
Alteryx Predictive Master資格取得を目指すシリーズです。
Alteryxの予測カテゴリに配置されているモデルについて解説していきます。
今回は分類・回帰両方できる「サポートベクターマシーン(Support Vector Machine)」について解説していきます。
SVM(サポートベクターマシーン)概要
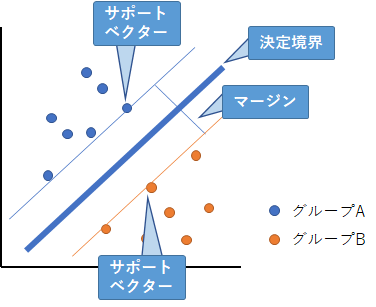
サポートベクターマシーンは、主に分類向けのモデルです。データを分類する超平面を見つけますが、最も近いデータ点との距離(マージン)を最大化するように作成します。マージン内には基本的にデータはないこととしていますが、ソフトマージンという考え方で、ある程度の誤分類を許容しています。
また、サポートベクターマシーンは、非線形のデータでも分類できるよう、カーネル関数を利用して特徴量を高次元に変換(マッピング)することで簡単に分類できるようにしています。
長所は以下のとおりです。
- 少ないデータでも対応可能(精度が出せる)
- 過学習に強い
- 他のアルゴリズムで難しい分類ができる
- カーネル関数を変えることで、様々なモデルを構築できる
欠点は以下のとおりです。
- 計算コストが高い(大量のデータになるとメモリ、実行時間面で厳しくなる)
- 微調整が必要
サポートベクターマシーンは、データをスケーリングしたほうが良いモデルです。正規化もしくは標準化することをおすすめします。
設定
必須パラメーター
必須の設定としては、モデル名の決定、ターゲットフィールドの指定、予測変数の指定となります。また、実行したい内容が回帰か分類かは、SVMは自動的に決めません。手動で指定する必要がありますが、デフォルトでは分類となっているのでご注意ください。
メソッドが分類の場合
メソッドはいくつか選択可能です。分類と回帰で分かれていますがまず分類の設定を見てみましょう。
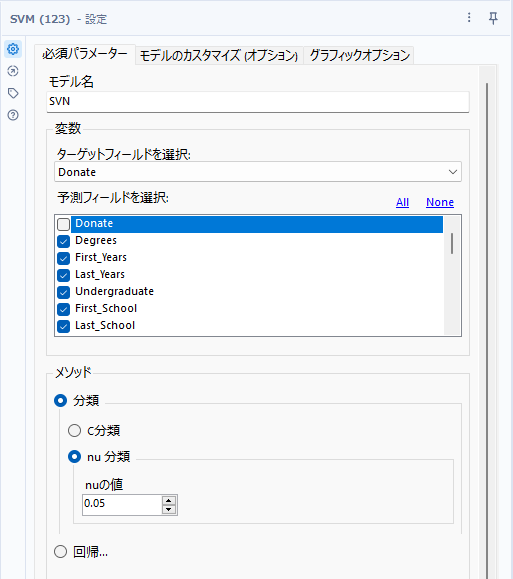
分類は、C分類とnu分類の2つが利用可能です。
C分類
多少の誤差を許容しながら識別平面を最適化します。Cパラメータは、モデルのカスタマイズでカーネルタイプとともに指定することができます。Cパラメータは小さい場合は誤分類を許容します。大きくすると複雑に分類できるようになりますが、汎化性能が下がる可能性があります。
nu分類
C分類と同様だが、nu値を選択して誤差の大きさを制限可能。デフォルトは0.05ですが、0.01~1の間の値を取ることができます。
メソッドが回帰の場合
回帰は以下のとおりです。
