
Alteryx Predictive Master資格取得を目指すシリーズです。
Alteryxの予測カテゴリに配置されているモデルについて解説していきます。
今回は分類・回帰両方できる「スプラインモデル(Spline Model)」ツールについて解説していきます。
- スプラインモデル概要
- 設定
- 必須パラメーター
- モデルのカスタマイズ
- ターゲットタイプとGLMファミリを指定する(Specify target type and the GLM family)
- ターゲット変数をスケーリングする(Scale the target variable)
- ノットの最大数を手動で設定する(The maximum number of knots or determine automatically (Auto))
- 相互作用の深さ(Interaction depth)
- 項またはノットごとに手動でペナルティを設定する(Penalty per term or knot)
- 追加のノットを追加するためにR-二乗の最小限の改善が必要です(The minimal improvement in R-Squared needed to add an additional knot)
- ノット間の最小距離(The minimum distance between knots)
- 新しい変数のペナルティ(New variable penalty)
- フォワードパスの各ステップで考慮される親用語の最大数(The maximum number of parent terms considered at each step in the forward pass)
- 高速MARSエージング係数(The fast MARS aging coefficient)
- 相互検証分析を行う(Perform a cross validation analysis)
- プルーニング方法(The pruning method)
- プルーニングされたモデル内の用語の最大数(The maximum number of terms in the pruned model)
- レポートを読み解く
スプラインモデル概要

スプラインモデルツールは、フリードマンの多変量適応的回帰スプライン(MARS)アルゴリズムを提供するツールです。
※MARS=Multivariate Adaptive Regression Spline
スプラインモデルは、非線形なデータにも適用できます。これは、線形モデルを折れ線で表現しているモデルだからです。
なお、スプラインモデルは回帰問題か分類問題か、については自動で判定するようになっています。
スプラインモデルは複数の直線(折れ線)で構成され、直線のつなぎ目のポイントを「ノット」と呼びます。

また、各折れ線の部分は「ヒンジ関数」と呼ばれます。式としては「max(0, x-c)」もしくは「max(0, c-x)」といった形になります(cは定数)。
なお、スプラインモデルは、Alteryxのコミュニティでの情報が非常に少ないツールです。
設定
必須パラメーター
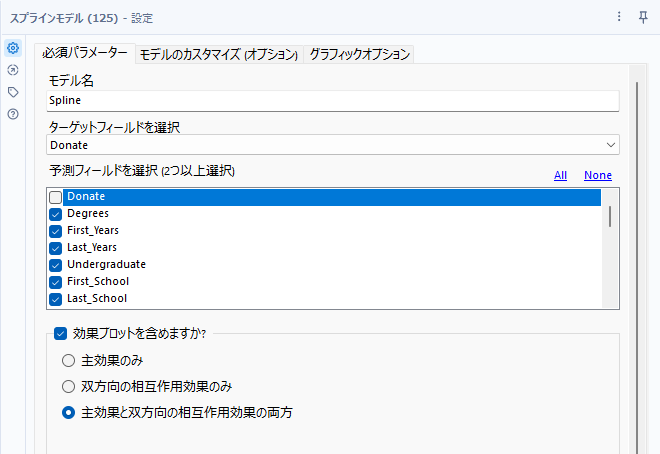
必須パラメータとしては、モデル名、ターゲットフィールド、効果プロットを含めるか、という内容となります。「効果プロットを含めますか?」は、単にグラフを表示するかどうかだけなので、予測モデルの中身に対しては特に変化は起きない設定となります(が、2022.3時点ではバグで常に表示されるようになっています)。
モデルのカスタマイズ
かなり大量のオプションがあります・・・。
各オプションは、スプラインモデルツールの各ステップに対して与えるパラメータを指定するものです。
多変量適応的回帰スプラインモデルを構築するには2つのステップで構成されます。
