
Alteryx Predictive Master資格取得を目指すシリーズです。
今回は、タイトルの通り予測変数を削除すべきなのか、すべきでないのかを調べる方法をご紹介します。
これを行うには、「F検定ツール(Nested Test)」を使います(昔は「入れ子型仮設テスト」ツールって名前だったと思うのですが、いつの間にか名前変わりましたね・・・)。
なお、F検定ツールは、線形回帰ツールのサンプルワークフローに一緒に入っています。
F検定ツールの使い方

このF検定ツール(過去のツール名は入れ子テストとなっていましたが、アイコンだけ見るとたしかにマトリョーシカ的な入れ子って感じですね)は、入力を3つ持ちます。
実は、この3つの入力は等価で、以下の3つをそれぞれ入力するのであればどこに接続しても問題ありません(サンプルワークフローだとLが縮小モデル、Cがフルモデル、Rがトレーニングデータですが入れ替えても動作します)。
- フルモデル
- フルモデルから予測変数を削除した「縮小」モデル
- モデル作成の際に使用したデータストリーム。縮小モデルもフルモデルも同じデータを使ってトレーニングする必要があります
なお注意点として、本ツールはGLMファミリーモデル(線形回帰、ガンマ回帰、ポワソン回帰、ロジスティック回帰)のみに対応しています。※2023/11/23追加
実際に使ってみる
削除して影響がない例
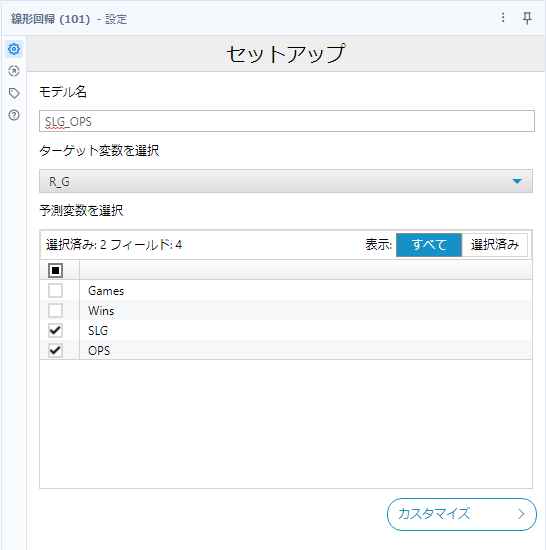
それでは実際に使ってみたいと思います。ワークフローとしては、線形回帰ツールのサンプルワークフローをベースに見やすく項目を絞りました(使っていない項目をセレクトツールで落としました)。
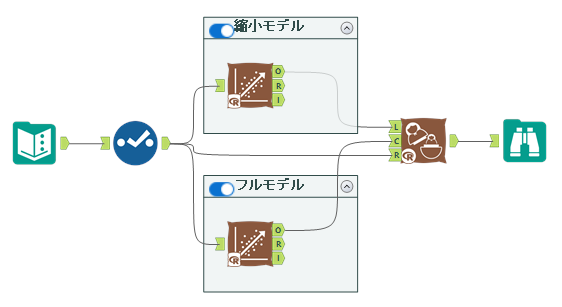
フルモデルの設定は以下のとおりです。
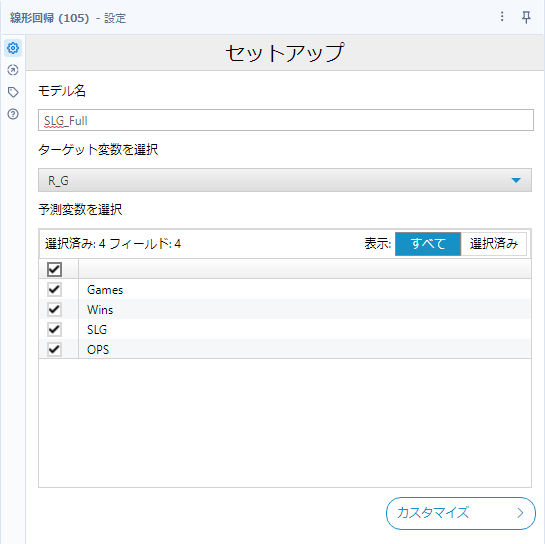
