
Alteryxの予測カテゴリに配置されているモデルについて解説していきます。
今回は分類専用の2つのモデルを解説します。
- ロジスティック回帰(Logistic Regression)
- 単純ベイズ分類器(Naive Bayes Classifier)
ロジスティック回帰は2値予測専用です。単純ベイズ分類器は2値だけではなく3値以上の予測も可能です。
分類専用モデルは少ないですが、分類も回帰もできるモデルがたくさんあるので、それも含めて利用を検討する必要があります。
ロジスティック回帰(Logistic Regression)

ロジスティック回帰は、2値分類専用のモデルです。Yes/Noを予測するような場合に使われ、例えば「特定の病気になる確率」といった医療診断や、「ローンの返済確率」や「不正なクレジットカード取引」といった金融詐欺の検知、「広告を出した時に購入するかどうか」といったオンライン広告、人事採用、などで使われます。
特徴は以下のとおりです。
- 出力は確率となります。0-1の間の値を取るため、しきい値は自分で決めることが可能
- 線形モデルです
- 計算が高速
設定
ロジステック回帰は、分類モデルなのに「回帰」という名称がつくのが若干紛らわしいのですが、基本的には線形モデルとなっています。そのため、オプションについては線形回帰モデルと非常によく似ています。なお、Rの関数の呼び出しもglmを使っています。
最低限の設定は、モデル名の入力と、ターゲット変数と予測変数の設定のみです。非常にシンプルに扱うことが可能です。
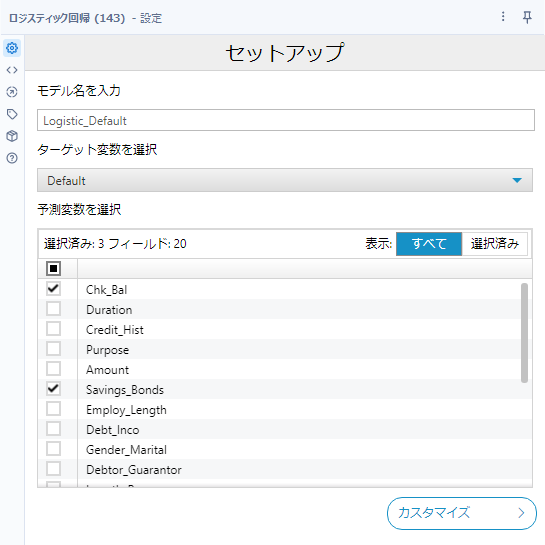
