
Alteryxの予測カテゴリに配置されているモデルについて解説していきます。
今回は分類・回帰両方できるモデルのうち、決定木に関連した3つのモデルを解説します。
- 決定木(Decision Tree)
- ランダムフォレスト(Forest Model)
- 勾配ブースティング(Boosted Model)
これら3つの元になるのは決定木です。決定木自体はモデルの説明は行いやすいですが、精度はそれほど高くありません。
ランダムフォレストは決定木を複数使ったアンサンブル学習を行っています。どちらかというと分類向きのモデルで、モデルの説明は行いにくいです。精度としては良いことが多いです。
勾配ブースティングはランダムフォレストに似たいるモデルですが、ツリーの作り方が異なります。Kaggleで人気のLightGBMやXGBoostの元のモデルで、LightGBMは高速なため喜んで使われています。もちろん精度も高いです。
決定木(Decision Tree)

決定木は、条件分岐をひたすら行うアルゴリズムです。
特長は以下のとおりです。
- ツリープロットによるモデルの可視化
- 外れ値に強い
- 最も重要な変数は自動的に選択される
一方、以下のような悪い点もあります。
- オーバーフィッティングしやすい
- トレーニングデータの変化に敏感
- 回帰では連続的な値を取りにくく、ガタガタした値になってしまう
設定
基本的な設定はモデル名の入力、ターゲット変数の選択、予測変数の選択となります。
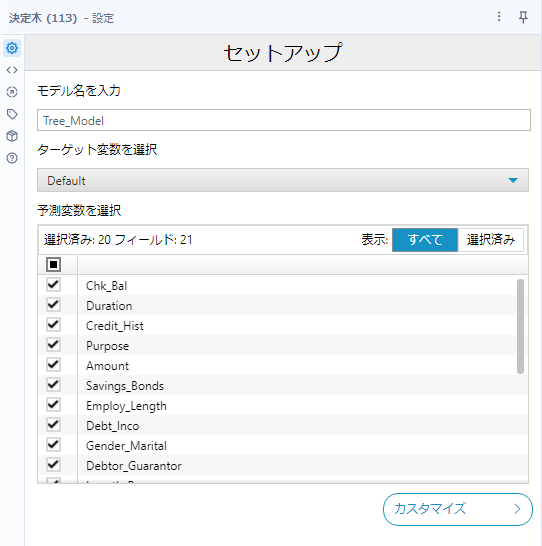
カスタマイズボタンをクリックすると、さらに詳細を設定可能ですが、モデルのアルゴリズムを変更すると設定ががらっと変わってしまいます。
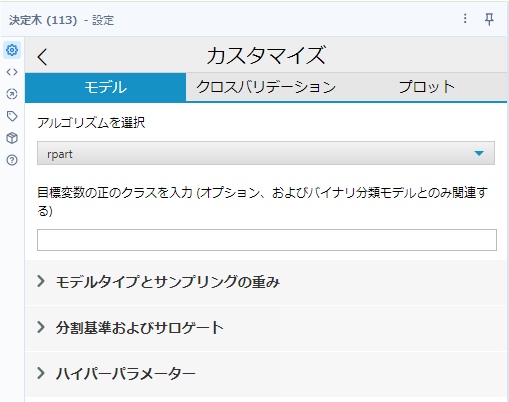
アルゴリズムとしては、rpart(recursive partitioning)とC5.0が選択できますが、回帰の場合は自動的にrpartとなります。以下はrpartを選んだときのオプションです。
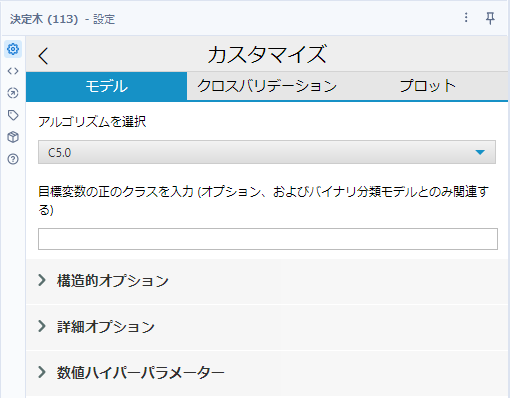
以下はC5.0を選択したときのオプションです(分類のみしかできないアルゴリズムです)。
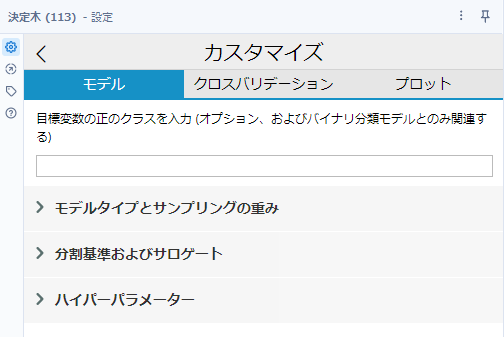
回帰の場合は以下のようにアルゴリズムの選択ができません。
それぞれ個別に見ていきましょう。
rpart(recursive partitioning)

C5.0

クロスバリデーションタブ
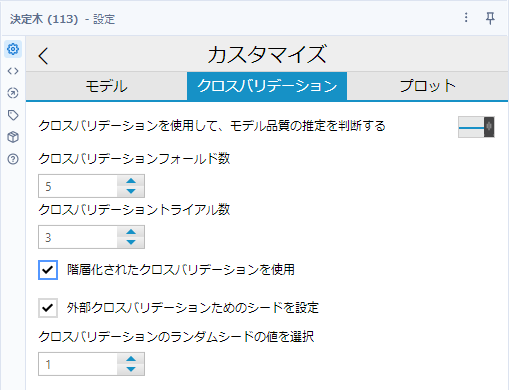
クロスバリデーションフォールド数
