
※過去記事はこちら。AlteryxユーザーのためのAdvent of Codeの始め方、1日目、2日目、3日目、4日目、5日目
6日目です。
タイトルは「Tuning Trouble」。チューニングトラブルですね。
6日目は若干難易度が柔らかくなりました。マクロ無しで対応可能です。前日がマクロ必須だったのでそろそろやばいかな、と思ってましたが、逆に簡単になりました。
入力データとしては、以下のようになっています。なんというシンプルな入力でしょうか!
mjqjpqmgbljsphdztnvjfqwrcgsmlb今回の問題は、4文字のかたまりで見たときに、重複がない場合の最初の場所を発見する問題です。
例えば、上の例でいけば、頭から4文字見て(mjqj)重複する文字があったら一文字右にずれてまた4文字見る(jqjp)、ということを繰り返して行き、4文字中に重複する文字がないところを発見すれば良いだけです。つまり、以下の赤い部分が該当の文字列で、最後の文字「m」の先頭からの文字数は7文字目、ということで答えは7となります。
mjqjpqmgbljsphdztnvjfqwrcgsmlb常に同じ文字列に対してデータを処理する、といった場合は複数行フォーミュラが常套手段です(もちろん反復マクロでもできるのですが、処理にかかる時間がかなり違います。反復マクロは遅いです)。
ちなみに、Part2は4文字見ていましたが、14文字になります。
・ネ
・
・タ
・
・バ
・
・レ
解いてみる
大きく分けると、複数行フォーミュラでがんばってIF文を書く方法と、文字を分割して集計ツールで重複しないカウントを取って指定文字数になっているかをフィルタで抜き出す方法の2つになるかと思います。
複数行フォーミュラを使う方法
全ての文字列を正規表現ツールで縦方向にバラしてから、複数行フォーミュラを使って4行にまたいで比較し、重複するものがあればフラグを立てておきます。その後、フィルターツールでフラグが立っているもののみ残し、先頭の1行を取れば完了です。
ポイントは複数行フォーミュラで比較する行を増やして対応することでしょうか。
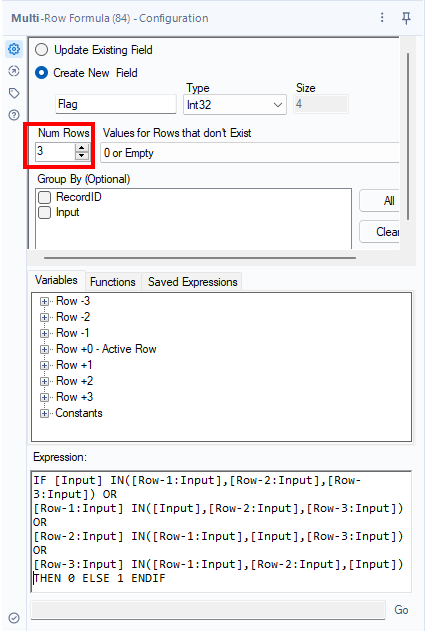
式は、IN句を使うことで簡単に書くことができます。比較文字を一行ずつずらして他の3行と比較し、一致しているものがなければフラグを立てます。
IF [Input] IN([Row-1:Input],[Row-2:Input],[Row-3:Input]) OR
[Row-1:Input] IN([Input],[Row-2:Input],[Row-3:Input]) OR
[Row-2:Input] IN([Row-1:Input],[Input],[Row-3:Input]) OR
[Row-3:Input] IN([Row-1:Input],[Row-2:Input],[Input])
THEN 0 ELSE 1 ENDIFPart2も考え方は同じですが、比較する行が14行に増えるのでIF文を書くのが大変でした・・・。実はこのまま強引にやるか、別のロジックを考えるか迷いましたが、そのまま行きました。少し面倒なだけで確実にこの方法だとできることがわかっていたからです(結果としてそれは正解でした)。
以下のような式です。見やすくするために、ORの後ろは一行あけています。
IF [Input] IN([Row-1:Input],[Row-2:Input],[Row-3:Input],[Row-4:Input],[Row-5:Input],[Row-6:Input],[Row-7:Input],[Row-8:Input],[Row-9:Input],[Row-10:Input],[Row-11:Input],[Row-12:Input],[Row-13:Input]) OR
[Row-1:Input] IN([Input],[Row-2:Input],[Row-3:Input],[Row-4:Input],[Row-5:Input],[Row-6:Input],[Row-7:Input],[Row-8:Input],[Row-9:Input],[Row-10:Input],[Row-11:Input],[Row-12:Input],[Row-13:Input]) OR
[Row-2:Input] IN([Row-1:Input],[Input],[Row-3:Input],[Row-4:Input],[Row-5:Input],[Row-6:Input],[Row-7:Input],[Row-8:Input],[Row-9:Input],[Row-10:Input],[Row-11:Input],[Row-12:Input],[Row-13:Input]) OR
