
Alteryx Predictive Master資格取得を目指すシリーズです。
予測データに、どの機械学習モデルがフィットするのか、機械学習モデルのチューニングをする際など、モデル間の比較が必要です。同じモデルのチューニングであれば、出力されるレポートを見て比較することもできますが、異なるモデル間だと出力される指標なども異なるため比較が困難な場合もあります。
Alteryxでモデル比較をする場合、モデルを比較する専用のツールがあるので、それを使って便利に比較を行うことができますが、いずれもAlteryx CommunityのGalleryからダウンロードする必要があります。
モデル比較のツールとしては以下を利用可能です。
- リフトチャートツール
- モデル比較(Model Comparison)ツール
- クロスバリデーション(Cross Varidation)ツール
いずれも、どのモデルを採用するか、採用したモデルに対してのハイパーパラメータを変えた時のモデル選定、といった用途でモデルの比較が可能です。
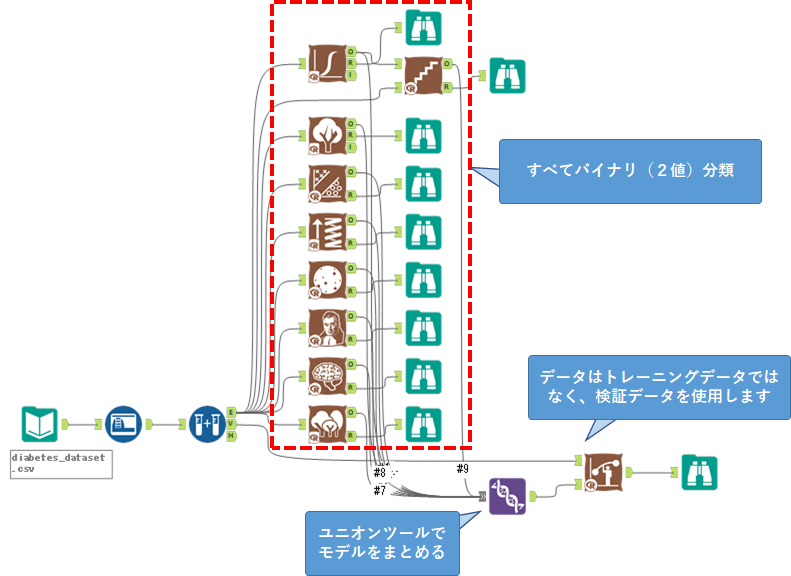
リフトチャートツールは、バイナリクラス(2値)分類しか利用できません。また、比較する際の項目が少ないです。
モデル比較ツールとクロスバリデーションツールの大きな違いとしては、モデル比較ツールは、モデルの比較にインプットデータとして検証用のデータを使いますが、クロスバリデーションツールの場合はインプットデータとしてトレーニングデータを使用します。そのため、汎化性能を見るのであれば、モデル比較ツールが適しています。
三種類ありますが、基本的にはモデル比較ツールが一番お手軽かつ汎用性が高いかと思います。
リフトチャートツール

リフトチャートツールは、ロジスティック回帰ツールのサンプルワークフローで例が示されています。
入力として2つ持っていますが、特に使い分けはありません。入力が必要なものは、検証用のデータと、2値分類で学習したモデルです。
例えば、以下のようなワークフローになります。
設定
まず、リフトチャートツールは、「総累積応答」と「増分応答率」のレポートを作成することはできますが、いずれか一方しか一度に出力できないようになっています。
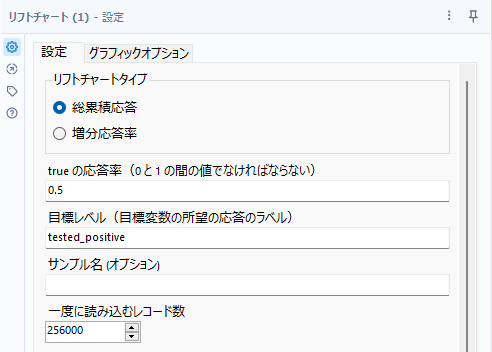