クロスバリデーションでデータを分割する際の折り返しの数です。値が大きいとモデルの品質はあがりますが、小さい方が高速に動作します。
クロスバリデーショントライアル数
クロスバリデーションを繰り返す回数を設定します。フォールドは各トライアルごとに異なる方法で選択され、全体的な結果はすべての試行の平均となります。トライアル数も多いほどモデルの品質はあがりますが、小さい方が高速に動作します。
階層化されたクロスバリデーションを使用(stratified cross-validation)
層化交差検証は、ターゲット変数が偏っているような場合に、オンにします。例えば、Yesが60でNoが40であれば、交差検証の際のサンプルの選び方として、トータルでの割合と同じようになるようにデータを選択します。
外部クロスバリデーションのためのシードを設定
ランダムシード値を固定することができるようにします。
クロスバリデーションのランダムシードの値を選択
ランダムシード値を固定して指定することで、他のワークフローでも同様ものが作られます。
プロット
決定木では、おそらくみなさんが期待しているツリープロットがデフォルトでは出ない設定になっているので見たい場合は変更しなければなりません。「静的レポートを表示」にはチェックが入っていますが、ツリープロットとプロットのプルーニングにはチェックが入っていないので、必要に応じてチェックを入れてください。
結果を読み解く
レポートもアルゴリズムごとに異なります。
rpart(recursive partitioning)
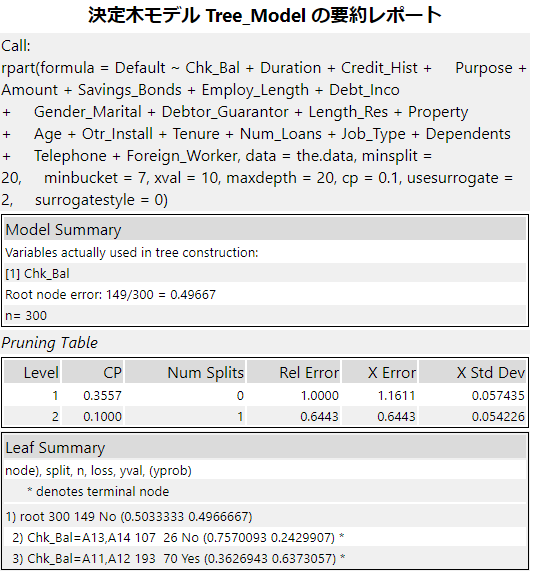
Call(呼び出し)
Rのrpart関数を内部で呼び出しています。呼び出す場合のR関数のオプションはここで確認することができます。
Model Summary(モデル概要)
実際に使用された予測変数と最初のノードでのエラー率が出力されます。
この場合は、使用したフィールドは「Chk_Bal」で、最初のノードのエラー率は149÷300で49.667%ということになります(レコード数は300)。
Pruning Table(剪定テーブル)
複雑な条件づけ(ツリーが深い状態)を行うとエラー率は限りなく低くなりますが、過学習(オーバーフィッテイング)してしまいます。つまり、汎用性が低くなり、新しく来たデータに対してのモデルのあてはまりが逆に悪くなる可能性があります。これを防ぐために、木の剪定(プルーニング)を行います。
- Level:ツリーの深さ
- CP(Complexity Parameter):複雑度パラメータ
- Rel Error(Relative Error):1-R2 Root Mean Square Error
- X-Error:クロス検証エラー
