
Alteryxの予測モデルのためのデータ準備(2)では、予測変数の選び方について記載しましたが、実際に量的変数を選択する際のツールの使い方を紐解いていきたいと思います。
まず、量的変数の場合は以下のツールが利用できます。
- ピアソン相関ツール
- スピアマン相関ツール
- アソシエーション分析ツール
基本的に、ピアソン相関ツールもスピアマン相関ツールも相関を取るためのツールです。方式(適用すべきデータの種類)が異なるだけです(が、ツールの使い方は異なります)。
ピアソン相関ツール(Pearson Correlation)

ピアソン相関ツールは、選択したフィールド間の相関を計算します。使い方は相関を取りたいフィールドにチェックを入れるだけです。
適応するデータは連続的な数値データ(離散値ではないということ)で、単調関数(途中で方向が変わらない)となるデータです。放物線のような分布を見せるデータには適応しません。
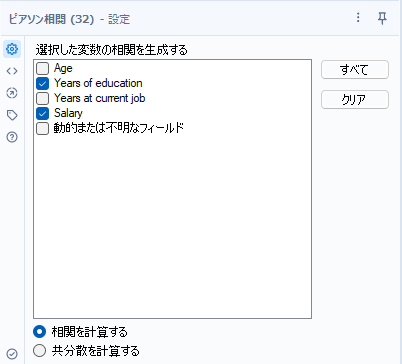
共分散も計算可能ですが、相関があるかどうかの判定が難しいため、一般的に相関のみ取ればオッケーです。
出力される結果は、相関を計算した場合は、
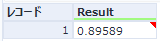
といった、-1~1の値の範囲の値です。絶対値を取った際に1に近いほど相関が強いという意味になります。プラスマイナスは、プラスの場合は正の相関、マイナスの場合は負の相関ということになります。
基本的には、ターゲット変数に相関が強い予測変数を選択する必要があるので、絶対値が1に近い予測変数を選択すればオッケーです。
なお、複数項目を選択した場合は、以下のような出力となります。

左上から右下にかけて1が出ていますが、これは同じ項目同士なので当然の結果です。SalaryとYears of educationは0.89と1に近く強い相関がありますが、SalaryとYears at current jobの間には相関はありません。