リフトチャートタイプ
総累積応答と増分応答率の2つから選択可能です。
trueの応答率
0~1の間の値を指定可能です。これは、ターゲット変数のPositive(陽性)の値の割合を記載します(アンダーサンプリングされていれば、元々のデータセット内の割合を入力)。
目標レベル
陽性(Positive)の値を指定可能です。
サンプル名
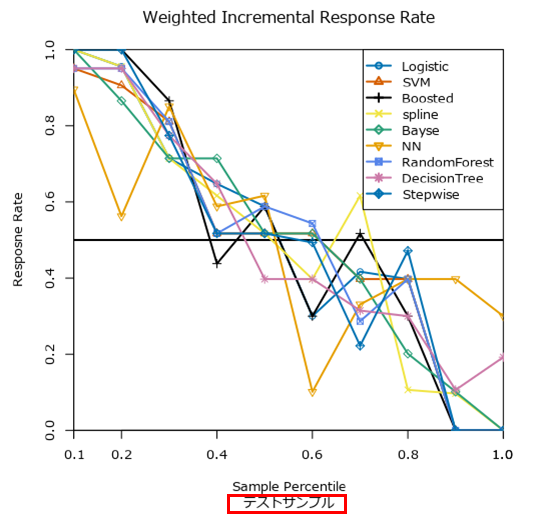
各グラフにつけるラベルを設定できます。つまり、以下のようにグラフの赤枠部分のようなラベルを付加できます。
一度に読み込むレコード数
Rのメモリ制限にひっかかるようであれば、このレコード数を変化させてひっかからないようなサイズにしてください。一般的に問題があった場合は小さくする方向です。
実際のレポートを見てみる
総累積応答レポート
総累積応答レポートは、加重累積応答グラフ(Weighted Cumulative Response Captured)とゲインテーブル(Gains Table)、リフトチャート曲線の下のエリア(の面積)およびジニ係数の3つで構成されています。
加重累積応答グラフ(Weighted Cumulative Response Captured)は、Positiveの確率順にレコードを並べ、全レコードを10分割し(10のグループを作成)、各グループでPositiveの割合を取ったものです。
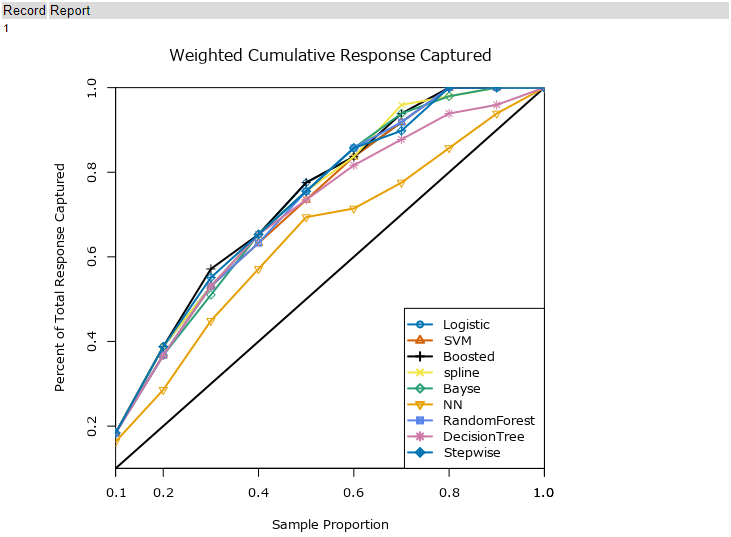
ゲインテーブルは、各モデルの累積パーセントとLift値を各レコードの割合に対して作成しています。加重累積応答グラフ(Weighted Cumulative Response Captured)の元のデータで、上のグラフには「Cum_Pct」が縦軸にプロットされています(横軸は、Decile)。
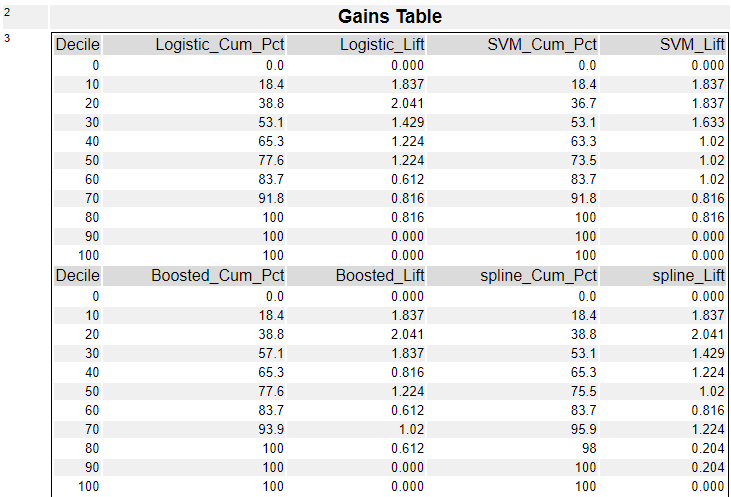
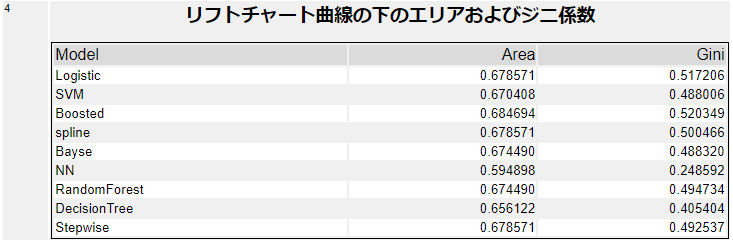
Areaが一番大きいのは、勾配ブースティング(Boosted)モデルなので、この結果を見ると勾配ブースティングを選択する形になるかと思います。
増分応答率レポート
一方、増分応答レポートは以下のとおりです。
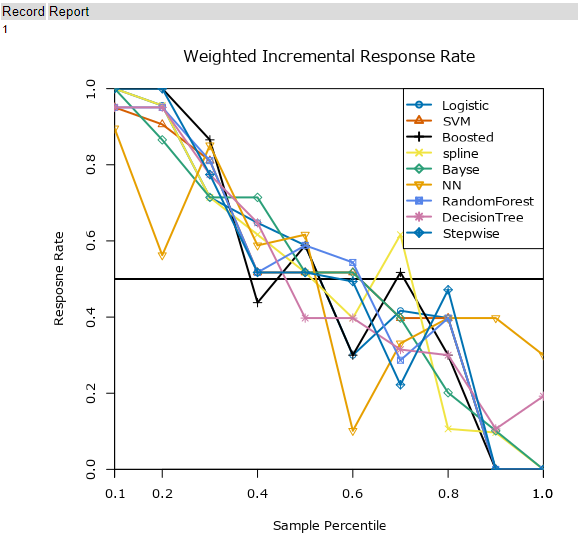