以下のフィールドを予測変数として選択しています。
- Games
- Wins
- SLG
- OPS
ここで、フルモデルのレポートの係数を見てみます。
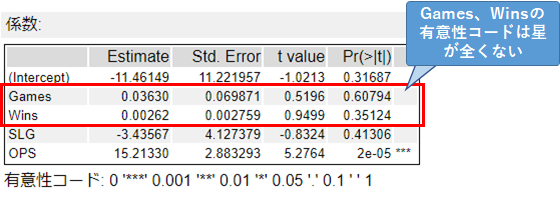
Games、Winsは有意性コードに星がついていません(P値が0.05より大きいです)。つまり、このモデル内でGames、Winsという予測変数はあまり意味をなしていません(ちなみに、SLGという予測変数も同様です)。
縮小モデルは上のフルモデルからGamesとWinsを外しています。
この結果に対して、F検定ツールの結果を見てみましょう。

タイトル上で、削除した変数がちゃんとリストアップされています(今回は、GamesとWins)。さて、肝心の中身ですが、有意性コードに星がありません。P値としては0.52736ということで、有意水準である0.05よりかなり大きな値となり、有意ではありません。比較自体はF値で行われています(線形回帰ツールのため)。
このツールは「フルモデルで追加されている予測変数による改善効果が、縮小モデルと同じ=役に立っていない」という帰無仮説を設定しており、F検定ツールの結果が有意であれば、「役に立っていないことが間違い」ということになるので、帰無仮説が棄却され「フルモデルで追加されている予測変数が、縮小モデルに対して役に立っている」ということになります。つまり、削除すると精度が落ちる、ということになります。
今回は、帰無仮説が棄却できなかったので、縮小モデルとフルモデルが同じであることを否定できていないので、削除しても大きな違いはない、ということになります。
実際フルモデルと縮小モデルのレポートを見てみましょう。まずはフルモデルです。

次に縮小モデルです。

調整済みR二乗を見ると、0.9128と0.915であまり大きな違いはありません。確かにこれなら削除しても大きな影響はなさそうです。