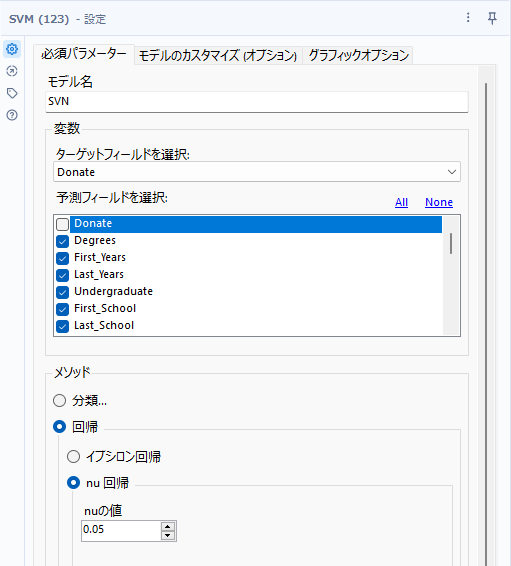
回帰は、イプシロン回帰とnu回帰から選択可能です。
イプシロン回帰
nu回帰
こちらもnu値を選択して誤差の大きさを制限可能。デフォルトは0.05ですが、0.01~1の間の値を取ることができます。
モデルのカスタマイズ
モデルのカスタマイズは、デフォルトでは何もチェックが入っていません。
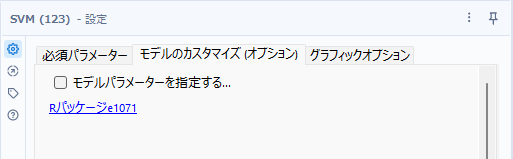
一度チェックを入れると、以下のようになります。大きく分けると、「ユーザーがパラメーターを提供する」か「マシンチューニングパラメーター」から選択が可能です。いずれもぼ「カーネルタイプ」とそれに付随するパラメータの選択が主となります。
ユーザーがパラメータを提供する
完全に手動です。カーネル関数のタイプとパラメータを指定します。
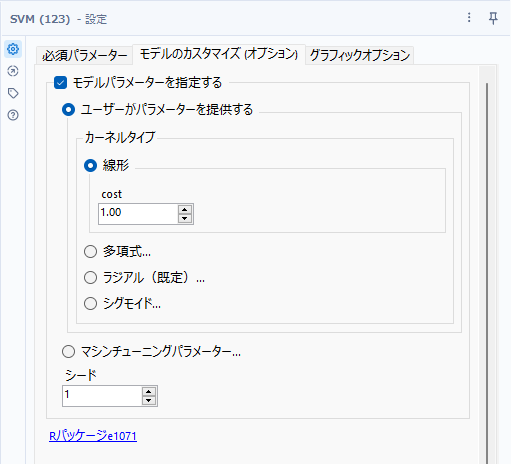
指定可能なカーネルタイプとパラメータは以下のとおりです。
- 線形(linear)・・・クラスと予測変数間の関係が単純な線、平面、超平面である場合に利用できます
- cost
- 多項式(polynomial)・・・距離を、予測変数の多項式関数を用いて測定します
- cost
- degree
- gamma
- coef0
- ラジアル(規定)(radial)・・・非線形に分離可能なデータ向き
- cost
- gamma
- シグモイド(sigmoid)・・・ニューラルネットワークのプロキシとして利用されます
- cost
- gamma
- coef0
それぞれのカーネル関数のパラメータについては以下の通りとなります。
- cost・・・Cパラメータ。デフォルトは1。0.01~10,000の間の値を取ります。小さくすると誤差を許容します。大きくすると細かく分類を行いますが、その分汎化性能は下がります。
- degree・・・多項式の次数。次数を増やすとグループ間のマージンがより柔軟になります。ただし、過学習する可能性が増えます。デフォルトは2。0.001~5の間の値を取ります。
- gamma・・・1つの訓練データをどれだけ重要視するか(多項式では内積項の係数、ラジアルではべき乗項の係数)。デフォルトは1。0.0005~10,000の間の値を取ります。
- coef0・・・多項式・シグモイドの定数項。デフォルトは1。0.01~10,000の間の値を取ります。
マシンチューニングパラメーター