上のWeighted Incremental Response Rateグラフの元のデータとなります。
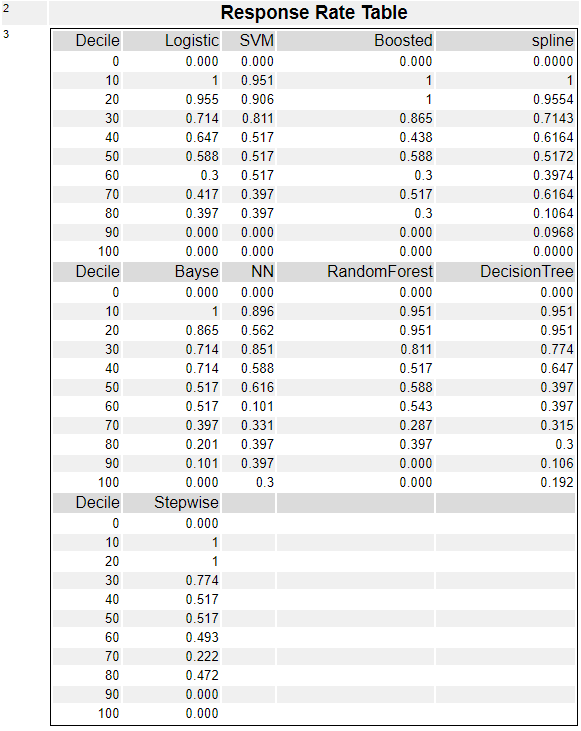
モデル比較(Model Comparison)ツール
モデル比較の本命はこちらのツールになるかと思います。
モデル比較ツールは、入力を2つ、出力を3つ持っているツールです。
D入力:検証用データを入力します。モデルのトレーニングに使用したデータではありません。
M入力:Rベースの機械学習モデル(「予測」カテゴリのツール)をユニオンツールで集約して入力することができます。入力するのは1つのモデルでも構いません(その場合は、トレーニングデータではなく検証用のデータでF1値や混同行列などを出力することができます)。
E出力:各モデルの、Accuracy、F1スコアをテーブル形式で出力します。以下のようなイメージです(マルチクラス分類のサンプルです)。

P出力:Predicted出力。各モデルごとの予測値と実測値を出力してくれます。以下のようなイメージです。

R出力:レポート出力です。見やすい表形式がグラフを見ることができます。
設定
設定はターゲット変数がバイナリ変数(2値)の場合に「正(Positive)」とするクラスを指定することができます。
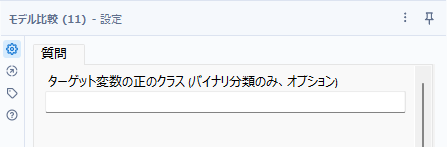
実際のレポートを見てみる
マルチクラス分類
以下のように、SVM、勾配ブースティング、ランダムフォレスト、スプライン、NNの5つのモデルを比較してみましょう。各モデルのO出力からユニオンツールに集約し、モデル比較ツールのM入力に接続しましょう。また、モデル比較ツールのD入力へは、検証用データ(サンプル作成ツールのV出力)を入力します。
それでは、R出力のレポートを見てみましょう。
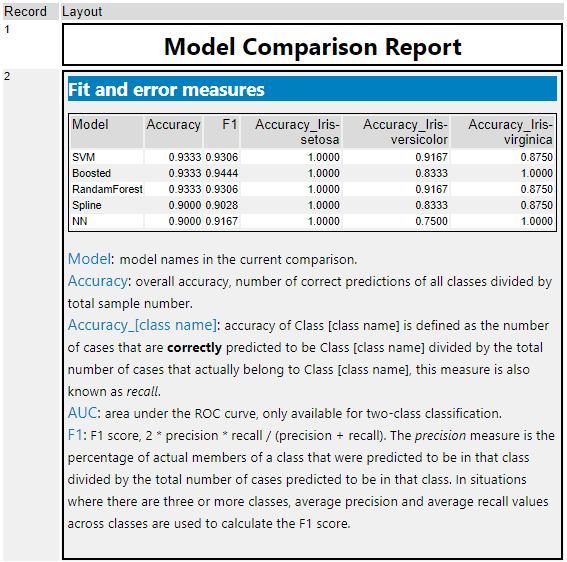
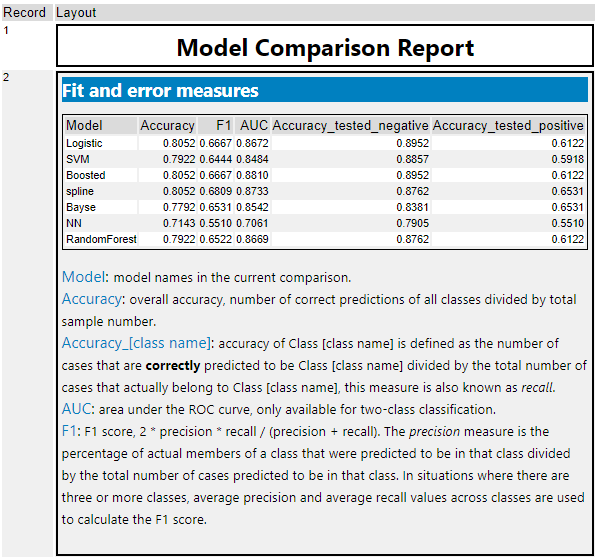
2行目の「Fit and error measures」には各モデル名(Model)、Accuracy(精度)、F1、各クラスの正解率がテーブル形式で提供されます。