削除して影響がある例
次に、ポアソン回帰ツールで見てみましょう。
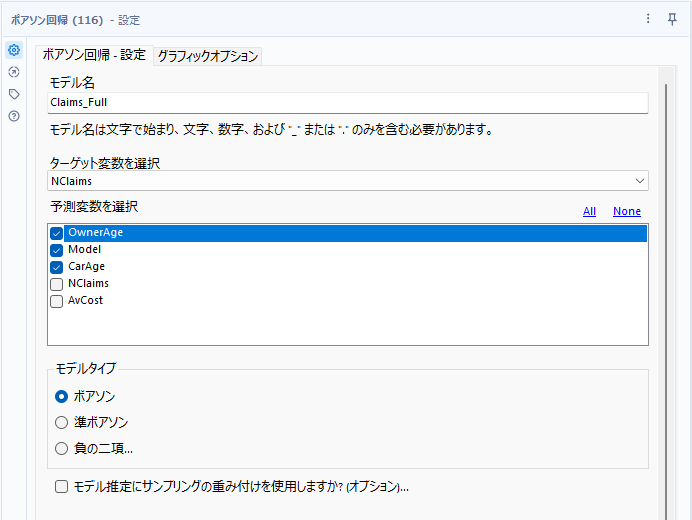
フルモデルの設定は以下のとおりです。OwnerAge、ModelとCarAgeにチェックが入っています(いずれの予測変数もカテゴリ変数です)。
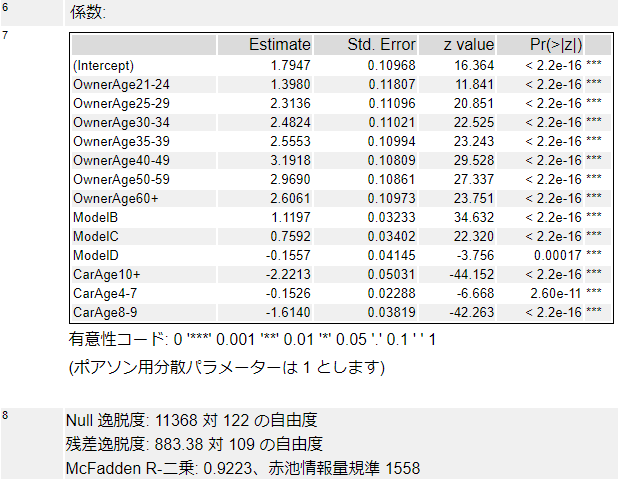
これのレポートは以下の通りで、P値を見るとすべて重要な項目となっています。
縮小モデルはこちらです。CarAgeを削除し、OwnerAgeとModelの2つの予測変数を採用しています。
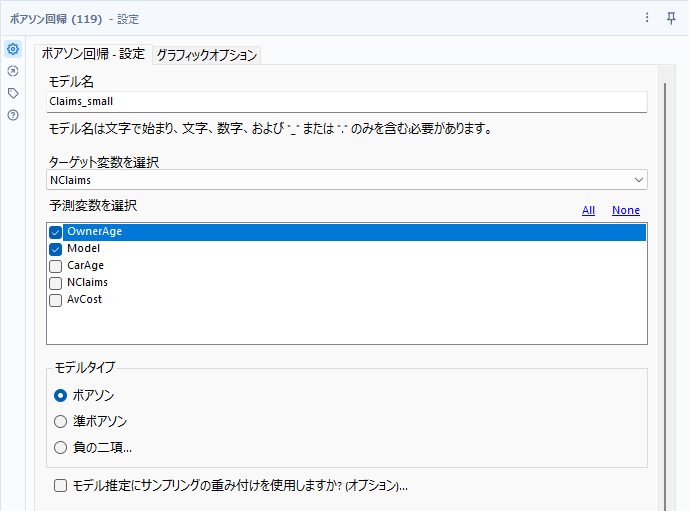
このレポートは以下のとおりです。
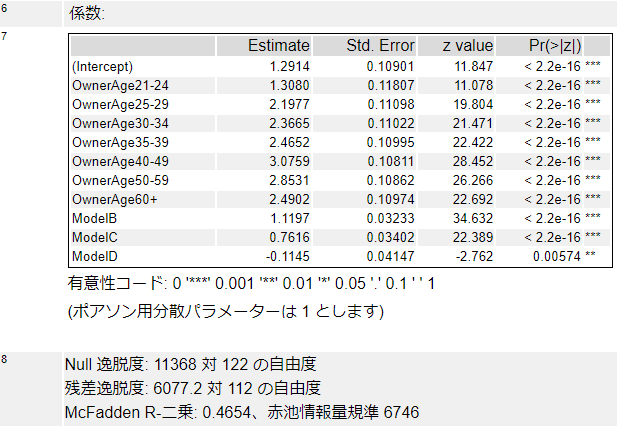
マクファーデンR二乗を比較すると、フルモデルは0.9223、縮小モデルは0.4654で大きな差があります。赤池情報量規準も、フルモデルは1558、縮小モデルは6746と大きく異なっており、フルモデルのほうが精度が良さそうです。
これにF検定ツールを適用してみましょう。
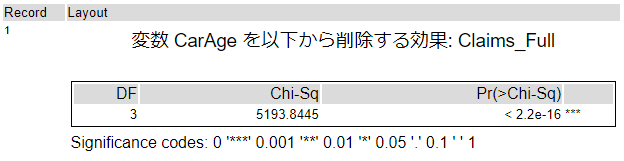
予測変数CarAgeを削除すると、統計的に有意に差があることがわかります(有意性コードは星3つです)。つまり、帰無仮説が棄却され、CarAgeは役に立っている、ということになるので削除はできない、ということになります。
なお、ここでは回帰モデルがGMLファミリ(ポアソン回帰)のため、検定は尤度比検定(likelihood ratio test)で行われています。
参考
まさにこのツールを使った問題がこちらのDesigner Expertの過去の試験問題です。予測というだけで色々とわからないのにさらにF検定ツールとかなかなかの高難易度ですね!
コメント