヘッダ情報にはアクセスして問題なかったかどうか、という情報が格納されています。エラー検知などを行う場合はこの「DownloadHeaders」を参照していきます(今回は301が出ており、リダイレクトされていますが、その先で「HTTP/1.1 200 OK」となっているので問題ありません。エラー検知は「200 OK」が出ていれば問題なし、という判定で良いと思います)。

なお、この「DownloadHeaders」と「URL」フィールドはもう使わないのでセレクトツールで削除しています。なお、複数のURLに一度に接続する場合はレコードIDツールなどで行番号を入れておくことをオススメします。また、同じサーバーに対して大量にアクセスする場合、スパム行為とされる場合があるため、ダウンロードツールのオプション設定で速度を絞ることをオススメします。
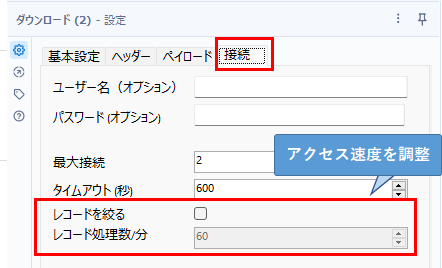
具体的には、上のように「接続」タブにて「レコードを絞る」にチェックをつけ、「レコード処理数/分」のオプションを適切に設定します。
さて、いよいよURLを抽出していきますが、だいたいこのデータの抽出作業は試行錯誤を行っていくことになると思います。その際、毎回ホームページの情報を取りに行ってると時間がかかるため、セレクトツールのところで右クリックメニューから「ワークフローのキャッシュと実行」を行っておきましょう。
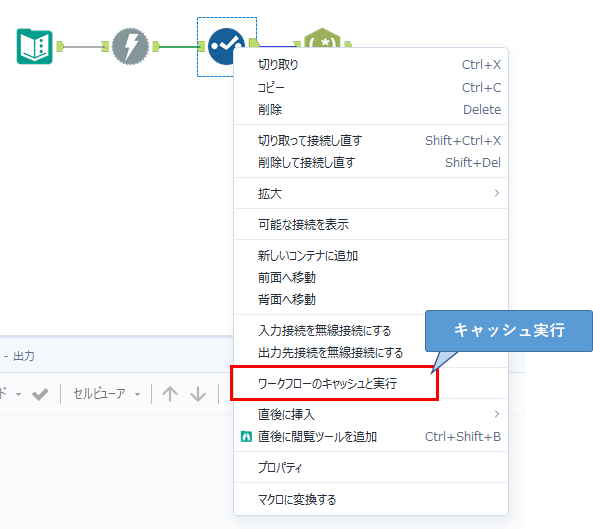
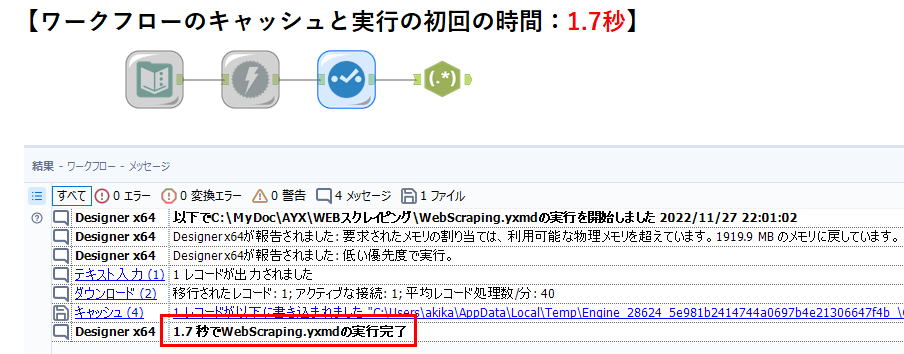
実際の比較結果を載せておきます。まず、ワークフローのキャシュと実行の初回時(つまりキャッシュを作成時)の時間は以下のとおりです。
こちらが、キャッシュができて以降の時間です。
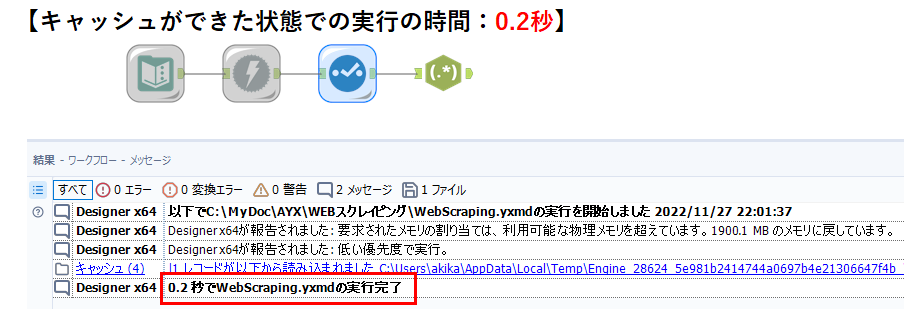
1.7秒が0.2秒になっていますが、例えば、10個のURLに接続すれば、17秒かかるところが、キャッシュで2秒なので、全く待ち時間が異なります。