カスタマイズについては、基本は4つで、「モデル推定にサンプリングの重みを使用する」「正則化回帰を使用する」「目標変数で正のクラスを入力」「モデルタイプを選択」です。
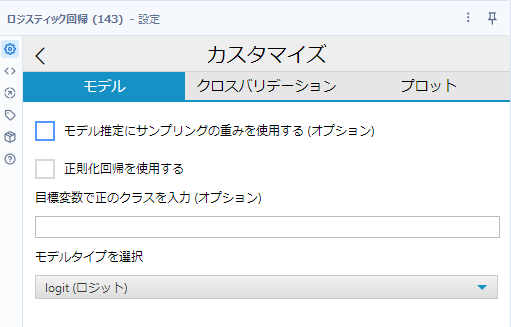
ここで、「正則化回帰を使用する」にチェックを入れると、正則化回帰用のオプションが出てくるのと、モデルタイプは選択できなくなります。なお、「モデル推定にサンプリングの重みを使用する」「正則化回帰を使用する」については、線形回帰ツールの記事を参照ください。
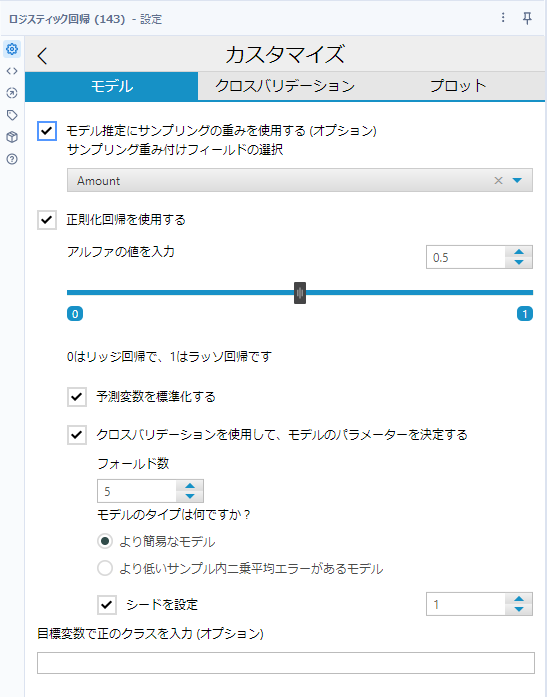
モデルタイプを選択
以下のモデルを使用可能です。
- logit(ロジット)※デフォルト
ターゲット変数が二項分布に従うと仮定したモデルです。
- probit(プロビット)
ターゲット変数が正規分布に従うと仮定した場合に利用できるモデルです。
- cloglog(complementary log-log)
左裾が長いモデルです。生存分析とハザードモデリングでよく適合するようです。
目標変数で正のクラスを入力(オプション)
「目標変数」という書かれ方をしており、日本語がぶれているように思いますが、つまり「ターゲット変数」でYesとするクラスを設定します。デフォルトでは自動的に決まります。
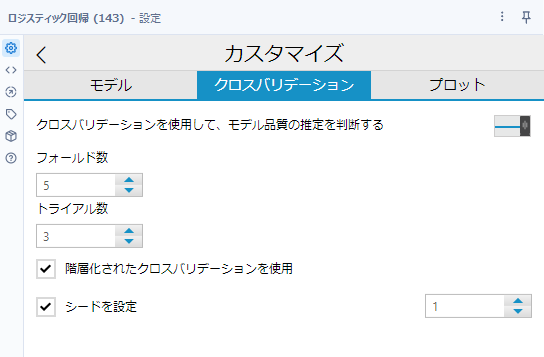
クロスバリデーションの設定は、線形回帰ツールと同様ですので、そちらを参照ください。
結果を読み解く
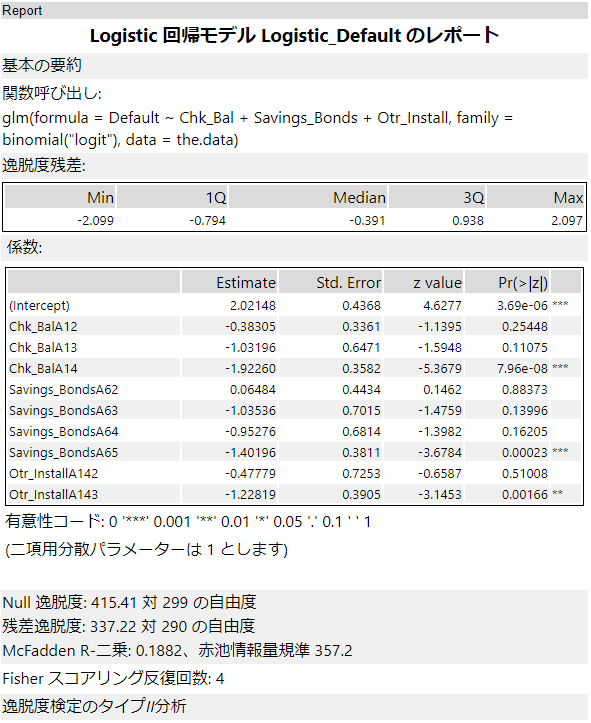
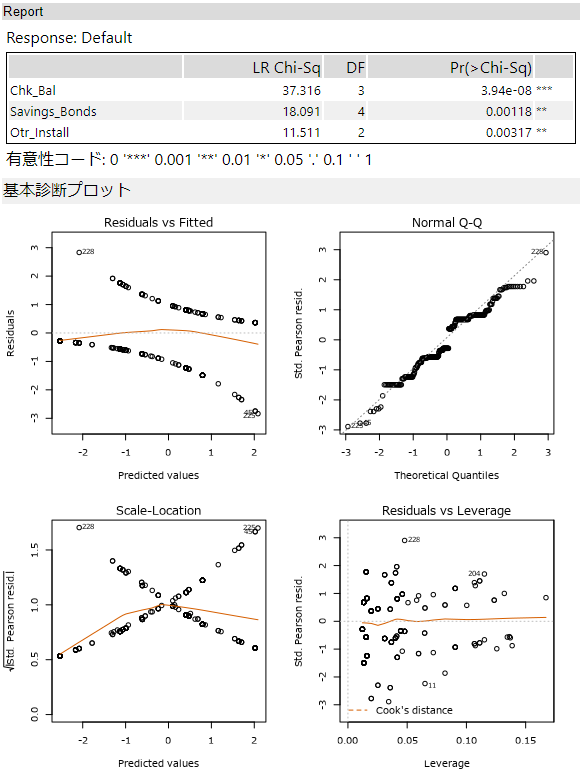