- X Std Error:クロス検証エラーの標準偏差
Leaf Summary(リーフサマリー)
各ノードの詳細です。分割に使われた予測変数と分割のしきい値、ターゲット変数が分割された割合が出力されています。
ツリープロット
ツリープロットはオプションのため、「プロット」タブの「ツリープロット」の「ツリープロットの表示」にチェックを入れないと表示されません(サンプルワークフローではチェックが入っていますが、デフォルトではオフになっています)。
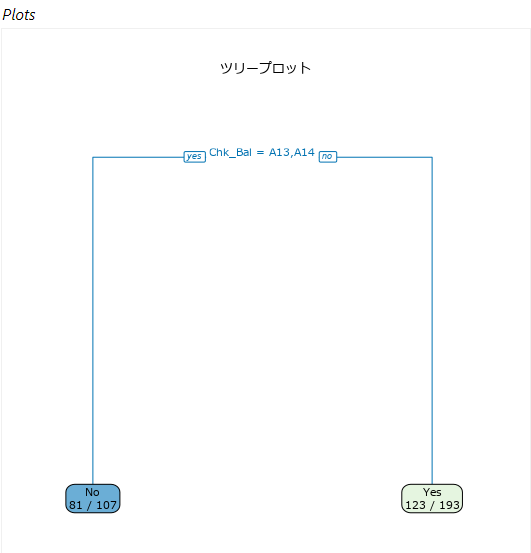
ツリープロットには、ノード、ブランチ、リーフが図示され、各ノードで使われている予測変数としきい値が表示されています。この例では、Chk_Balの値がA13またはA14かどうか、ということを判断して分岐しています(ちなみに、20フィールドを予測変数として選択しましたが、実際に使われたのはChk_Balのみとなります)。
プルーニングプロット
プルーニングプロットもオプションのため、「プロット」タブの「プロットのプルーニング」の「プルーンプロットを表示」にチェックを入れないと表示されません(サンプルワークフローではチェックが入っていますが、デフォルトではオフになっています)。
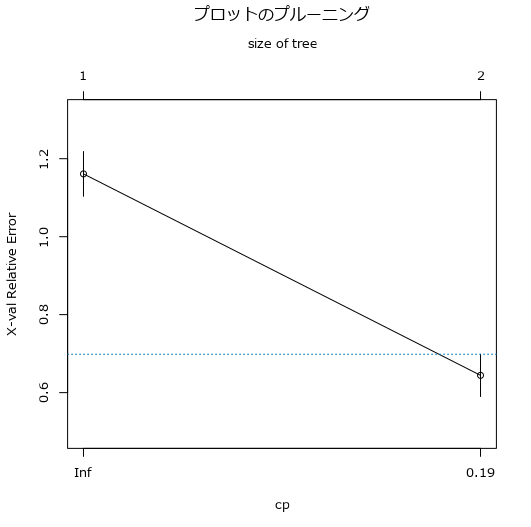
これは、交差検証されたエラーの概要を示しています。プルーニングテーブルをグラフ化している形となりますが、横軸がプルーニングテーブルの行に該当します(レベル、つまりツリーの深さ)、縦軸は、X Errorの値をプロットしています。
青い破線は、最大の交差検証誤差から最小の交差検証誤差を引いた値に、そのツリーでの誤算の標準偏差を加えたものです。この青い破線よりX Errorが低いノードは剪定の対象となります(つまり、レベル2のツリーが削除されており、最終的にはレベル1のみのツリーとなっています)。
C5.0
C5.0は、サンプルワークフローだとレポートが長くなるので、Irisデータを使った結果のレポートにしています。

Call:
C5.0.formuraという関数をRで呼び出しています。詳細なオプションもここで確認できます。使用されたアルゴリズムのバージョンや実行日も出力されています。

続きは、出力結果となります。Read 150 casesと記載ありますが、cases=レコード数です。attributesというのは予測変数の数なので、5つの予測変数を入力として使っています。
13行目のDecision tree以降は作成されたツリーです。
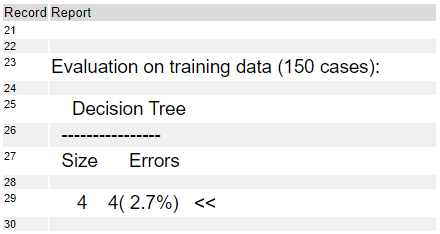