この方法では、カーネルタイプのパラメータ決定について、指定した最小値と最大値の値から「候補者の数」オプションに記載の数だけ取り、最良の値を決定します(グリッドサーチという手法)。
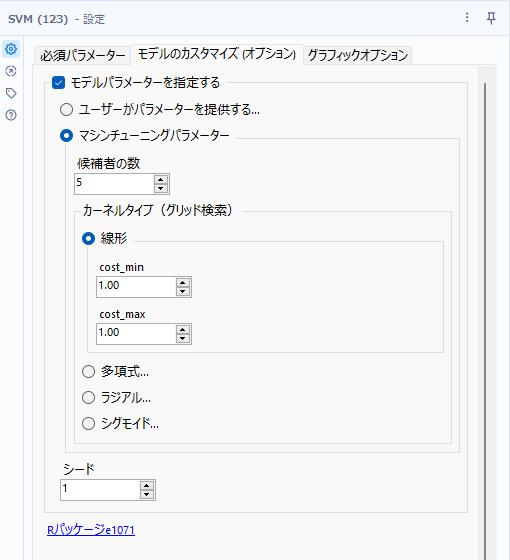
選択できるカーネルタイプは「ユーザーがパラメータを提供する」オプションと同じであり、さらに指定パラメータも同じですが、指定は最小値と最大値を指定することになります。
レポートを読み解く(分類の場合)
Model Summary

Call
Rのモデル呼び出し時の関数のオプションがここでわかります。サポートベクターマシーンはsvm関数を使っています。
なお、モデルのカスタマイズで「マシーンチューニングパラメーター」を選択すると、呼び出し関数は「best.tune」となります。
Target
指定したターゲット変数です
Predictors
指定した予測変数です
Cost
Costの値です。モデルのカスタマイズを行った場合は指定した値となります。
Gamma
Gammaの値です。モデルのカスタマイズを行った場合は指定した値となります。
Model Performance

Confusion Matrix(混同行列)
行方向は予測したもの、横方向は実際のデータで、各件数を記載した表です。SVMのレポートは、シンプルのため、作成されたモデルの良し悪しをざっくり判断するのはこのセクションくらいですが、以下のようにNoteにかかれています。
The performance here is solely based on training data set, thus good performance appears to be here does not always indicate a good models. It is possible that the model is overfit. The purpose of this “Model Performance” section is only for a quick reference.
Alteryx SVM Reportより
翻訳すると「ここでの性能はトレーニングデータセットにのみ基づいているため、ここでの性能が良いように見えても、必ずしも良いモデルであることを示すものではありません。モデルがオーバーフィットしている可能性もあります。この「モデル性能」セクションの目的は、あくまでもクイックリファレンスとして利用することです。」
混同行列だと、カウントなので、パーセントなどで計算しないと比較がさくっとしにくいかもしれません。