さて、ここから正規表現ツールの設定を行います。URL(リンク)は、httpで始まり、「”」(ダブルクオテーション)、半角空白、’(シングルクオテーション)等で終わる形で書かれています。例えば、先程のウィークリーチャレンジのIndexページのソースを見ると以下のように書かれています。
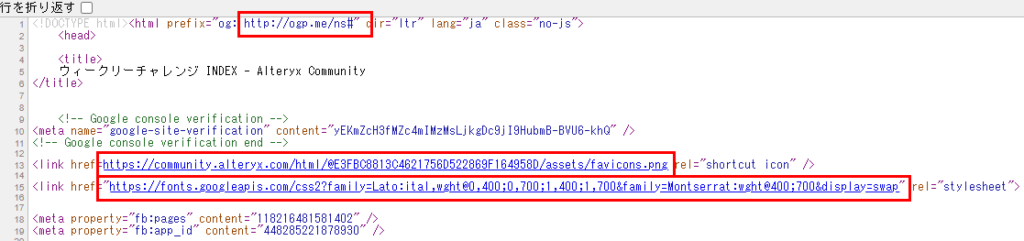
これを正規表現で書くと、以下のように表記できます。
https?://[^\"'\s]*この式を正規表現ツールに設定していきます。設定画面は以下のようになります。
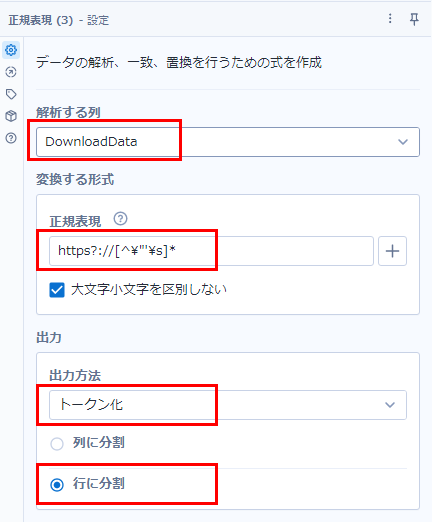
「解析する列」は「DownloadData」。
「正規表現」は先程の式の通り。
出力方法は、複数ヒットするものがあるので「トークン化」を選びます。トークン化にすると、正規表現のパターンに一致した全てのデータを抽出することが可能です。
また、いくつあるのかわからないため、「行に分割」を選択します。
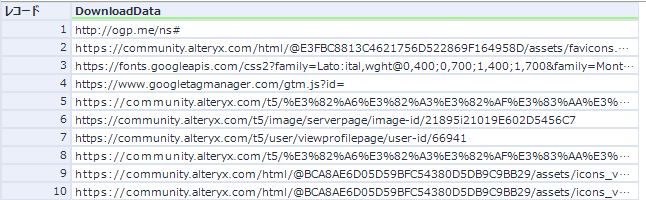
このトークン化で一気にデータを抽出するために、フォーミュラツールを使わず正規表現ツールで行っています。これにより、以下のようにデータが抽出されます(先頭から10レコードのみ表示)。
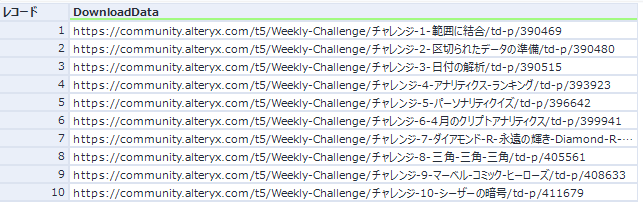
ちなみに、このホームページは各チャレンジへのリンクが全て載っているため、フィルターツールで「チャレンジ」を「含む」ものを抽出すると全てのチャレンジへのリンクが入手できます。
まとめ
このような形で簡単に欲しいデータを抽出することができました。正規表現とHTMLの書式に慣れる必要はありますが、正規表現でもHTMLから情報を抜き出したり加工したり、といった式はインターネット上で検索すると色々と見つかるので1から式を組まなくてもなんとかなると思います。
例えば、HTMLタグがじゃまな場合は、
<("[^"]*"|'[^']*'|[^'">])*>といった式で置換すれば簡単に削除することができます。これもインターネット上の検索で簡単に手に入ります。
テーブルデータからデータを抜き出すような場合はもう少し工夫が必要ですが、基本的に正規表現ツールなどを駆使して行います。

コメント