Evaluation on training data以降はトレーニングデータを分類した結果です。このツリーでは、サイズが4、エラーは4レコード(2.7%のエラー率)でした。これは、4レコードが正しくラベル付けできなかったことになります。

32行目~36行目は混同行列です(グラフとか表で見たいところですね・・・)。
Timeは、モデル作成にかかった時間です。小数第二位以下だったようで、0.0Secと出ています。
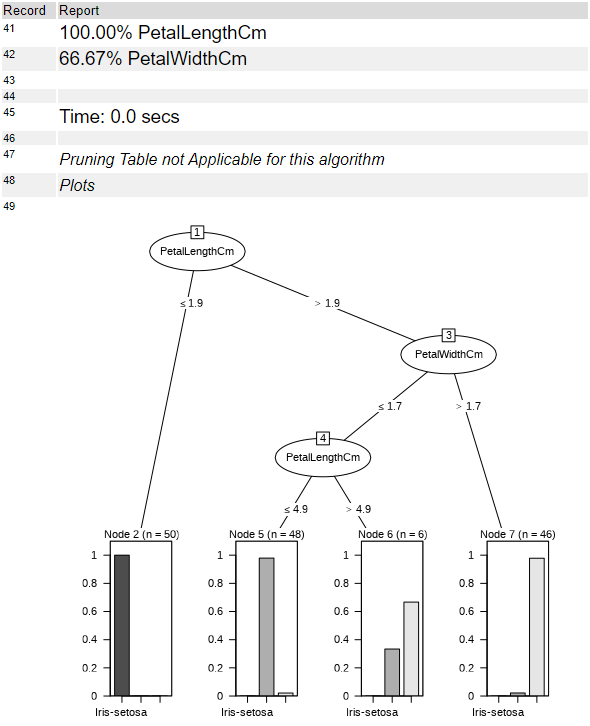
プロットオプションでツリープロットを表示にチェックを入れると、プロットが出てきます。このプロット図が決定木モデルを説明可能なモデルとして非常にわかりやすくなっている理由です。
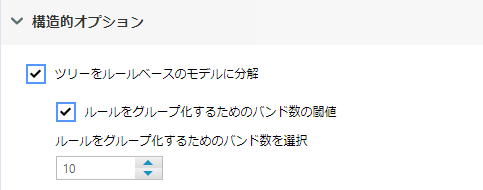
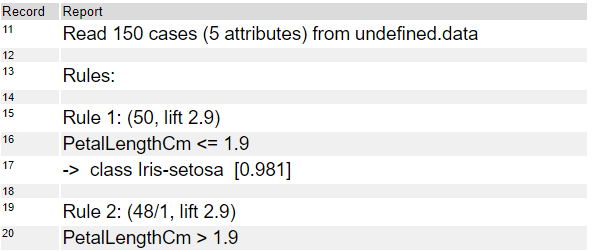
なお、このプロットは、モデルの「構造的オプション」にて「ツリーをルールベースのモデルに分解」にチェックを入れると出てきません。代わりに、上のレポートのDecision Tree(13から20行目)が出力されず、以下のようなレポートが出力されます(Rulesの13~33行目まで)。


なお、決定木モデル同士で性能比較する場合は、I出力のレポートにて正解率などで行いましょう。
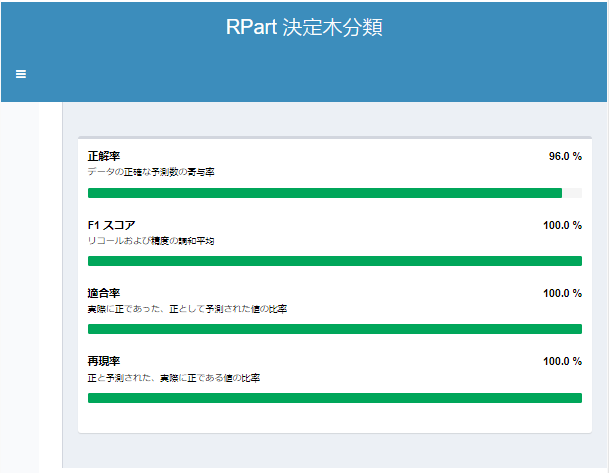
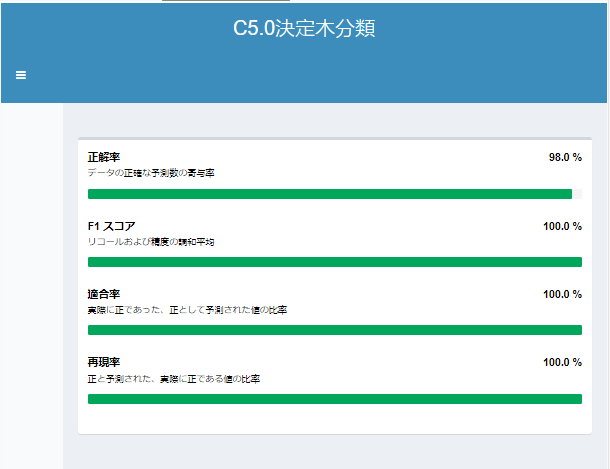
ランダムフォレスト(Forest Model)

ランダムフォレストモデルは、決定木を複数組み合わせたアンサンブル学習という手法で作られたモデルです。同じトレーニングデータから大量の複数の決定木を作るわけですが、バギングと呼ばれる手法で行われます。すなわち、元のトレーニングデータをサンプリングすることで新しいトレーニングデータを作ります。つまり、各決定木は異なるトレーニングデータでトレーニングされるということになります。
ランダムフォレストモデルの特長は以下のとおりです。
- 高い予測性能
- 過学習を避けやすい
- 予測変数の重要度を算出できる
- 予測変数の正規化や標準化が不要
欠点は以下の通りです。
- メモリを多く消費する
- モデルの解釈が難しい
- データ量が少ないと機能しにくい
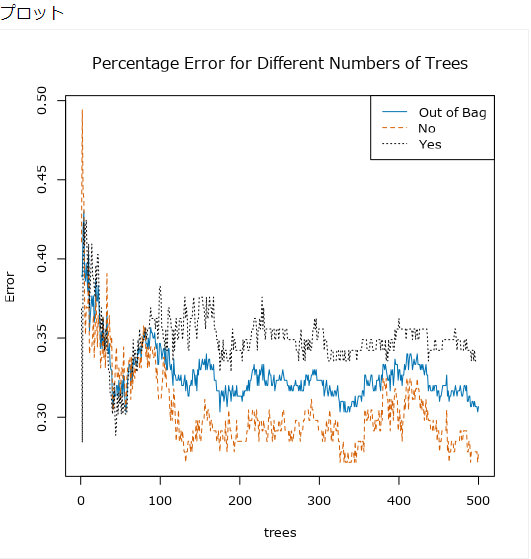
使い方のポイントとしては、使用するツリー数の最適値を探ることでしょうか。一度ランダムフォレストでモデルを作成し、「Percentage Error for Different Numvers of Trees」のグラフを見てエラー率が収束してなければ、使用するツリーの数を増やします(Max1000までいけるので、一度1000で実行して良いのではないかと思います)。収束していれば、収束したツリー数に変更してしまいましょう。