Accuracyは、「正確にクラス分けできたレコード数」÷「全レコード数」で計算されます。各クラスのAccuracyは「各クラスの正確にクラス分けできたレコード数」÷「実際の各クラスのレコード数」です。F1スコアは、2×Precision×Recall÷(Precision+Recall)で計算されています。
いずれの指標も1に近いほど良いモデルです(正確に分類できた、という意味です)。今回であれば、どれを選ぶか、、、AccuracyではSVM、Boosted、RandamForestが高い値となっていますが、F1値を見ると、Boostedが一番良く見えます。ただし、Iris-versicolorがけ他のモデルより劣っている部分があります。どれを優先して選択するかは、総合的に判断する必要があります(精度以外にも、速度面や説明可能なモデルであるかどうか、なども考慮の対象となります)。
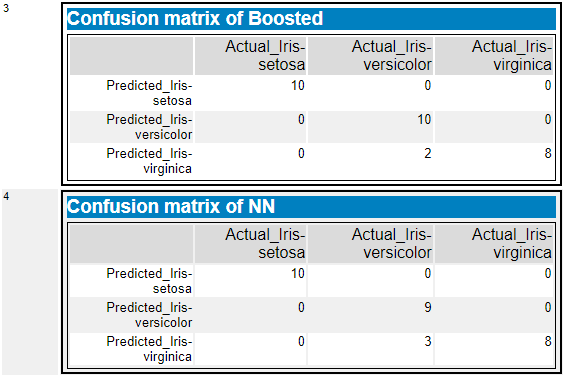
その他、混同行列も各モデルごとに出力されます(今回は、BoostedとNNのみとしています)。
バイナリ(2値)分類
2値分類について、以下のようにLogistic、SVM、Boosted、Spline、Bayse、NN、RandomForestと7つのモデルを比較してみます。マルチクラス分類と異なり、こちらにはAUCも出力されます。
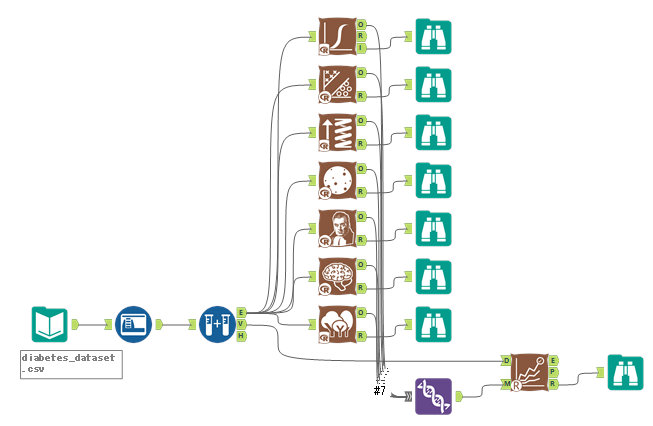
Accuracyから見ると、Logistic、Boosted、Splineの結果が良いです。F1見るとsplineですが、AUCではBoostedがよく見えます。どれを優先して選択するかは、総合的に判断する必要があります(精度以外にも、速度面や説明可能なモデルであるかどうか、なども考慮の対象となります)。
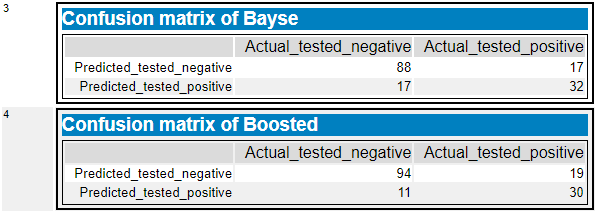
続いて、混同行列がそれぞれのモデルに対して作成されます(掲載はBayseとBoostedのみとします)。
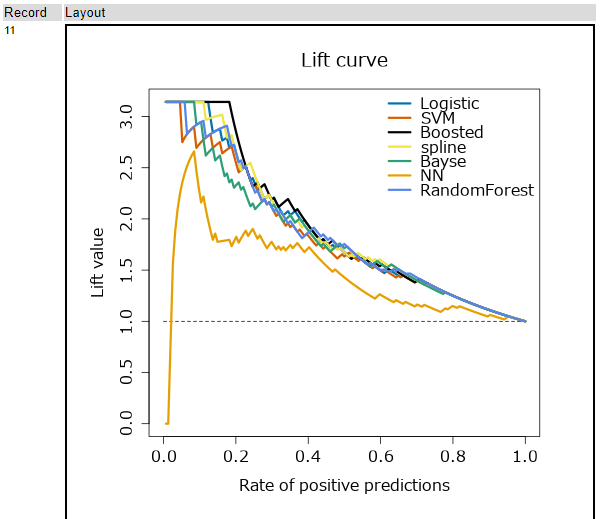
さらにその後、グラフが作成されます。

まず、Lift curveです。縦軸は累積リフト値、横軸は、レコード数の割合になります。
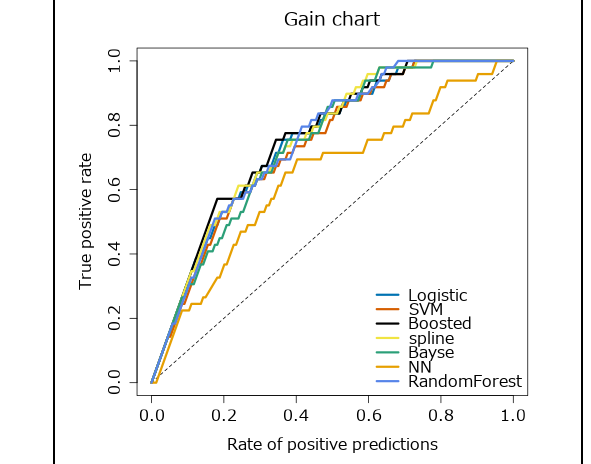
