
Alteryx Predictive Master資格取得を目指すシリーズです。
Alteryxで様々なモデルを使って学習を行う方法について紹介してきましたが、いよいよ学習したモデルで予測する方法をご紹介したいと思います。
とはいっても、予測自体は非常に簡単で、スコアリングツールを使って予測を行います。
一点注意としては、インテリジェンススイートで利用できる各種ツール(機械学習カテゴリ、テキストマイニングカテゴリ、コンピュータービジョンカテゴリ)のツールは機械学習カテゴリに入っている「予測」ツールを使う必要があります。また、時系列カテゴリのツールは、時系列予測ツールを使います(詳細はこちら)。
スコアリングツール(Score)

スコアリングツールは、2つの入力を持っています。D入力は予測したいデータ、もう一方のM入力は学習済みのモデルを入力します。
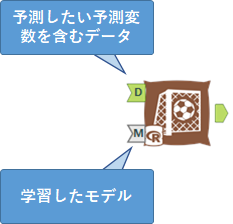
つまり、以下のように接続を行います。
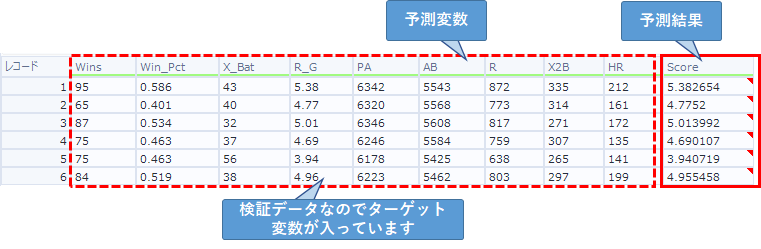
予測結果は以下のように出力されます。
設定
基本的にはほぼデフォルト設定で使用することができますが、一部のケースで設定が必要となります。
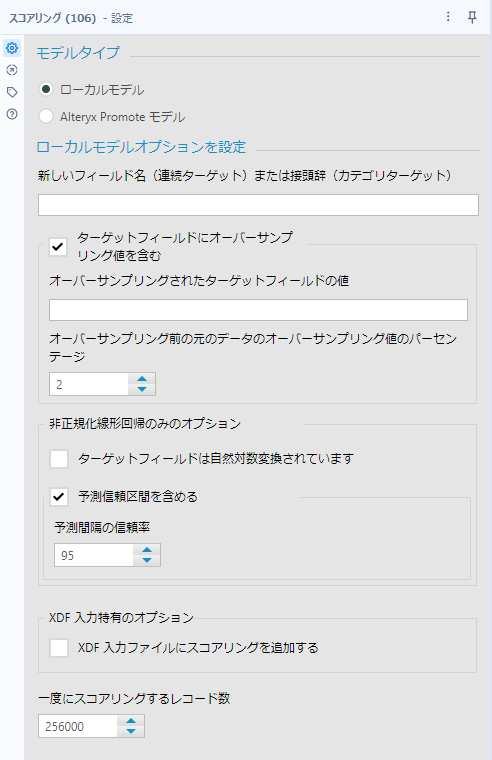
モデルタイプ
モデルタイプは「ローカルモデル」と「Alteryx Promoteモデル」から選択が可能です。通常はローカルモデルを使用します。Promoteというプロダクトを使用する場合のみ「Alteryx Promoteモデル」を選択してください。
新しいフィールド名
予測結果を出力するフィールド名を指定可能です。デフォルトでは空白で、空白の場合、回帰モデルでは「Score」というフィールドを生成します。分類モデルでは、「Score_(ターゲット・フィールドの値)」を複数生成します。
例えば、以下のようなものです。
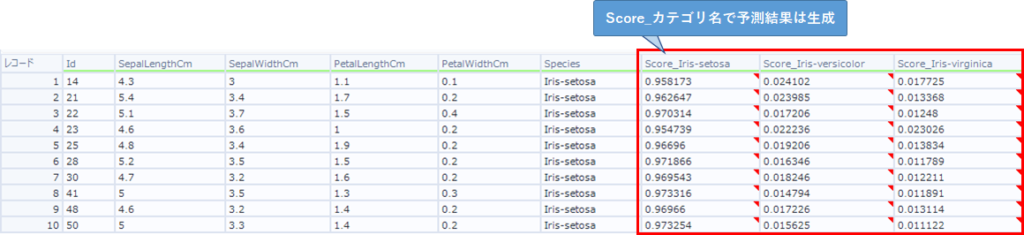
なお、モデル名は文字、数値、特殊文字として「.(ドット)」「_(アンダースコア)」を利用可能です。カッコなどの文字は使用することができません(自動的に置き換えられます)。なお、日本語は使用できません。
ターゲット・フィールドにオーバーサンプリング値を含む
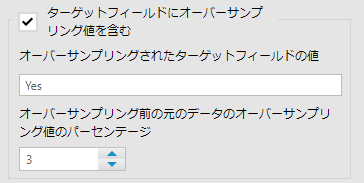
ターゲット・フィールドをオーバーサンプルフィールドツールでアンダーサンプリングしている場合に選択します。値としては2~75までの数値を指定することが可能です。
その場合、「オーバーサンプリングされたターゲットフィールドの値」は、オーバーサンプルフィールドツールで指定した値を入力します。例えば、オーバーサンプルフィールドツールで「Yes」と入力していれば、同様に「Yes」と入力します。
また、「オーバーサンプリング前の元のデータのオーバーサンプリング値のパーセンテージ」は、オーバーサンプルフィールドツールを適用する前の(上の例で言えば)「Yes」の割合を入力します(例えば、30%の場合、3と入力します)。※直感的になぜ10分の1なのか理解できないですが・・・ここはTool Masteryを信じています・・・。
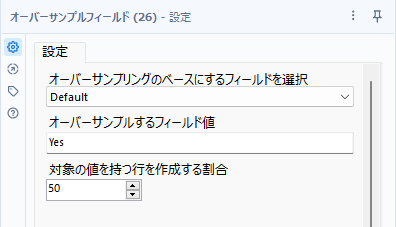
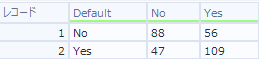
実例を見てみたいと思います。ロジスティック回帰のサンプルワークフローになりますが、入力データの「Default」というフィールドがターゲット変数ですが、Yesという項目が全体の30%、残りがNoで70%という項目となっており、ターゲットフィールドの値が偏っています。これをオーバーサンプルフィールドツールで、比率を合わせていくには、以下のような設定となります(「対象の値を持つ行を作成する割合」は、ツール実行後のデータの割合です)。
これに対して、スコアリングツールで「ターゲットフィールドにオーバーサンプリング値を含む」オプションを利用した場合としない場合の結果を見たいと思います。
それぞれの混同行列を見てみましょう。縦軸が実測値、横軸が予測値です。
まず、オーバーサンプリング設定無しです。
次に設定ありです。設定としては以下のとおりです。
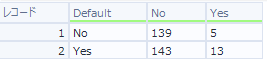
これらの、正解率(Accuracy)、適合率(Precision)、再現率(Recall)、特異度(Specificity)、F値(F-measure)を計算して比較すると以下のようになります。