設定
必須パラメーター
基本的な設定である、モデル名の入力、ターゲット変数の選択、予測変数の選択に加えて、ランダムフォレストでは、使用するツリーの数と各分割感で選択する特定の変数の数の選択するかどうか、という設定項目があります。
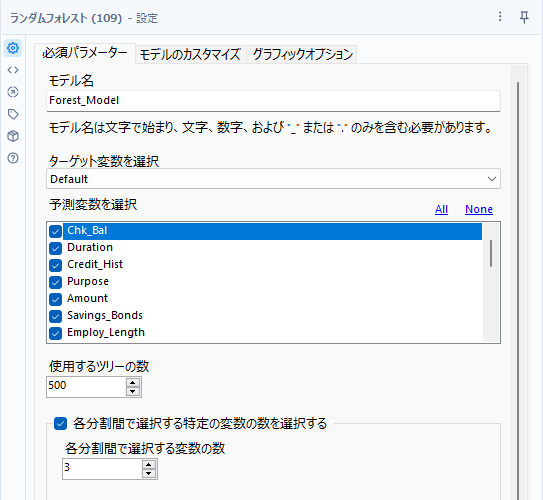
使用するツリーの数
基本的には木の数が多いほうが結果が改善されますが、多すぎるとオーバーフィッテイングすることがあります。ツリー数の適切な決定は、レポートの「Percentage Error for Different Numbers of Trees」を見ると、ツリーの数ごとのエラー率が表示されています。このエラーが安定したところが最適なツリーの数となります。つまり、一度実行してみなければ適切なツリーの数はわかりません。
サンプルワークフローだといまいちだったので、Irisデータを使ってみてみましょう。ツリーの数を1000にすると以下のようなグラフが描かれます。
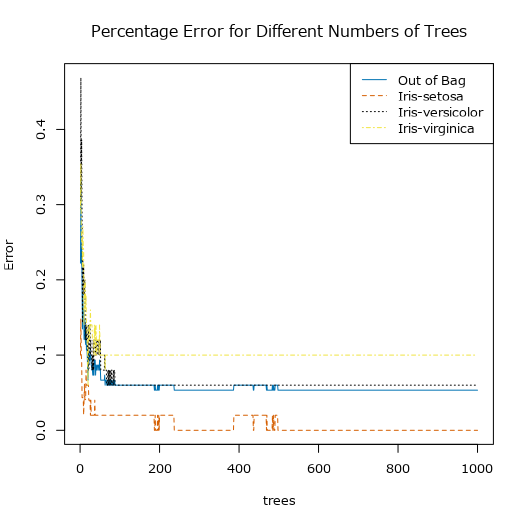
500くらいでエラー率が一定になり収束していることがわかるので、500で設定してかまわないと思います。ちなみに、最大値は1000となります。
各分割間で選択する特定の変数の数を選択する
各決定木を作る際に、予測変数もランダムにサンプリングされています。この時に選択される予測変数の数を指定できます。設定しない場合は、分類の場合、予測変数の数の平方根となり、回帰の場合は、予測変数の数を3で割った数となります。
モデルのカスタマイズ
他のツリー系のモデルに比較すると、細かいカスタマイズはそれほどできません。
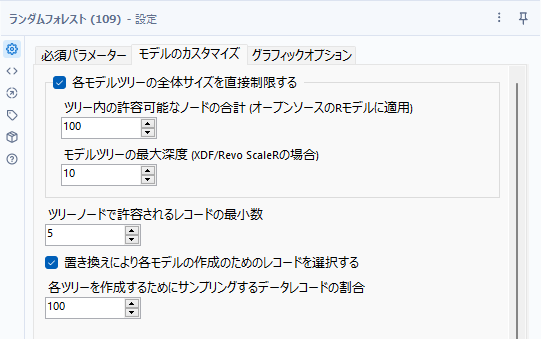
各モデルツリーの全体サイズを直接制御する
個々の決定木の構成可能なノードの最大数を制限します。オプションとして2つのオプションが設定可能に見えますが、使用しているパッケージによって項目が異なるからですが、本質的には同じ機能となります。上側の「ツリー内の許容可能なノードの合計」は、通常のランダムフォレストモデルの場合に使用します。下側の「モデルツリーの最大深度」は、In-DBのランダムフォレスト(MicrosoftのSQL Server)の場合に機能します。
ツリー内の許容可能なノードの合計
各ツリーを構成できるノードの総数を指定します。通常のランダムフォレストツールで使用します。
モデルツリーの最大深度
ツリーを構成できるノードの数に上限を設定します。In-DBのランダムフォレスト(MicrosoftのSQL Server)の場合に使用します。