次は、ゲインチャートです。予測モデルを使用して予測される応答です。点線はモデルを使用しないランダムな応答を示します。左上にグラフが寄るのが良いモデルです。縦軸はTrue Positive(TP)の割合、横軸は予測値がPositiveである割合です。
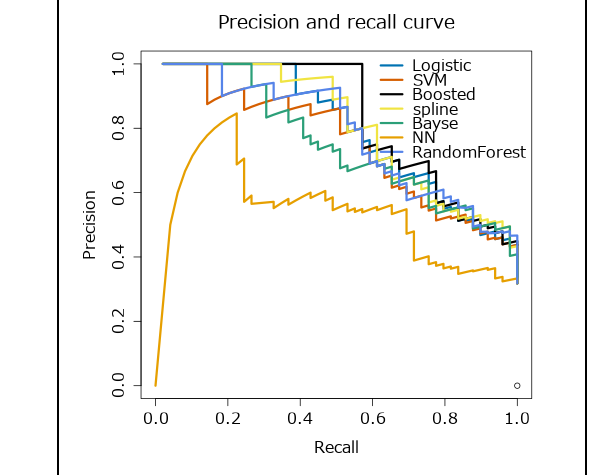
次は、PR曲線です。縦軸はPrecision(適合率)、横軸はRecall(再現率)です。再現率に対する適合率をプロットします。これらは、Positive/Negativeのしきい値を変えることでグラフを作成しているため、適合率と再現率はトレードオフの関係になっています。
最後はROC曲線です。縦軸はTP比率(真陽性率)、横軸はFP率(偽陽性率)です。基本的にグラフが左上に行くほどよい、右下側の面積(AUC)が大きくなるほどよい、ということになります。
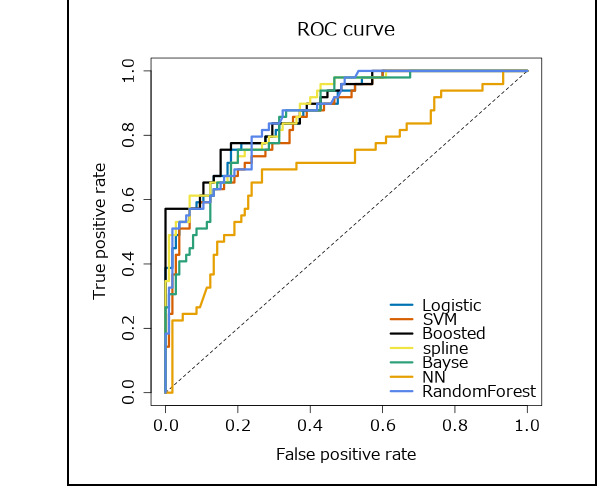
モデルを選択する際、ROC曲線とPR曲線どちらを使うか、ということですが、一般的には不均衡データの場合はPR曲線を使い、それ以外はROCを使うのが良い、とのことです。
回帰
回帰については、ボストン市の住宅価格予想データを使いました。LinearReg、Boosting、RandomForest、NN、spline、SVMの6つのモデルを比較してみました。
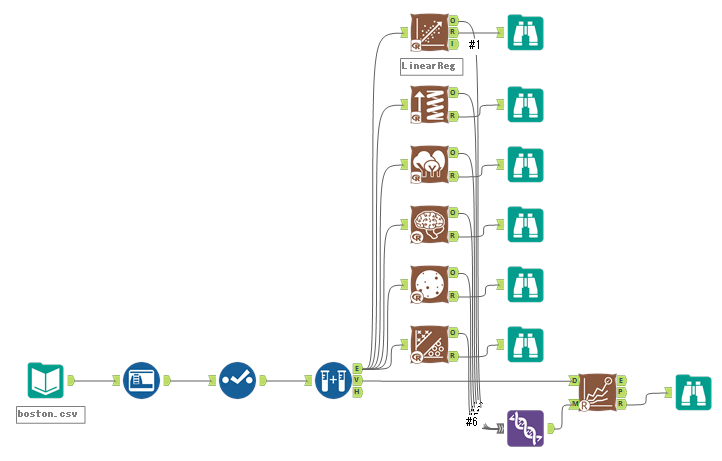
いずれの指標もランダムフォレストが良いという結論です。Correlationは1に近いほうがよく、その他の指標はいずれも小さい方(0に近い)が良い、ということになります。
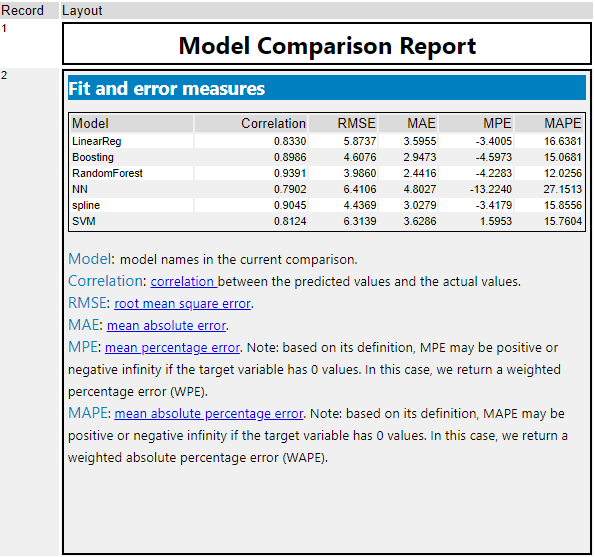
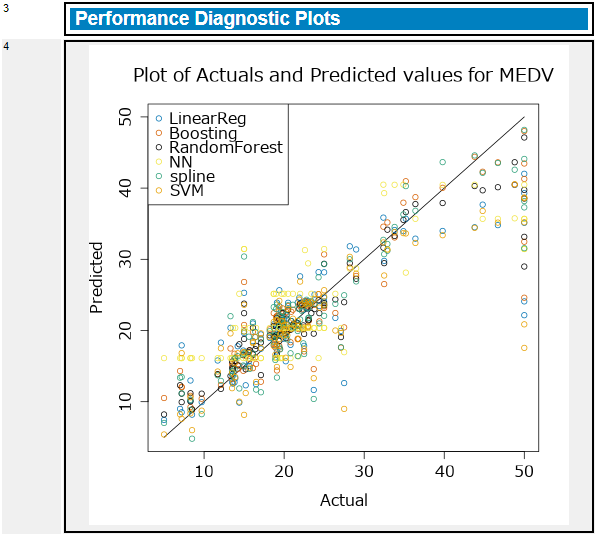
グラフについて、回帰は予測値と実測値のプロットのみです。
クロスバリデーション(Cross Varidation)ツール

交差検証ツール(クロスバリデーションツール)は、トレーニングに用いたデータを使って交差検証を行い、モデルの比較を行うツールです。モデル比較ツールとの差としては、モデル比較ツールは検証用データを使うのに比べ、こちらのツールはトレーニングに用いたデータを使います。
モデルの汎化性能は確認できませんが、新しいデータを使わずにモデルの評価を行うことが可能です。