1つ目は、フォワードパスで、応答値の平均だけで構成されるモデルから開始し、残差誤差を最も減らす基底関数のペアを見つけ、モデルに項を追加していきます。
次のバックワードパスで、フォーワードパスで追加された項を剪定します。これは、フォーワードパスは基本的にオーバーフィッティング傾向となるため、最も効果の低い項を削除し、最適なサブモデルを作成します。
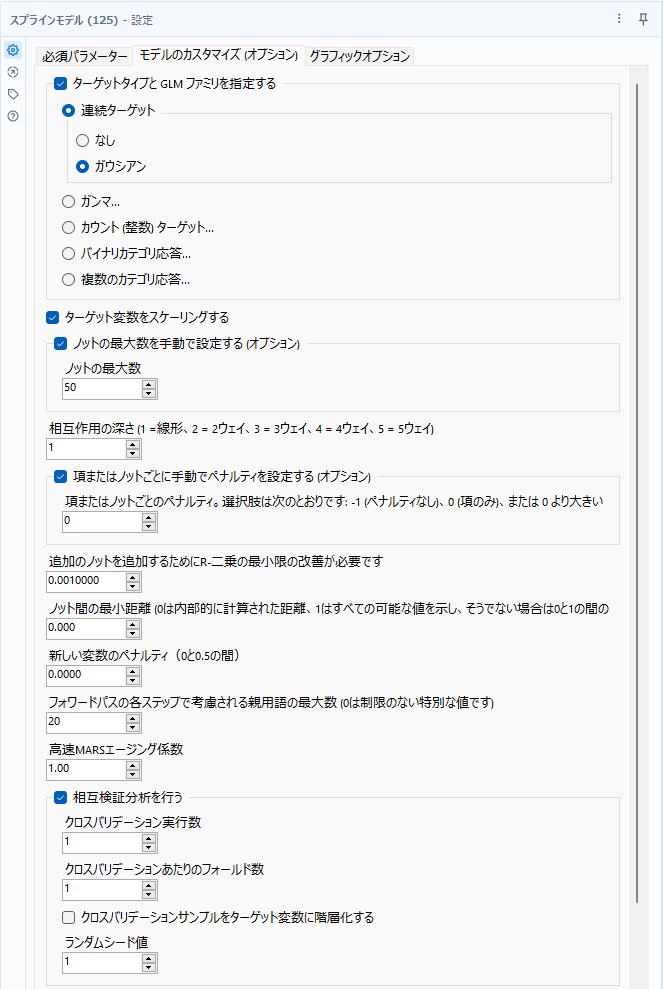

ターゲットタイプとGLMファミリを指定する(Specify target type and the GLM family)
ターゲット変数が回帰か分類か、は自動で判定しますが、ここで指定も可能です。
連続ターゲット(Continuous targets)
ターゲット変数が、連続の数値(小数点を含む数値)である場合のオプションです。リンク関数として、ガウシアンを指定可能です。
ガンマ(Gamma distributed targets)
ターゲット変数が、正の連続の数値(小数点を含む数値)でガンマ分布を示すような場合のオプションです。リンク関数として、log、inverse、identityを選択可能です。
カウント(整数)ターゲット(”Count” targets)
ターゲット変数が、ポアソン分布(正の整数)を示すような場合のオプションです。リンク関数として、log、identityを選択可能です。
バイナリカテゴリ応答(Binary categorical targets)
ターゲット変数が、Yes/NoやTrue/Falseなど2値を取るような場合のオプションです。リンク関数としてlogit(ロジット)、probit(プロビット)、cloglog(complementary log-log)を選択可能です。
複数のカテゴリ応答(Multinomial categorical targets)
ターゲット変数が、カテゴリ変数であるような3以上の値を持つ場合のオプションです。
ターゲット変数をスケーリングする(Scale the target variable)
ターゲット変数が連続値である場合に平均値を0、1を標準偏差とするような標準化(Zスコア変換)が行われます。
ノットの最大数を手動で設定する(The maximum number of knots or determine automatically (Auto))
スプラインモデルは複数の直線で構成されますが、その線分の分岐点(ノット)の最大数を指定することができます。この値を抑えることで、モデルが単純化することができます。指定しない場合は、予測変数の数にもとづいて計算されます。デフォルトは50、最小値は1、最大値は999,999です。
相互作用の深さ(Interaction depth)
予測変数間の相互作用のレベルです。デフォルト値は1で、予測変数間に相互作用がないという想定です。1~5の数値を取ることができます。この値を増やすとモデルの実行時間が大幅に長くなります。
項またはノットごとに手動でペナルティを設定する(Penalty per term or knot)
選択肢としては、ペナルティ無し(-1)、項のみ(0)、もしくはペナルティの値(1~999,999)を指定可能です。
追加のノットを追加するためにR-二乗の最小限の改善が必要です(The minimal improvement in R-Squared needed to add an additional knot)
ノットを追加するためにはR二乗値が、指定した値より高くなる必要があります。0.0000001~1の範囲の値を取ることができます。デフォルト値は0.001です。
※オプション名がおかしいですが、「ノットを追加するために必要とされるR二乗の最小値」とかでしょうか?