ツリーノードで許容されるレコードの最小数
デフォルト設定は5ですが、これはツリーの各ターミナルノードに最低5個のレコードが最終的に収まっている必要がある、ということです。
値を増やすと、各ツリーのトータルのノード数は全体的に減少します。
このオプションと「各モデルツリーの全体サイズを直接制御する」は決定木のサイズを手動で制限する方法です。
置き換えにより各モデルの作成のためのレコードを選択する
ブートストラップのサンプリングを置換「あり」、または「なし」にするか、というのを指定できます。
デフォルトでは置換を使用してサンプリングされます。置換によるサンプリングは、バギングの重要な要素なので、このオプションの選択は慎重に行う必要があります。
各ツリーを作成するためにサンプリングするデータレコードの割合
各ブートストラップの複製の作成に、フルのトレーニングデータセットかデータセットのランダムなサブサンプルのどちらを使用するかを制御できます(デフォルトでは100なので、フルのトレーニングデータセットが使われます)
結果を読み解く
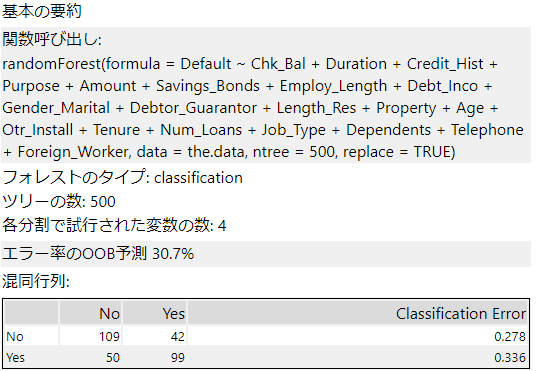
基本の要約
関数呼び出し
ランダムフォレストモデルは、RのrandomForest関数を呼び出しています。
フォレストのタイプ
ターゲット変数が分類か回帰か、自動的に選択されたものが表示します。ここでは分類のため「classification」となっています。
ツリーの数
指定したツリーの数です。
各分割で施行された変数の数
バギングで採用される予測変数の数ですが、指定していない場合は自動で計算された数となります。
エラー率のOOB予測
OOBはOut-Of-Bagの略です。ブートストラップ法でデータをサンプリングした際、選ばれなかったデータがOOBデータです。このOOBデータを用いて作成したモデルで分類した際のエラー率が「エラー率のOOBデータ予測」です。これを使ってモデルの比較などができます。
混同行列
縦軸が実際の値、横軸が予測値とし、合致するところに入るレコード数を記載したものです。これにより分類のエラーが何%か、ということをClassification Errorに出力します。
プロット
このグラフは、ツリーの数を横軸にし、縦軸にはエラー率をプロットしています。十分な数のツリーになるとエラー率が収束するので、そこでツリー数を決定できます。
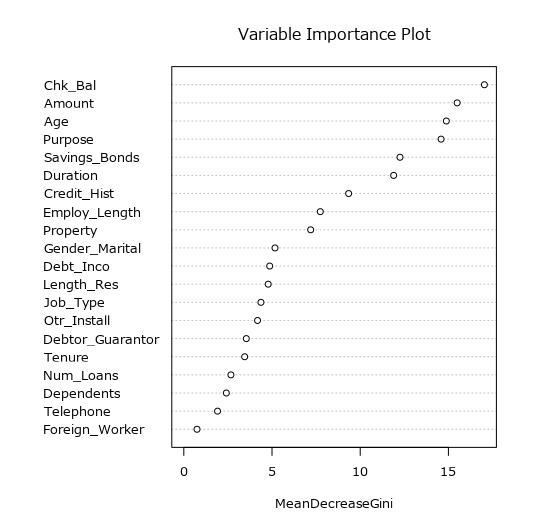
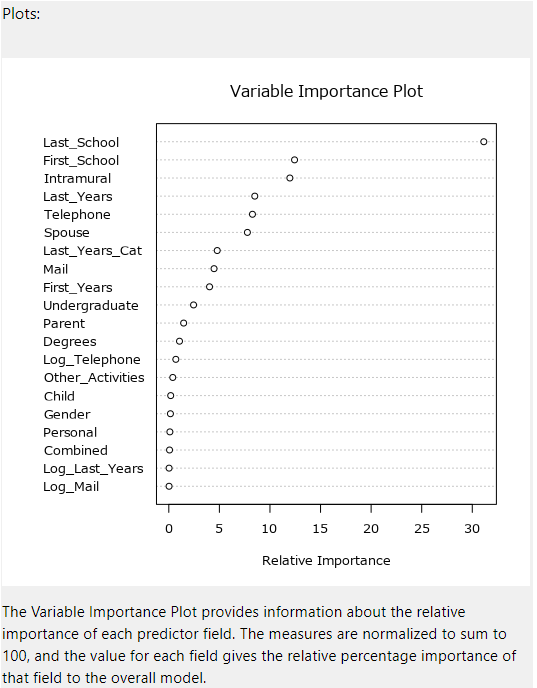
Variable Importance Plot