このツールは、モデル比較ツールと同様、2つの入力と3つの出力を持っています。
D入力:モデルをトレーニングした際に使用したデータを入力します。
M入力:Rベースの機械学習モデル(「予測」カテゴリのツール)をユニオンツールで集約して入力することができます。入力するのは1つのモデルでも構いません。その場合は様々な評価指標でモデルを評価することができます。
D出力:各モデルの、実測値と予測値を出力します。ここで、各Trial(試行)とFold(折り返し)ごとの結果を得ることができます。

F出力:各モデルのTrialとFoldごとのサマリーを得ることができます。

R出力:レポート出力です。見やすい表形式がグラフを見ることができます。
設定
設定はほぼデフォルト値で問題ないのですが、「Type of model」などうまく判定できないことがあるため、手動で設定することをおすすめします。また、「Name of the positive class」オプションは、2値分類の場合には指定しても良いかと思います。
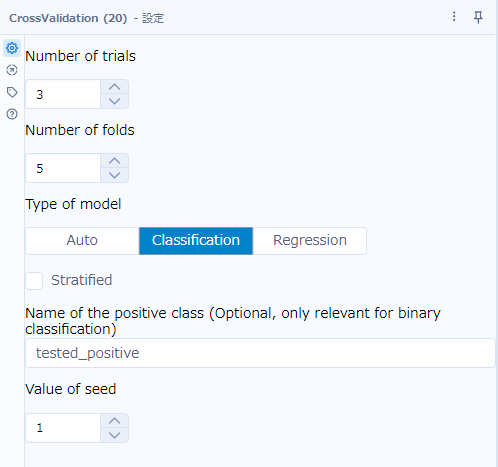
Number of trials
クロスバリデーションを繰り返す回数を指定します。Foldも同じですが、数値を大きくすると時間がかかりますが、品質の予測が正確になります。
Number of folds
データセットを分割するサブセットの数を指定します。
Type of model
Autoは自動で分類(Classification)か回帰(Regression)か判断します。
Stratified
本来の文章は「Should stratified cross-validation be used?」で「層化交差検証を使用する必要がありますか?」というオプションで、データセットのターゲット変数の値の割合を保ったままクロスバリデーションを行うオプションです(例えば、Yesが80%でNoが20%であれば、各フォールド内で同じ割合に保ちます)。データセットの値が偏っているような場合は推奨されます。
Name of the positive class(Optional, only relevant for binary classification)
2値分類の際、陽性(Positive)の値を指定できます。