[Row-3:Input] IN([Row-1:Input],[Row-2:Input],[Input],[Row-4:Input],[Row-5:Input],[Row-6:Input],[Row-7:Input],[Row-8:Input],[Row-9:Input],[Row-10:Input],[Row-11:Input],[Row-12:Input],[Row-13:Input]) OR
[Row-4:Input] IN([Row-1:Input],[Row-2:Input],[Row-3:Input],[Input],[Row-5:Input],[Row-6:Input],[Row-7:Input],[Row-8:Input],[Row-9:Input],[Row-10:Input],[Row-11:Input],[Row-12:Input],[Row-13:Input]) OR
[Row-5:Input] IN([Row-1:Input],[Row-2:Input],[Row-3:Input],[Row-4:Input],[Input],[Row-6:Input],[Row-7:Input],[Row-8:Input],[Row-9:Input],[Row-10:Input],[Row-11:Input],[Row-12:Input],[Row-13:Input]) OR
[Row-6:Input] IN([Row-1:Input],[Row-2:Input],[Row-3:Input],[Row-4:Input],[Row-5:Input],[Input],[Row-7:Input],[Row-8:Input],[Row-9:Input],[Row-10:Input],[Row-11:Input],[Row-12:Input],[Row-13:Input]) OR
[Row-7:Input] IN([Row-1:Input],[Row-2:Input],[Row-3:Input],[Row-4:Input],[Row-5:Input],[Row-6:Input],[Input],[Row-8:Input],[Row-9:Input],[Row-10:Input],[Row-11:Input],[Row-12:Input],[Row-13:Input]) OR
[Row-8:Input] IN([Row-1:Input],[Row-2:Input],[Row-3:Input],[Row-4:Input],[Row-5:Input],[Row-6:Input],[Row-7:Input],[Input],[Row-9:Input],[Row-10:Input],[Row-11:Input],[Row-12:Input],[Row-13:Input]) OR
[Row-9:Input] IN([Row-1:Input],[Row-2:Input],[Row-3:Input],[Row-4:Input],[Row-5:Input],[Row-6:Input],[Row-7:Input],[Row-8:Input],[Input],[Row-10:Input],[Row-11:Input],[Row-12:Input],[Row-13:Input]) OR
[Row-10:Input] IN([Row-1:Input],[Row-2:Input],[Row-3:Input],[Row-4:Input],[Row-5:Input],[Row-6:Input],[Row-7:Input],[Row-8:Input],[Row-9:Input],[Input],[Row-11:Input],[Row-12:Input],[Row-13:Input]) OR
[Row-11:Input] IN([Row-1:Input],[Row-2:Input],[Row-3:Input],[Row-4:Input],[Row-5:Input],[Row-6:Input],[Row-7:Input],[Row-8:Input],[Row-9:Input],[Row-10:Input],[Input],[Row-12:Input],[Row-13:Input]) OR
[Row-12:Input] IN([Row-1:Input],[Row-2:Input],[Row-3:Input],[Row-4:Input],[Row-5:Input],[Row-6:Input],[Row-7:Input],[Row-8:Input],[Row-9:Input],[Row-10:Input],[Row-11:Input],[Input],[Row-13:Input]) OR