結果レポートは、利用している関数がglmのため、ガンマ回帰・ポアソン回帰とほぼ同様の内容となっています。関数呼び出しの時に、family=binomial(“logit”)となっており、ロジット関数を使っていることがわかります。レポート詳細については、ガンマ回帰の例を参照願います。
なお、サンプルワークフローは非常に多くの項目を使って学習をしていましたが、スペース的にもったいないので、3つの項目で学習しています。
単純ベイズ分類器(Naive Bayes Classifier)

単純ベイズ分類器は、分類専用のモデルですが、わかりやすい例として「メーラーのスパムフィルタ」があげられます。その他、与えられた文章がどのカテゴリに属するかといった「テキスト分類」などが有名です。単純ベイズ分類器の前提として、予測変数がすべて互いに独立しているとして動作します。
特徴としては、以下の通り。
- 動作が高速(計算量が少ない)
- 高速な学習が可能(必要なデータ量が少ない9
- 説明可能性が高い(各特徴量の影響度が簡単に計算可能)
- ノイズに強い(外れ値などに比較的強い)
なお、テキスト分類などを行うには、日本語の場合は形態素解析で品詞ごとに分解して単語を抜き出す、などの前処理が必要になります。
設定
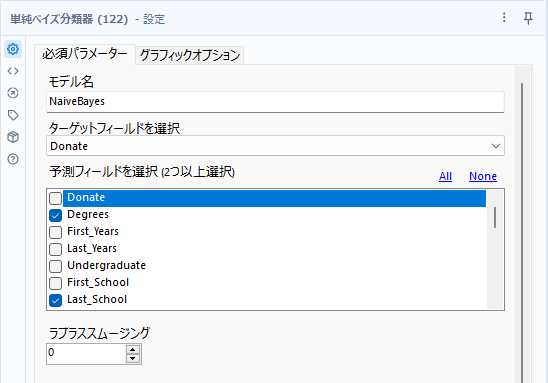
設定はほとんどありません。モデル名、ターゲットフィールドの選択、予測フィールドの選択に加えて、ラプラススムージングの設定が可能です。
なお、予測フィールドは2以上選択する必要があります。
ラプラススムージング
正の数値をスムージングパラメータとして入力可能です(通常は1などで十分なようです)。