スピアマン相関ツール(Spearman Correlation)

スピアマン相関ツールは、選択した2つのフィールド間の相関を計算します。適応するデータは、離散値となります。

結果は以下のようになります。
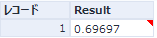
値の見方は、ピアソン相関の場合と同じで、絶対値が1に近いほど強い相関を持つことになります。
ピアソン相関ツールのように、一気に複数の項目の相関を取れないので注意してください。
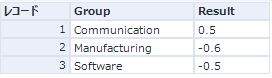
ただし、スピアマン相関ツールには、グループ化オプションが利用可能です。
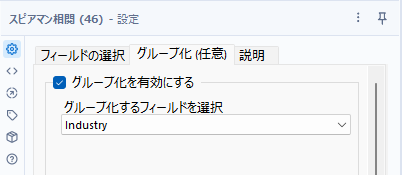
これにより、以下のようにカテゴリごとに相関を求めることができます。
アソシエーション分析ツール

アソシエーション分析ツールは、今回解説したピアソン相関とスピアマン相関について、選択したフィールド同士のp値と相関係数をマトリクス状に出力してくれるツールです。ピアソン相関ツールについては元々複数のフィールドを選択することでマトリクス状に出力することができましたが、スピアマン相関ツールにはその機能はありませんでした。また、加えてヘフディングのD統計も計算することができます。
ヘフディングのD統計はこれまで出てきていませんでしたが、非線形なデータの相関(例えばU字型)も取ることができます(ピアソン相関、スピアマン相関は単調関数に限定されていました)。
それでは、使い方を見ていきたいと思います。
アソシエーション分析ツールは、大きく分けてターゲット・フィールドを指定する場合としない場合で出力が変わります。
ターゲット・フィールドを指定しない場合
ターゲット・フィールドを指定しない場合は(「より詳細な分析のためにフィールドをターゲットにする」オプションにチェックを入れない)、ピアソン相関ツールのマトリクスと同じような出力を得られます。
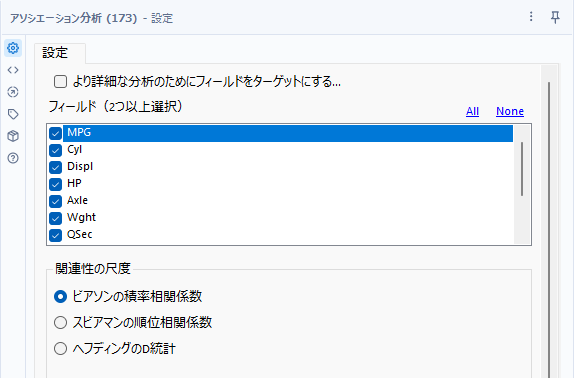