ジニ不純度の平均減少率を利用し、モデルに対する変数の重要度をプロットしたものです。
勾配ブースティング(Boosted Model)

アイコンの形からは決定木に関連したモデルとはわかりませんが、ランダムフォレストモデルのように複数の決定木を用いたモデルです。
ランダムフォレストと異なり、順番にツリーを作成します。ツリーを作成する際、誤って分類されたレコードに重みを付けて次のツリーを作成します。
勾配ブースティングモデルは、RのGBM(Gradient Boosting Machine)が使われています。
特長は以下のとおりです。
- 精度が高い(一般的にはランダムフォレストより高精度)
- スケール変換の必要がない
一方、以下のような悪い点もあります。
- オーバーフィッティングしやすい
- 外れ値の影響を受けやすい
設定
必須パラメーター
最低限の設定としては、「モデル名」「ターゲットフィールドを選択」「予測フィールドを選択」だけではなく、その他最低限2つのオプションの設定があります(あくまでオプションなのでデフォルト設定のままにするという手もあります)。
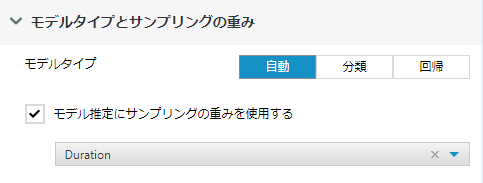
モデル推定にサンプリングの重み付けを使用しますか?
重みを付けたいフィールドがあれば設定します。
限界効果(marginal effect)プロットを含めますか?
1つの変数を分離して、その変数のどの値がターゲット変数に対して最も予測的であるかを検査するためのプロットです。これは、予測変数が予測因子としてどの程度役に立つかを決定するのに利用できます。
「プロットに含めるフィールドの最小重要度」は、レポートの「Variable Importance Plot」の重要度(Importance)を見て、ここで指定した数値以上の重要度の予測変数のみレポートの最後の「Marginal Effect Plot」として出力します。
モデルのカスタマイズ
ターゲットの種類と損失関数分布を指定
基本的には、自動的に損失関数分布は選択されますが、回帰の場合、小数点を含む場合は連続ターゲットから選択、整数値であればカウントターゲット、分類の場合は、バイナリと多項式でそれぞれ選択が可能です。
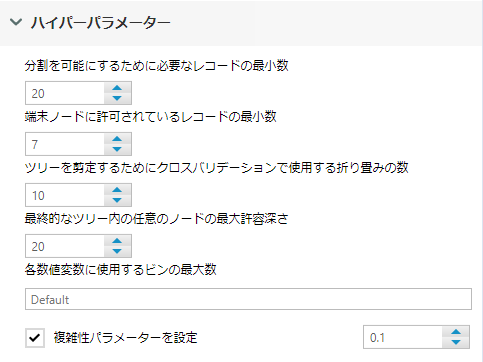
モデル内のツリーの最大数
レポートのBasic Summaryにて「Warning」が出ている場合はここのツリー数を増やしましょう。最大10000ツリーまで増やすことができます。
結果を読み解く
Basic Summary

Loss function distribution(損失関数の分布)
デフォルトでは自動で決定される損失関数の分布ですが、ここではベルヌーイ(Bernoulli)が選択されています。今回のデータは二値予測なので、ベルヌーイもしくはAdaBoostから選択されます。