これは、学習セットがまったく存在しないか頻度が少なく確率がゼロになってしまったような場合でも確率分布がゼロにならないように「スムージング」することで分類器の性能を向上させるためのものです。
結果を読み解く
単純ベイズ分類器のレポートはこれまで見てきた線形回帰などとは大きく異なっています。
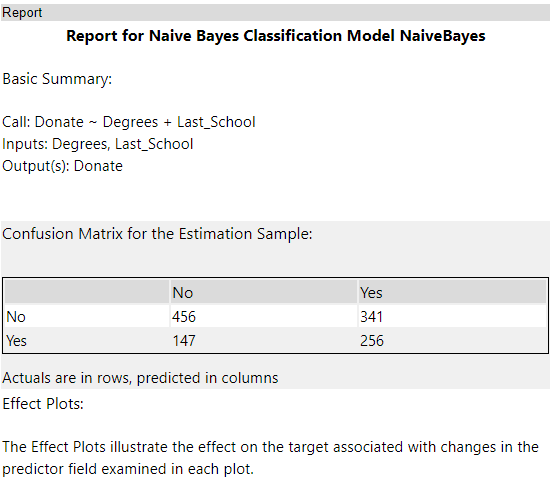
Confusion Matrix for the Estimation Sample(混同行列)
縦軸が実際の値、横軸が予測値でレコード数を配置した行列です。これにより、4つのタイプに分かれています。基本的に左上と右下のレコードの数が多いのが理想です。
- 縦軸がNoで横軸がNoの場合は、正しくNoと予測。
- 縦軸がYesで横軸がYesの場合は、正しくYesと予測。
- 縦軸がYesで横軸がNoであれば、YesなのにNoと誤判定されています。
- 縦軸がNoで横軸がYesであれば、NoなのにYesと誤判定されています。
これにより、予測精度が確認できます。
Effect Plots
Confusion Matrixより下はEffect Plotsです。各予測変数に対してそれぞれグラフが出てきます。横軸が、予測変数の値で、縦軸がターゲット変数です。それぞれの予測変数の値でターゲットがどのようになるのかすべて確認することができます。
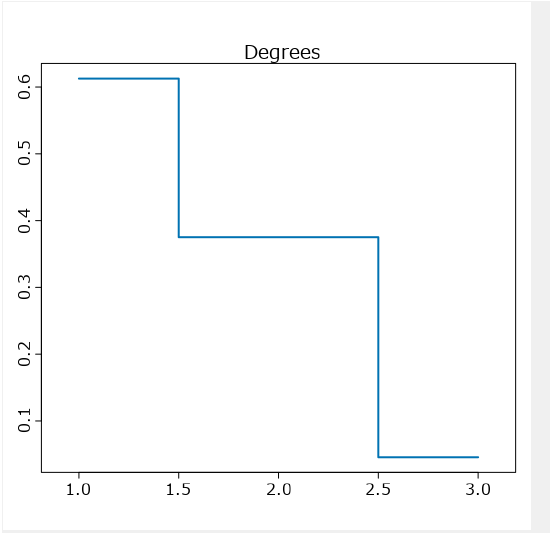
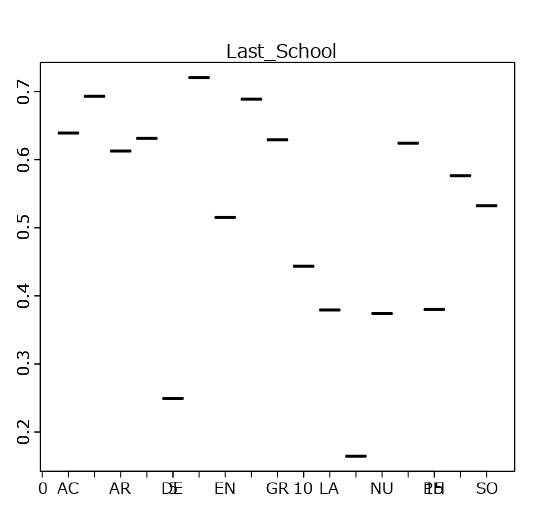
参考URL
Alteryxのツールマスタリーシリーズです。ロジスティクス回帰。
ロジスティック回帰のモデルの選び方について記載されています。
コメント