これを見ると、逆に「オーバーサンプリング値を含む」設定を入れた方が悪くなっているので、入れないほうがいいのでは?という気になりました・・・。
非正規化線形回帰のみのオプション
これは、線形回帰ツールでモデルのカスタマイズの正則化回帰を使用した場合は適用されないオプションです。
ターゲット・フィールドは自然対数変換されています。
回帰ツールのターゲット・フィールドが自然対数変換したものでモデルを構築していた場合、結果を元に戻す必要がありますが、それを自動でやってくれるオプションです。

サンプルワークフローによると「Oracle R Enterprise」モデルにのみ適用されると記載がありますが、そんなことはないですね・・・(Tool Masteryではそのような記載はありません)。
予測信頼区間を含める
チェックを入れると、予測信頼区間を指定し、その値を含めることが可能です。予測信頼区間としては1~100の間の値を指定可能です。
95を指定した場合以下のような値となりました。fitが通常の予測値、lwrが下方向の95%値、uprが上方向の95%値です。
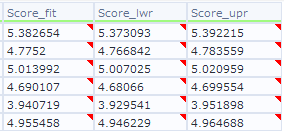
一度にスコアリングするレコード数
ここで指定したレコード数を一括で処理するようになっています。Rのメモリ制限を回避するための設定です。エラーが出るような場合は値を小さくしてください。
予測を実運用で使う場合のワークフローの組み方
使い方は非常に簡単なスコアリングツールですが、実際の業務に組み込む場合はちょっとした注意点があります。
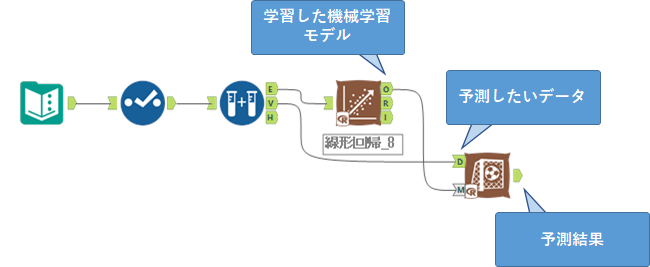
スコアリングツールの使い方として、M入力に学習済みモデル、D入力に予測したいデータを入れる、というお話をしましたが、このままで実際の業務に利用すると非常に無駄が多いです。つまり、毎回同じトレーニングデータを毎回学習させても意味は無いので、学習した機械学習のモデルは一度yxdb形式で保存するのが普通です。そして、実際に利用する際はそのyxdb形式のモデルを利用すれば、学習する時間を省くことができます。
つまり予測モデルを作る際は以下のようなワークフローになりますが、
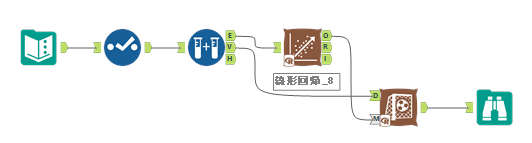
これに、以下のように線形回帰ツールのO出力にデータ出力ツールを追加し、yxdb形式で保存しましょう。
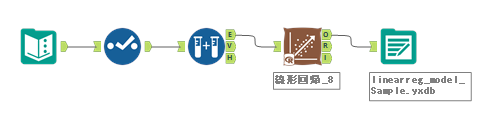
そして、この保存したyxdb形式のモデルを予測専用ワークフローとして、利用するようにしましょう。
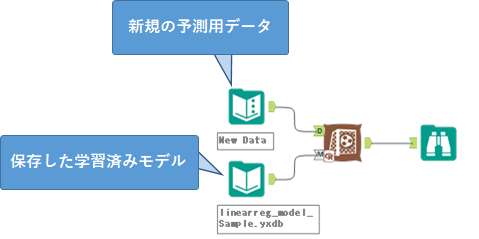
例えば、学習も予測も含んだワークフローの場合、実行に9秒かかっています。これを、学習専用と予測専用に分けることで、予測用のワークフローからは4秒で結果が出てくるようになりました。今回は規模が小さいですが、規模が大きくなってくると待ち時間もばかになりません。
参考
ツールマスタリーシリーズです。
ナレッジベースの記事です。
コメント