Value of seed
シード値です。毎回同じ結果が出るようにランダム値のパターンを指定できます。
実際のレポートを見てみる
マルチクラス分類
マルチクラス分類は、以下のように3つのモデル(勾配ブースティング、ランダムフォレスト、ニューラルネットワーク)を作成し比較しました。
ポイントは、モデル比較ツールと異なり、D入力にはトレーニングデータをそのまま入力することです。
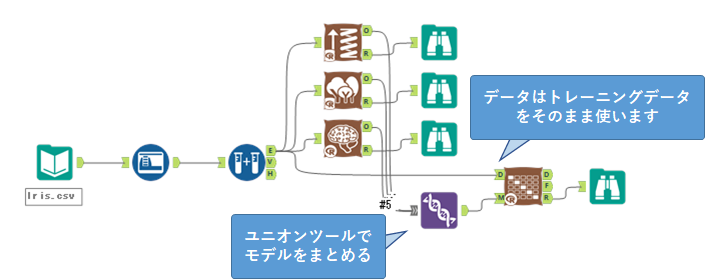
なお、マルチクラス分類では、スプラインモデルツールは結果がおかしいのと、SVMが交じると結果が出力されないのでご注意ください。
回帰などでは出るグラフ「Performance Diagnostic Plots with 95% Confidence Interval」は、3以上の分類では出ないため、空のグラフが出ます。
その他は、混同行列(Confusion Matrix)と各クラスと総合(Overall)のAccuracyが出ます。混同用列のモデルの位置がまぜこぜなので非常に見にくくなっています。
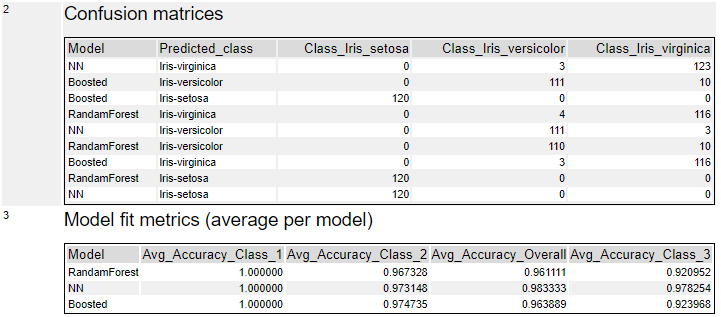
Accuracyについては、「Avg_Accuracy_Overall」という項目が各クラスの間に挟まっているのでちょっとわかりにくいのですが、「Avg_Accuracy_Overall」を全体評価として捉えて評価してかまわないと思います。今回のサンプルであれば、NN(ニューラルネットワーク)が一番Accuracyが高いです。
バイナリ(2値)分類
2値分類は、以下のようなワークフローとしました。
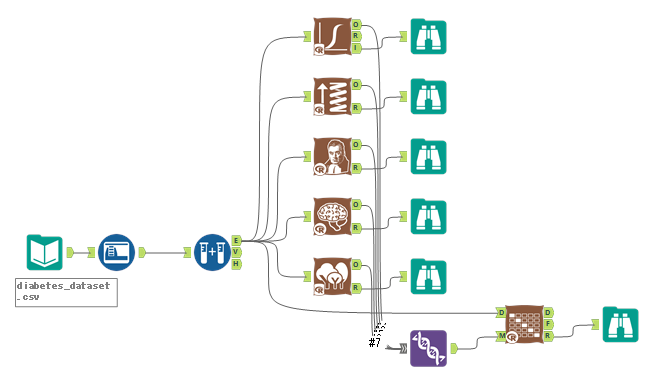
2値分類もスプラインモデルとSVMが交じるとうまく結果がでないため抜いています。
レポートとしては、以下のとおりです。
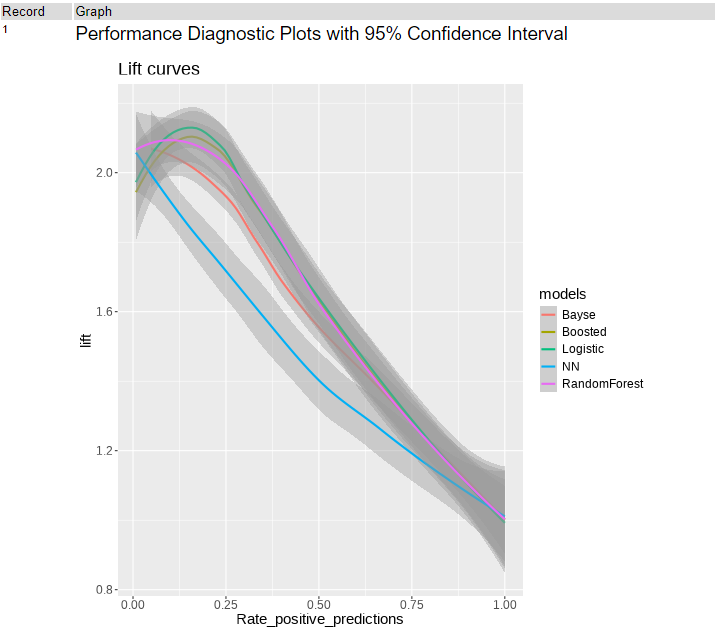
まず、Lift Curveです。
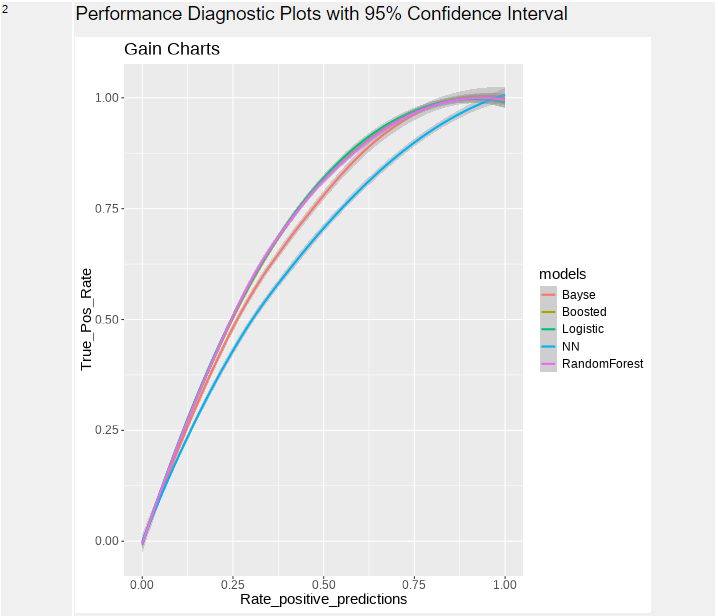
2つ目は、ゲインチャートです。予測モデルを使用して予測される応答です。左上にグラフが寄るのが良いモデルです。