[Row-13:Input] IN([Row-1:Input],[Row-2:Input],[Row-3:Input],[Row-4:Input],[Row-5:Input],[Row-6:Input],[Row-7:Input],[Row-8:Input],[Row-9:Input],[Row-10:Input],[Row-11:Input],[Row-12:Input],[Input])
THEN 0 ELSE 1 ENDIF14文字でもこういう状況なので、Part2がもし100文字とか50文字とかだとアウトでした。そういう意味ではラッキーです。
この方法のワークフローは以下のとおりです。
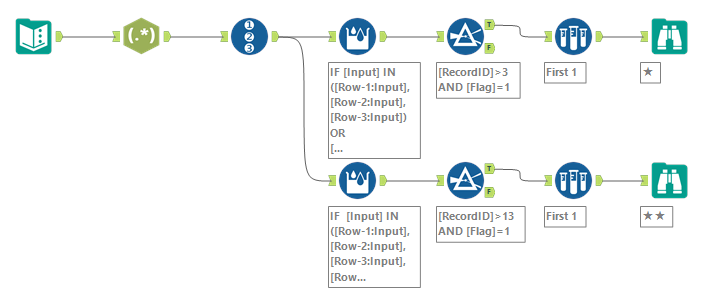
集計ツールで重複カウント
思いついていたら圧倒的にこっちのやり方のほうが楽でした。こっちの方がAlteryxらしいやり方ですね。ループを組まずに全パターン作って処理をして該当する答えを得る、という方法です。
まず、文字数分のデータを作ります。行生成ツールを使うと単一のデータを簡単にコピーできます。
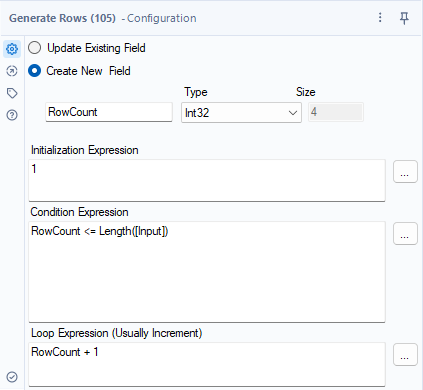
これにより以下のようなデータが文字数分できています(都合により10行までにしています)。
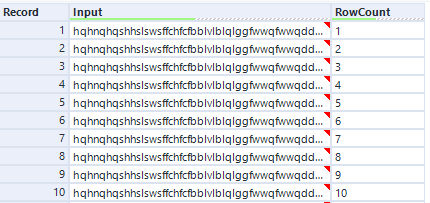
これに対してフォーミュラツールで問題文の通りのデータを作っていきます。つまりSubString関数で4文字ずつ切り出していきます。こんな感じの数式です。
Substring([Input],[RowCount]-1,4)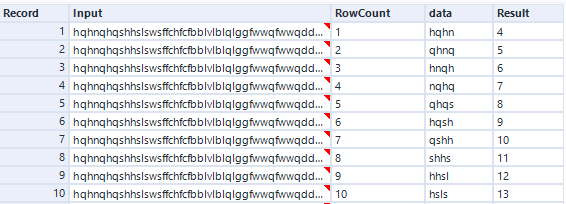
あとはこれを正規表現ツールで縦方向に1文字ずつバラして重複を除いてカウントします。
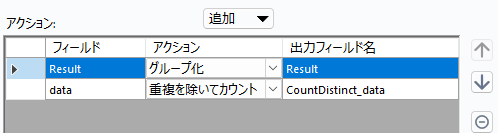
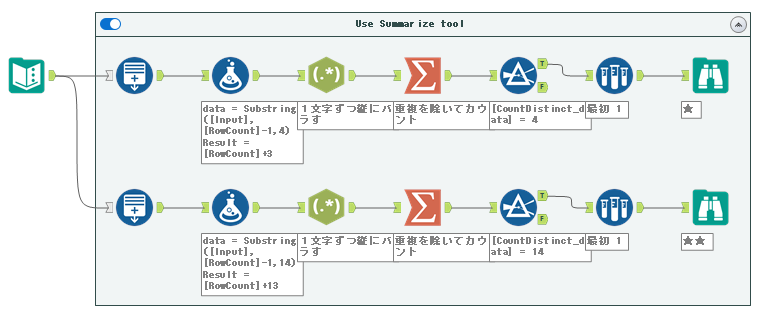
これにより、カウントが4のもののうち、最初のレコードが答えです。ワークフローとしては以下のようになります。
Part2は4文字のところを14文字にすれば終わりなのでPart1からすぐにPart2も答えることができるのがこの方法の利点ですね。
行生成ツールだけで仕留める
行生成ツールだけで仕留めることも可能です。行生成ツールの終了条件(ループ条件)にて、重複がなければ終了する、という条件にしてしまえばオッケーです。あくまで行生成ツールが作り出すのはカウントであり、終了条件で位置を探し出す、という形になります。
問題は、終了条件をどうやって得るか、ですが、REGEX_CountMatches関数を使いました。抜き出した4文字に対してREGEX_CountMatches関数で1文字のみヒットする、というのが各4文字に対して同様に1文字のみヒットであれば良いので、つまり条件式は以下のとおりです。
REGEX_CountMatches(Substring([Input],RowCount-5,4),Substring([Input],RowCount-5,1))+
REGEX_CountMatches(Substring([Input],RowCount-5,4),Substring([Input],RowCount-4,1))+
REGEX_CountMatches(Substring([Input],RowCount-5,4),Substring([Input],RowCount-3,1))+
REGEX_CountMatches(Substring([Input],RowCount-5,4),Substring([Input],RowCount-2,1))
!=4REGEX_CountMatches関数の結果を足すと4であれば終了できるので、それ以外のケースはループを繰り返す、という意味になっています。ちなみに、切り取るポイントがRowCount-5であるのは、スタートを1にしつつ、最後の解答が文字列の最後の文字の場所なのでその分をずらしています(4+1=5も自分前に倒しています)。
条件が達成されたときのRowCountが答えです(つまり、最後の行のRowCount)。
ちなみに、Part2の方の条件はなかなか長いです。Part1は前半だけでも機能しましたが、Part2は最初の14文字以内に条件に達成してしまうので後半の条件も入れざるを得ませんでした(というか、Part1でも同様にした方が汎用性は高いです)。
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-15,1))+
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-14,1))+
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-13,1))+
