
このページは解答編です。
↓ネ
↓タ
↓バ
↓レ
↓防
↓止
答えと解説
設問はこちらでした。
P-014: 顧客データ(customer.csv)から、ステータスコード(status_cd)の末尾が数字の1〜9で終わるデータを全項目抽出し、10件表示せよ。
解答ワークフローは以下のようになります。
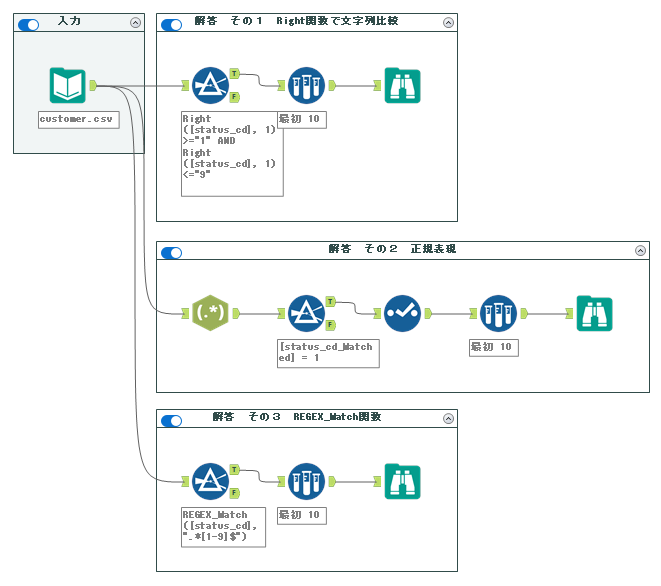
基本的にはフィルターツールを使いますが、様々な手法が可能です。
- Right関数
- 正規表現ツール
- REGEX_Match関数
どれを選ぶべきか、というところは、条件次第です。単純な条件だと単純な方法(1~4)で問題ないですし、条件が多い場合であれば複雑な方法(6)を使った方が結果的に楽だったりします。
1. Right関数
「ステータスコード(status_cd)の末尾が数字の1〜9で終わる」ということですが、ステータスコードを見ていくと数字もしくはアルファベットです。数字のみであれば、右から1文字切り取り、数字に変換して比較、というのが良いのですが、今回は文字列も含んでいるのでこの方法は行いません(が、Alteryxの場合は特にこの方法でもできたりします)。
ここでは、13問目で行った文字として比較の方法で進めましょう。
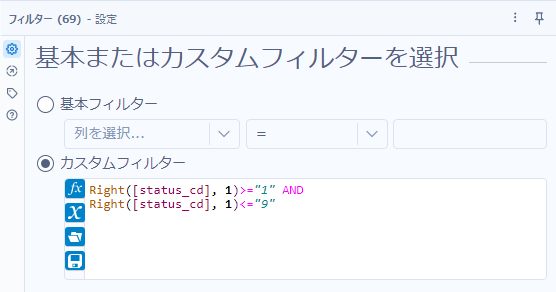
Right([status_cd], 1)>="1" AND
Right([status_cd], 1)<="9"実際のフィルターツール設定は以下の通りとなります。
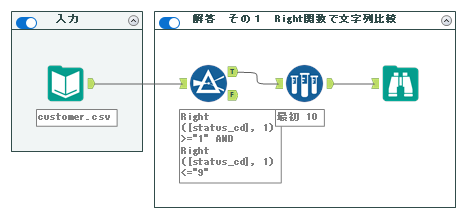
ワークフローとしては以下の通りとなります。
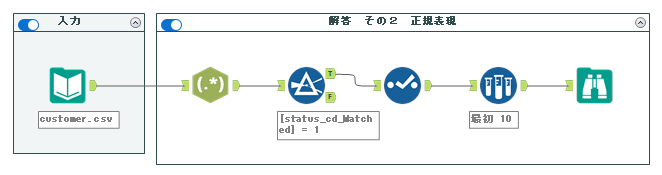
2. 正規表現ツール
若干高度な手法になりますが、正規表現ツールを使うこともできます。
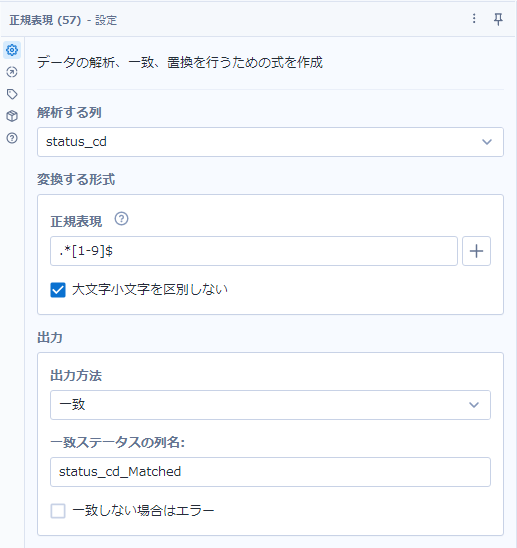
今回は、「ステータスコード(status_cd)の末尾が数字の1〜9で終わる」ということなので、「.*[1-9]$」という式になっていますが、それぞれ以下のような意味となります。
.* : 0文字以上の文字列を示します(「.」は文字1文字(アルファベットでも記号でも数字でもなんでもよいです)、「*」は直前の文字0以上の繰り返し、を意味します)
[1-9] : 1から9のうちのいずれか1文字ということを示します
$ : 文末であることを示します
「.*[1-9]$」により、「文末で1~9のいずれか一文字で終了する」という意味となります。実際のツールの設定は以下の通りです。
実際のワークフローは以下のようになります。
3. REGEX_Matchツール
こちらも若干高度な方法になりますが、正規表現ツールを使う代わりに、REGEX_Match関数を使うことで使用するツールの数を減らす方法をご紹介します。
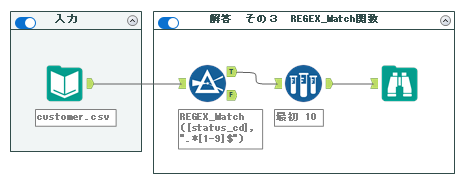
フィルターツールで使うREGEX_Match関数は以下のように使います。
REGEX_Match(検索文字列, 正規表現式)
今回であれば以下のようになります。
REGEX_Match([status_cd], ".*[1-9]$")ここで設定する正規表現式は、解答その2の正規表現ツールに設定した式と同様です。

コメント