ノット間の最小距離(The minimum distance between knots)
0は内部的に計算された距離になります。1は制限なしとなります。それ以外の値は最小距離となります。デフォルトは0。
新しい変数のペナルティ(New variable penalty)
モデルに新しい変数を追加するための目的関数に追加される追加のペナルティ項。デフォルトは0(なし)。値の範囲としては0~0.5です。この項目はオーバーフィッティングを抑制するために指定します。
フォワードパスの各ステップで考慮される親用語の最大数(The maximum number of parent terms considered at each step in the forward pass)
フォーワードパスで作成される項の数を制御することで、実行の高速化を図ります。0は制限なし。それより大きい場合は、項の最大数となります。デフォルトは20。一般的な値は、20、10、5です。
この項は、フォワードパスで作成される項の数を制御し、実行を高速化することができます。特別な値である0はこの項に制限を与えず、0より大きい数値は項の最大数を指定する。デフォルトは20項で、一般的な値は20、10、5である。最大値は30です。
高速MARSエージング係数(The fast MARS aging coefficient)
フリードマン(1993)のセクション3.1を参照とのこと。値の範囲としては0~1の間を取ります。デフォルトは1。モデル構築を高速化させるためのオプションです。
相互検証分析を行う(Perform a cross validation analysis)
クロスバリデーションを行います。チェックを入れると、「クロスバリデーション実行数」「クロスバリデーションあたりのフォールド数」「クロスバリデーションサンプルをターゲット変数に階層化する」「ランダムシード値」を指定可能です。
プルーニング方法(The pruning method)
バックワードパスで行われる剪定方法を指定します。
- 後方消去:デフォルト値です。フォワードパスで見つかったすべてのノットと項で始めます。このうち、最も予測性の低い項を最初に削除し、フルモデルに対する一般化クロスバリデーションの影響を比較sます。項を削除しても改善しない場合は、フォワードパス後に作成されたモデルになります。改善されれば、この項をモデルから削除し、残りの項についても同じように繰り返します。
- なし:フォーワードパスで見つかったすべての項を使用します。
- 徹底的な検索:フォワードパスで見つかった項のすべての組み合わせを調べますが、計算コストが高いです。
- 前方選択:定数項を除く全ての項が削除され、フォワードパスで見つかった最善の項が採用されます。これを、一般化クロスバリデーションを向上させる項が追加できなくなるまで実行します。
- 順次置換:与えられた数の項を持つ解は、1つの項を持ちます(フォワードパスで見つかった未剪定の他のすべての可能な残りの項と置き換えていきます)。一般化クロスバリデーションが元の項より改善する新しい項が見つかれば、元の項は新しい項と置き換えます。
プルーニングされたモデル内の用語の最大数(The maximum number of terms in the pruned model)
デフォルトは0。バックワードパスで使用される他の基準の後に残るすべての項が最終のモデルで使用されます。1以上の値を指定した場合は、最終的に残す項の数となります。最大値は1,000,000となります。
レポートを読み解く
関数呼び出し
スプラインモデルが内部で呼び出すRの関数の設定です。内部的には、earth関数を呼び出しています。

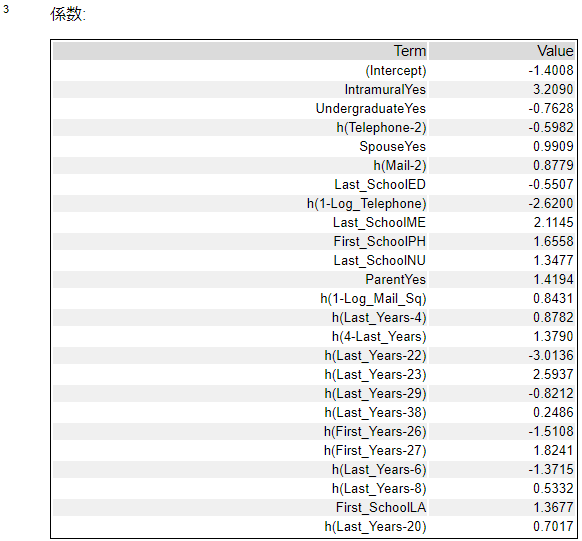
係数
各予測変数に対する係数です。スプラインモデルは複数の線形回帰で成り立っているため、各変数に対して係数が存在します。
その他