次に、PR曲線です。縦軸はPrecision(適合率)、横軸はRecall(再現率)です。再現率に対する適合率をプロットします。モデル比較ツールとは異なり曲線で描画され、95%信頼区間も表現されています。
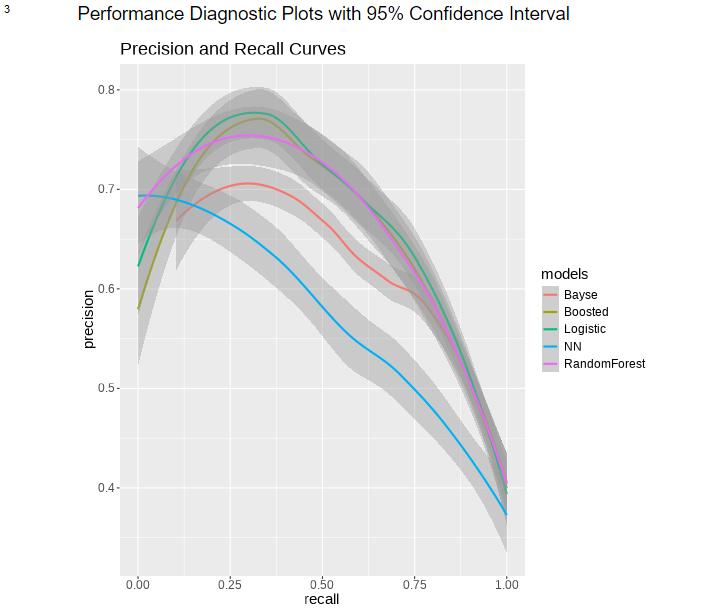
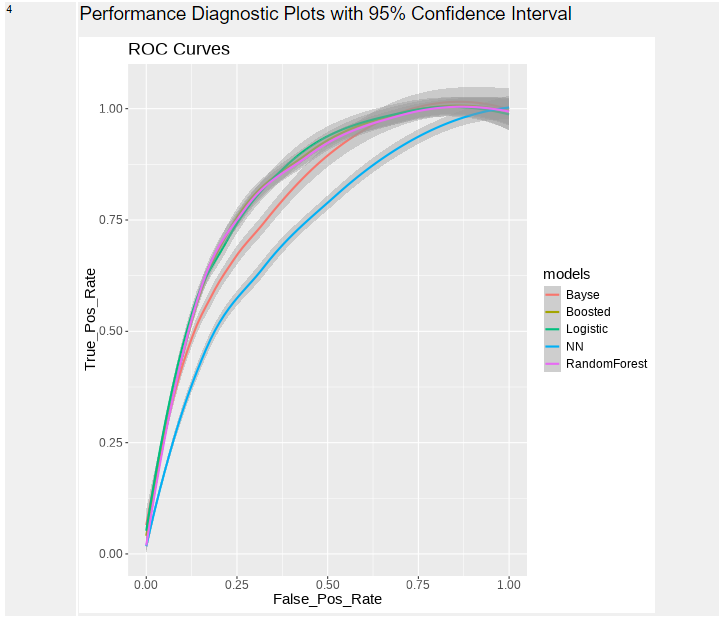
グラフ最後はROC曲線です。縦軸はTP比率(真陽性率)、横軸はFP率(偽陽性率)です。基本的にグラフが左上に行くほどよい、右下側の面積(AUC)が大きくなるほどよい、ということになります。
テーブルとして、混同行列とメトリクスが得られます。混同行列はモデルがまぜこぜなので少々、いや、かなり見にくいです・・・。
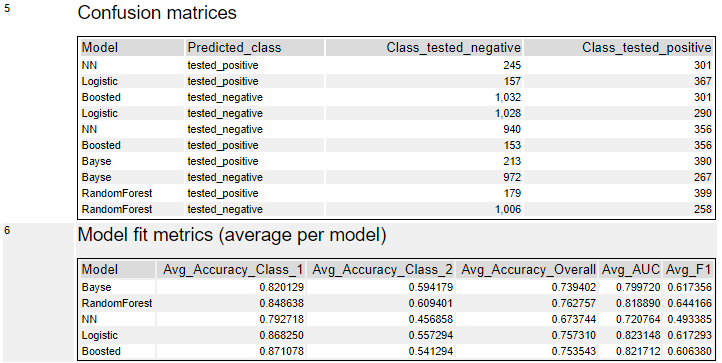
メトリクスでは、各モデルのAUC、F1、およびAccuracyはOverallと各クラスごとに得られます。この例では、ロジスティック回帰がAUCにおいて良いですが、F1とAccuracyを見るとランダムフォレストも良いです。あとは、総合的に考えてどちらを選択するか、ということになるかと思います。
回帰
回帰では、以下のようなワークフローとしています。
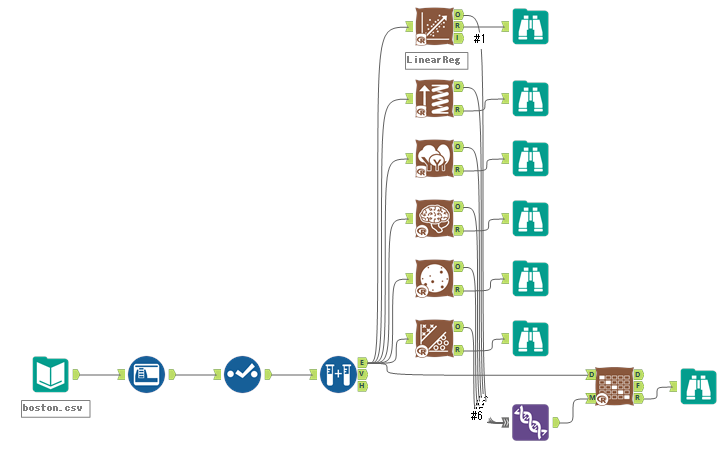
回帰は、線形回帰、勾配ブースティング、ランダムフォレスト、ニューラルネットワーク、スプライン、SVMを使いました。
回帰の場合、予測値vs実測値のグラフと、RMSEなどのモデル比較のメトリクスが提供されます。
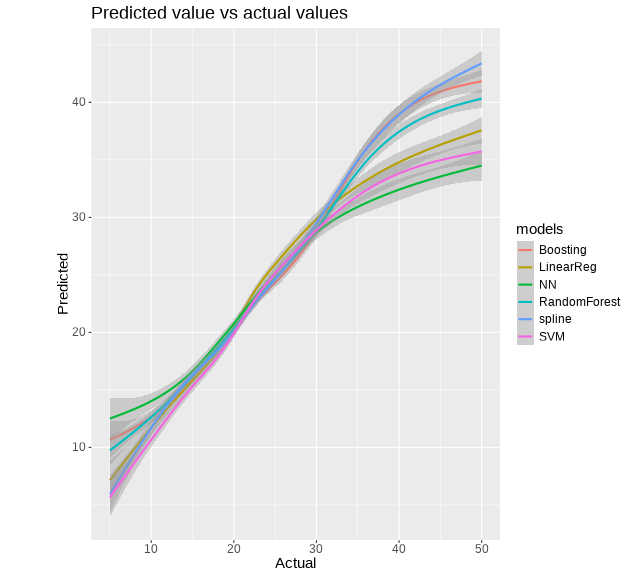
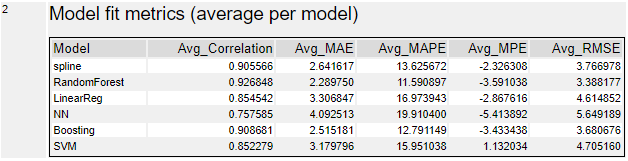
メトリクスは、ランダムフォレストがCorrelationが一番1に近く、RMSEなども全体的に一番良い結果となっています。
参考
Model ComparisonツールはAlteryx CommunityのGalleryからダウンロードする必要があります。
Model Comparisonツールのサンプルワークフローです。
Cross ValidationツールはAlteryx CommunityのGalleryからダウンロードする必要があります。
Cross Validationツールのサンプルワークフローです。
ROC曲線とPR曲線の説明がなされています。
コメント