指定項目も、ピアソン相関ツールと似たようなもので、相関を取るフィールドを指定し、どの方式で相関を取るかを指定します(各相関係数を一度に取れればさらに便利なのですが)。
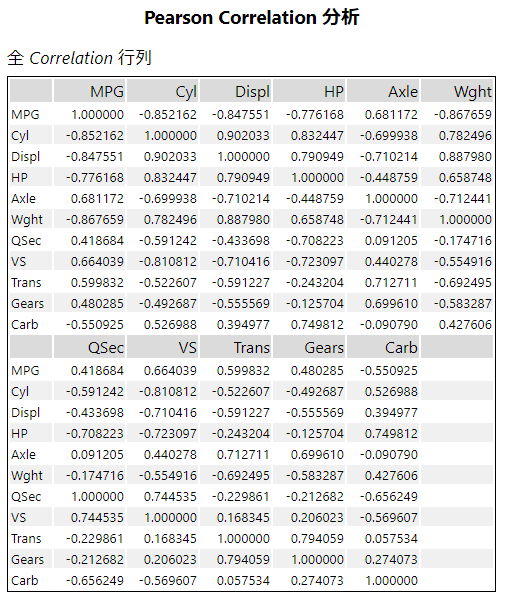
結果は、以下のような相関行列が一つ。
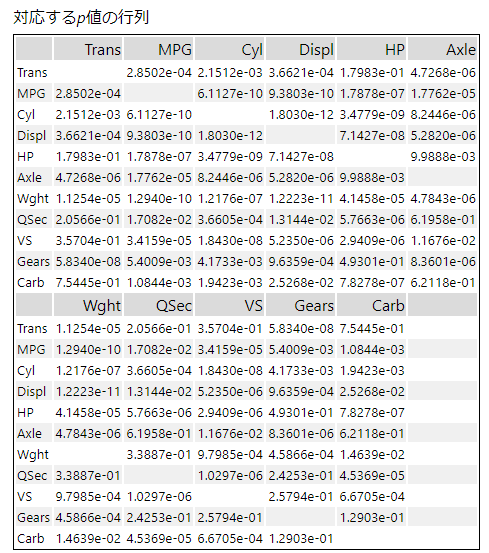
さらにp値の行列も得られます。
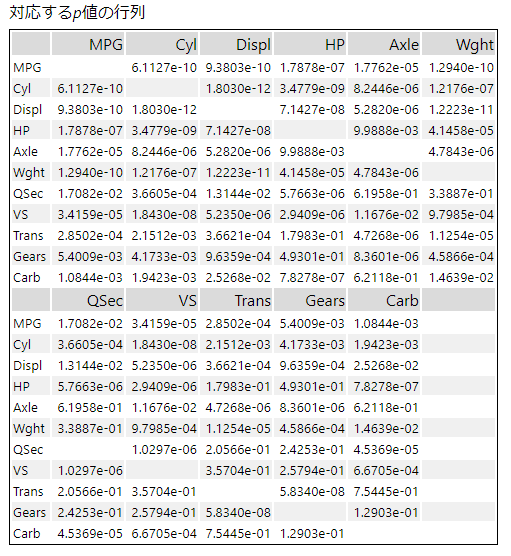
正直なところ、p値の行列はあまり見やすくはありません・・・。各値が「e-1」である時は、p値が0.1~0.9と大きいので相関がない、ということになります。「*」も併記されているとわかりやすいのですが・・・。
ただ、I出力の方を見ると、以下のようなインタラクティブなレポートが得られます。基本的には、左側のヒートマップで色の濃いところ(赤が+1に近く、紫が-1に近い値です)は相関があるところ、という判断が可能となっています。
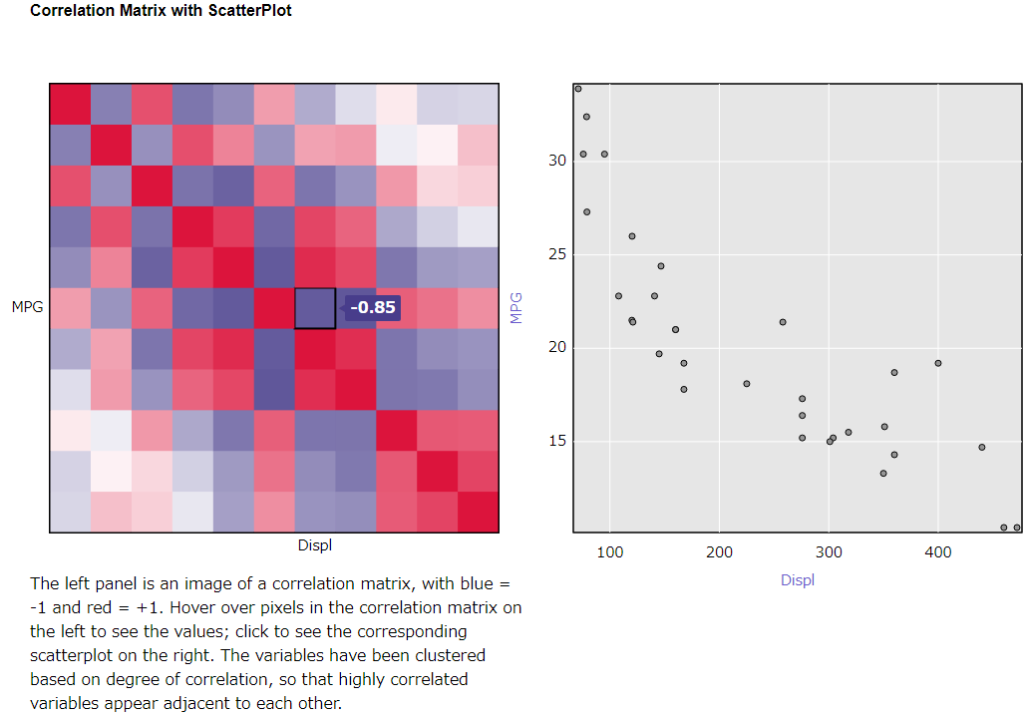
左側の四角い部分をクリックすると、右側に散布図が表示され、データの分布を確認することができます。このサンプルでは、MPGとDisplの交差するところをクリックし、それらのデータ間の相関を見ています。確かにちょっと曲線ぽいところはありますが、(負の)相関がありそうな分布をしていることがわかります。
ターゲット・フィールドを指定する場合
次に、ターゲット・フィールドを指定してみましょう。「より詳細な分析のためにフィールドをターゲットにする」オプションにチェックを入れ、ターゲット・フィールドに特定のフィールドを指定します。この時、ターゲット・フィールドには機械学習で予測を行いたいターゲット変数を指定するのが普通です。ただし、指定できるフィールドには制限があり、数値もしくはバイナリ(2値)である必要があります(つまり、複数のカテゴリを持つようなカテゴリ変数は指定できません)。バイナリの場合はテキスト形式のデータでも構いません。