Selected
選択した項(Term)と予測変数の数が記載されます。
Importance
モデルに対して影響度の大きい予測変数のリストですが、実際に選択された予測変数(この例では15)が記載されているようです。
※選択されなかった予測変数は係数0となります
GCV(Generalized Cross Varidation)
6行目には、いくつかのモデルの当てはまりの良さの指標値が出力されています。
GCV(Generalized Cross Validation)は、一般化クロスバリデーションであり、これは重回帰式で予測変数を選択する方法の一つの指標です。値が小さいほうが当てはまりの良いモデルです。
RSS(Residual Sum of Squares)は残差平方和であり、値が小さい方がモデルの当てはまりが良いです。
GRSq(Generalized R-Squared)は0~1の間の値を取り、1に近いほど当てはまりの良いモデルとなります。
RSq(R-Squared)は決定係数で0~1の間の値を取り、1に近いほど当てはまりの良いモデルとなります。
GLM null.deviance(GLM ヌル逸脱度)
GLM null.devianceは、一般線形モデルの切片のみのモデルの逸脱度です。dof(degree of freedom)は自由度です。その他、devianceはフルモデルの逸脱度です。逸脱度は小さい方が当てはまりが良いです。
GLM Model McFadden R-Squared(GLMモデルマクファーデンR二乗)
線形回帰の決定係数に相当するもので、0~1までの値を取ります。モデルの当てはまりの良さを示し、1に近いほど当てはまりが良いです。
プロット
スプラインモデルの診断プロットです。
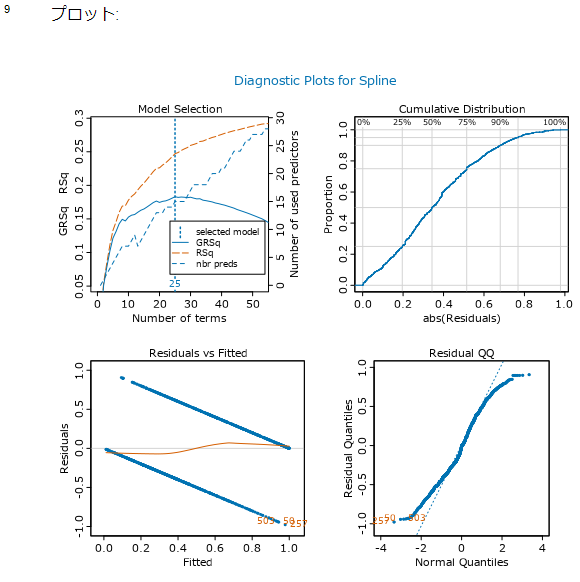
Model Selection
横軸が項(Term)の数、縦軸が決定係数です。項を追加することによって決定係数がどのように変化していったかを確認できます。青の破線が予測変数の数となっており、これは右軸で値を読み取ります。
この例では、項が25を超えるとGRSqが悪くなっており、このポイントのモデルを最終的に選択しています。
Cumulative Distribution(累積分布)
横軸が残差の絶対値、縦軸が割合です。
※詳細不明です
Residual vs Fitted(残差-推定値)
横軸は予測値、縦軸は、予測値と実際の値との差(残差)。三点について確認できます。線形性:残差が0付近にあること。分散の均一性:残差が0の先の周りに水平な帯状にあること。外れ値の有無:残差の分布を見て、明らかに外れているものがあるか、というところが確認ポイントです。
Residual QQ(残差のQ-Qプロット)
Quantile-Quantileプロットを略してQ-Qプロットと呼びます。残差が正規分布に従っていれば、直線状にプロットされます。重回帰分析では残差は正規分布に従っているという前提があり、これが崩れているようであれば、モデルの見直しが必要です。
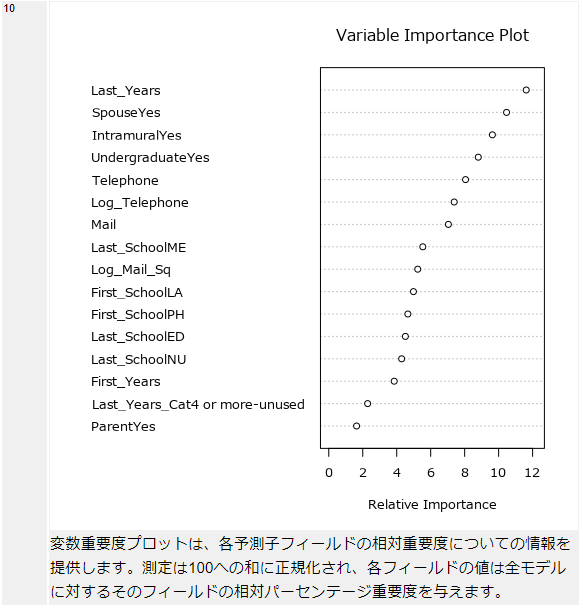
Variable Importance Plot(変数重要度プロット)
ランダムフォレストなどでも似たようなものが表示されていましたが、相対重要度(Relative Importance)という指標で各予測変数を値の大きい順に並べたグラフとなります。相対重要度は、合計で100%になるように正規化されています。
効果プロット
本来は必須パラメータの「効果プロットを含めますか?」でチェックをしたときのみ表示されるグラフですが、2022.3時点でもバグで常に表示されるようになっています。
各予測変数ごとにターゲット変数への影響をグラフで出力しています。
参考
雰囲気をつかむのに参考になります。
英語のWikiPediaのページです。スプラインモデルの記述が少なく頼りになります。
コメント