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-12,1))+
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-11,1))+
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-10,1))+
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-9,1))+
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-8,1))+
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-7,1))+
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-6,1))+
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-5,1))+
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-4,1))+
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-3,1))+
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-2,1))
!=14
OR (
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-15,1))+
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-14,1))+
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-13,1))+
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-12,1))+
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-11,1))+
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-10,1))+
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-9,1))+
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-8,1))+
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-7,1))+
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-6,1))+
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-5,1))+
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-4,1))+
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-3,1))+
REGEX_CountMatches(Substring([Input],RowCount-15,14),Substring([Input],RowCount-2,1))
=14 AND RowCount<14
)最終のワークフローは以下のとおりです。
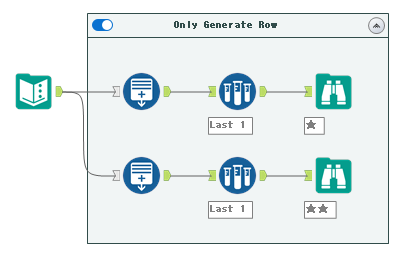
この行生成ツールの終了条件をうまく使う方法は私も試したのが初だったので、今後使えるところがあれば使っていきたいと思います。いずれにしても、行生成ツールはかなり複雑なこともできるので(実用性はさておき、なのですが)、さわりがいのあるツールです(なかなか思い通りに行きませんが)。
ちなみに、コミュニティではフォーミュラツール1個で正規表現で解答を導き出した猛者もいました。これもかなり長い正規表現なので解決に速度を求めるときは向かないのではないかと思っています。
まとめ
- 6日目はシンプルな問題でしたが、重複をどうやって取るか、というところで自分も含めて思ったよりみなさん時間を取られたのではないかと思います。
- 最速の人では7分でしたが、2位で13分とちょっと離れました。
- 個人タイム:Part1 6分53秒、Part2 13分1秒(Private Leaderboardで2位)
そろそろマクロじゃないと解けない問題のオンパレードになりそうです(毎年そんな感じでした)。

コメント