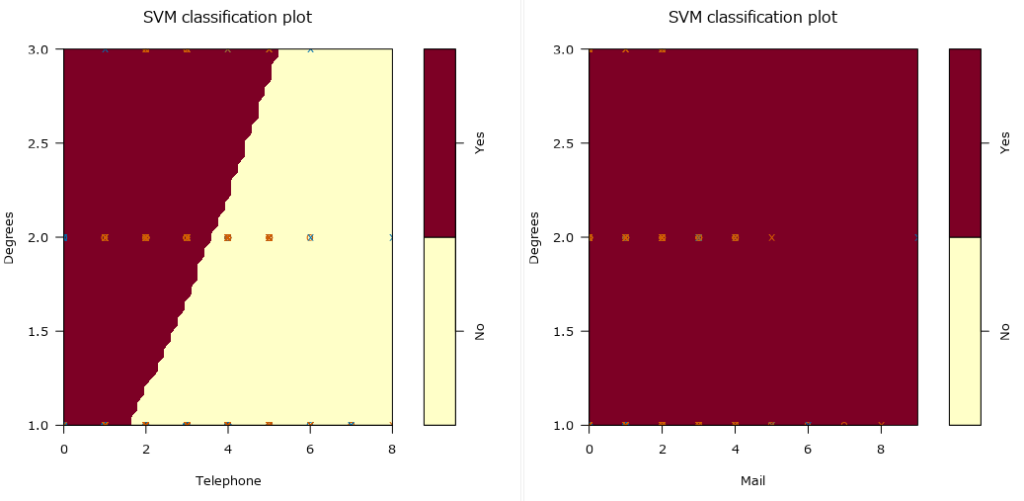
SVM Classification plot
レポートの最後に大量に出てくるのがこのSVM Classification Plotです。各予測変数を縦軸、横軸に取り、色でターゲット変数のどれに属するかを表現しています(つまり、分類している線が表現されています)。
レポートを読み解く(回帰の場合)
回帰の場合はレポートはシンプルになります。分類の場合に出力される大量のプロットは出力されません。
Model Summary

Model Summary
Call
Rのモデル呼び出し時の関数のオプションがここでわかります。サポートベクターマシーンはsvm関数を使っています。
なお、モデルのカスタマイズで「マシーンチューニングパラメーター」を選択すると、呼び出し関数は「best.tune」となります。
Target
指定したターゲット変数です
Predictors
指定した予測変数です
Cost
Costの値です。モデルのカスタマイズを行った場合は指定した値となります。
Gamma
Gammaの値です。モデルのカスタマイズを行った場合は指定した値となります。
Model Performance
モデルの能力はここで判断することができます。表示されるパラメータは以下のとおりです。
Root Mean Squared Error(RMSE)
R-squared(R二乗値)
Mean Absolute Error(MAE)
Median Absolute Error(MAbE)
Residual plot and Residual Distribution(残差プロットと残差分布)
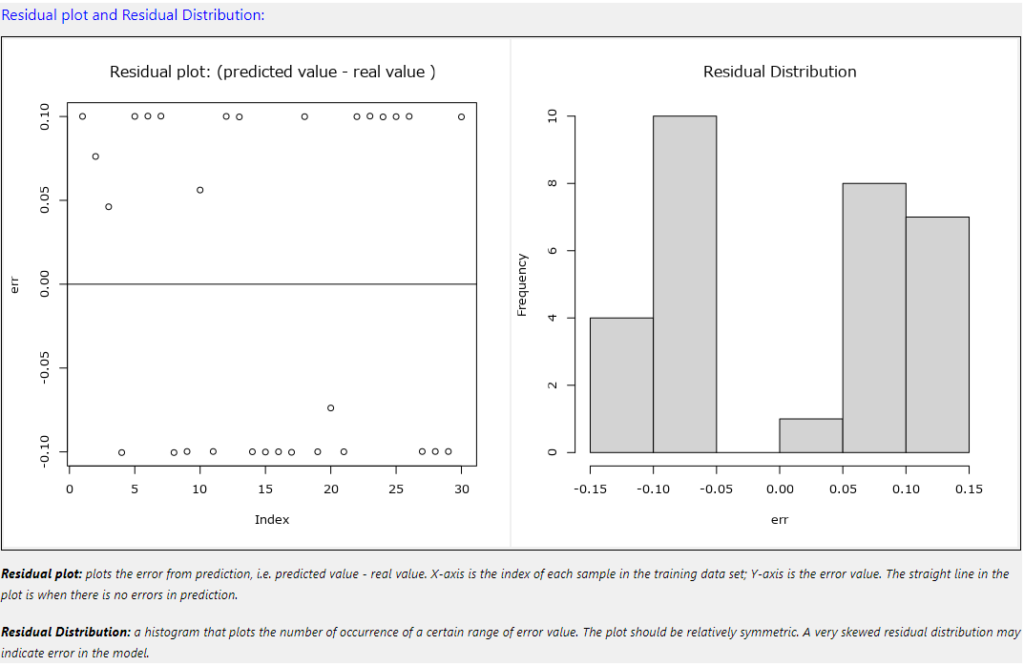
Residual plot(残差プロット)
横軸はトレーニングデータの各データのインデックス、縦軸は誤差の値です。つまり、各データの誤差がどれくらい出ているか、ということを表現しています。エラーゼロであれば予測値と実測値が一致しているということになります。
Residual Distribution(残差分布)
残差のヒストグラムです。横軸は残差の値(の範囲)、縦軸はその残差の範囲のカウントです。残差は0を中心として左右対称であることが望ましいです。この分布が歪んでいる場合はモデルに問題があることを示しています。
参考
SVMはAlteryxのコミュニティなどでも言及が少ないモデルです。
- 1.4. Support Vector Machines(scikit-learn)
- サポートベクターマシン入門
コメント