Total number of trees used(使用したツリーの総数)
オプション「モデル内のツリーの最大数」で設定したツリーの総数です。
Best number of trees based on 5-fold cross validation
k-foldクロスバリデーションに基づいた最良のツリー数を表示していますが、このサンプルでは「Warning」が出ている通り4000のツリーでは頭打ちになっているようです。10000までツリー数を増やしたところ、9476が適していると出力されました(さすがに1万ツリーはちょっと実行に時間がかかります)。
Variable Importance Plot
こちらはランダムフォレストモデルにあるものと同様です。
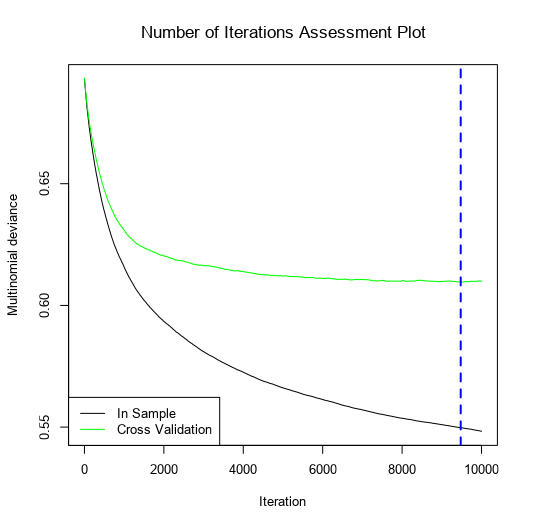
Number of Iterations Assessment Plot(反復回数評価プロット)
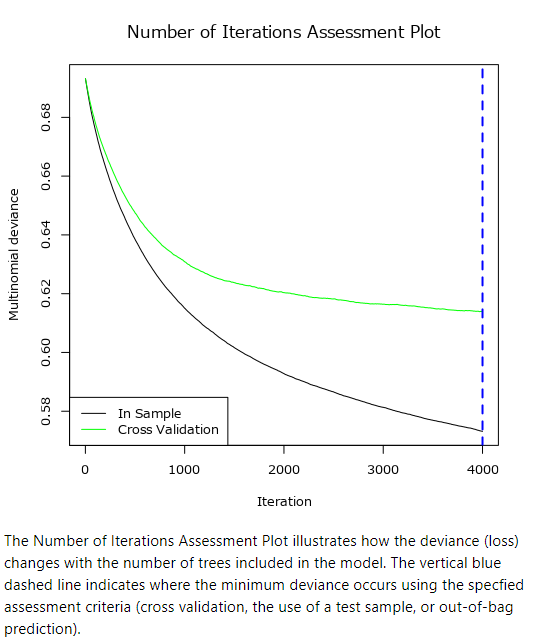
モデルに含まれるツリーの本数で損失がどのように変化するかを示しています。青色の破線は、クロスバリデーション、テストサンプルやOOB予測による評価基準で最初の偏差が発生する場所を示しています(つまり、最良のツリー数です)。
サンプルワークフローでは4000ツリーで頭打ちになっているので、10000までツリーを増やしたものの結果が以下のとおりです。
Marginal Effect Plot(限界効果プロット)
必須パラメータの設定の「限界効果プロットを含めますか?」にチェックを入れると、以下のような限界効果プロットが各予測変数に対して出力されます。
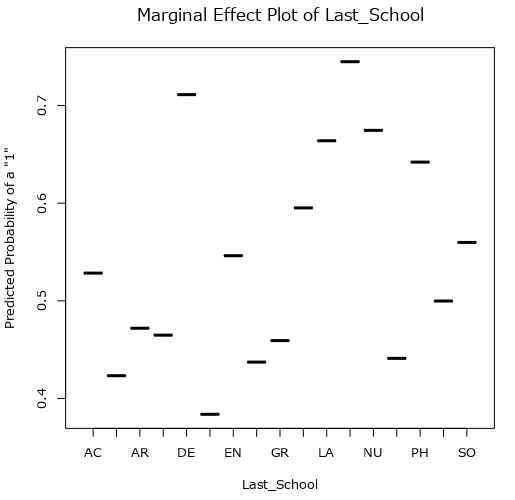
ここでは、Last_Schoolという予測変数に対して、ターゲット変数が1になる可能性をプロットしています。
参考URL
Alteryxのツールマスタリーシリーズです。
Alteryxのナレッジベースです。決定木について詳細が書かれています(コメント欄が充実しています)
Alteryxのナレッジベースです。決定木のレポートについての解説が書かれています。
細かい設定、特にアルゴリズム(rpartかC5.0か)について詳細に記載されています。
交差検証について書かれています。
Alteryxのツールマスタリーシリーズです。ランダムフォレストの記事です。
Alteryxのナレッジベースです。ランダムフォレストの紹介の記事です。より詳しいメカニズムについて書かれています。
勾配ブースティングモデルについてのブログです。
コメント