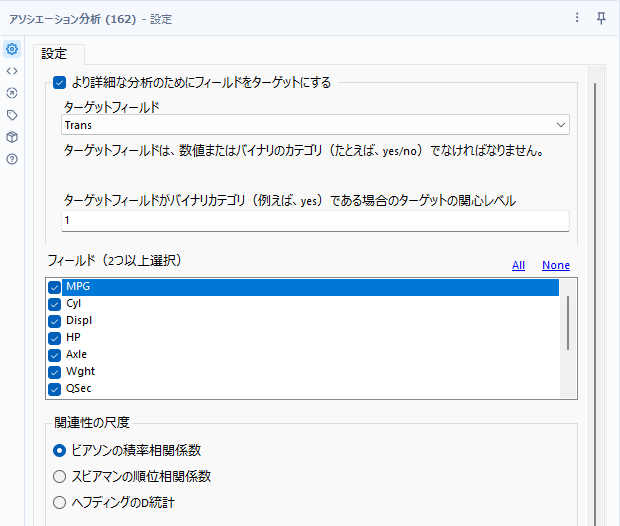
バイナリカテゴリの場合、「ターゲット・フィールドがバイナリカテゴリである場合のターゲットの関心レベル」には、中心として見たい変数を入力します(yes/noであればyesを入れるイメージです)。
あとは「ターゲット・フィールドを指定しない」場合と同じく、ターゲット・フィールドと相関を見たいフィールドについて、どの方式で相関を計算するか、を指定します。
これにより以下のようなレポートが得られます。
まず、ターゲット・フィールドと選択した予測変数間のp値のリストです。これは機械学習モデルにかけたときと同じようなレポートとなっており、p値とともにアスタリスク付きで出ています。p値が0.05未満であれば「*」が一つつきます。0.01未満なら「**」、0.001未満なら「***」となります(一般的な指標です)。
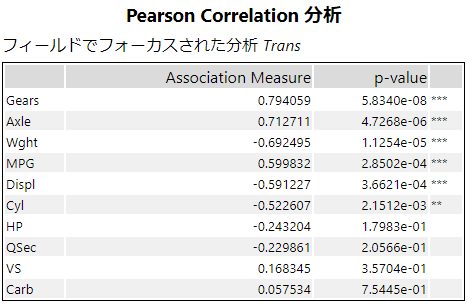
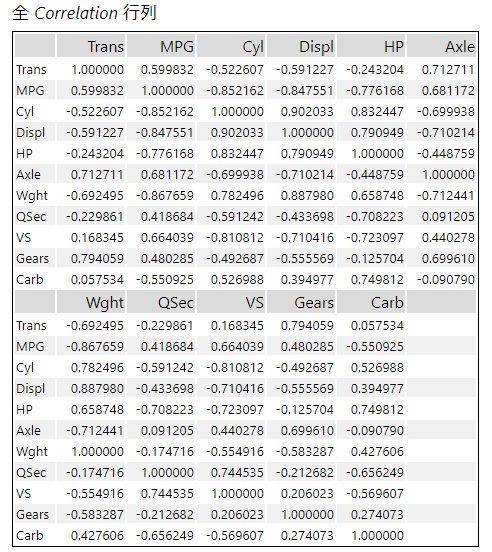
あとはターゲット・フィールドを指定しない場合と同じレポートが出力されます。
次回は、質的変数の場合についてそれぞれ各ツールを見ていきたいと思います。
参考資料
Pre-Predictive: Using the Data Investigation Tools – Part 3 of 4
Pre-Predictive: Using the Data Investigation Tools – Part 3 of 4は、アソシエーション分析ツール、ピアソン相関ツール、スピアマン相関ツールについて解説されています。
Tool Mastery | Association Analysis
Tool Mastery | Association Analysisは、ツールマスタリーシリーズのアソシエーション分析ツールです。
コメント