最近のMicrosoftのOfficeのファイルは、XMLをZIPで圧縮したものになっています。そのため、拡張子をZIPに変更し、解凍ソフトで展開すれば中身のXMLファイルを見ることができます。
XMLまで分解できれば、ある程度どこで何をしているのか、分析をすることも可能です。
今回は、Excelの名前付き範囲のリストを取得してみたいと思います(Alteryxは名前付き範囲からデータを読み込むことができるため、そのためのリストの作成に使うことができます)。
Excelファイルの名前付き範囲の場所を探す
Excelファイル(XLSXファイル)の拡張子をZIPに変更し、展開すると以下のようなフォルダ構造が現れます。
メインのコンテンツは、xlフォルダの中に入っています。
実際の各シートのデータは、「worksheets」フォルダの中に格納されています。
今回は、名前付き範囲を取得したいだけなので、色々と調べてみると「workbook.xml」の中に名前付き範囲が格納されているのがわかります(地道に各xmlを開いて自分でつけた名前付き範囲を探しただけです)。
これをテキストエディタで開いてみます。

赤枠内が名前付き範囲の定義です。ちなみに、名前付き範囲のすぐ上にはシート名のリストもありますね。
あとは、XMLファイルとしてこのタグ「definedNames」からデータを抜けばオッケーということになります。
なお、名前付き範囲については、docPropsの中にあるapp.xmlでも抽出可能なようです。
XLSXファイルからworkbook.xmlを抽出する
これはなにげに結構手間です。PowerShellのZIP展開機能は、拡張子がZIPになっていないと機能しないため(xlsxなどを展開しようとするとエラーで弾かれます)、一度リネーム(もしくはコピー)を行ってから展開する必要があります。
つまり、workbook.xmlにたどり着くには、以下の手順を踏む必要があります。
- 該当のExcelファイルの拡張子をZIPにリネームしながらコピーする
- コピーしたZIPファイルを展開する
- workbook.xmlを読み込む
これをワークフローに落とし込むとなかなかの大長編になります。

ただし、AlteryxはZIPファイルを直接データソースにすることができます。その場合は以下の手順になります。
- 該当のExcelファイルの拡張子をZIPにリネームしながらコピーする
- コピーしたZIPファイル内のworkbook.xmlを読み込む
個別に見ていきましょう。
ZIPファイルを展開する場合
1.該当のExcelファイルの拡張子をZIPにリネームしながらコピーする
今回、xlsx形式のファイルの拡張子をzipにしつつコピーする必要があります。つまり、コピー先のパスの拡張子をzipにすれば良いだけです。
また、今回はワークフローのツール実行順の関係から、コマンド実行ツールを使っていきたいと思います(最新版であれば、コントロールコンテナが使えるので、Blob入力・Blob出力ツールの組み合わせでもコピーできます)。
また、今回コピー先のフォルダとして、AlteryxのEngineのテンポラリパスを指定しています。
さらに、コピー先のファイル名として、元のファイル名を使わず、UuidCreate関数を使って一意のファイル名を作成しています。
このあたりは、同名ファイルがあった際に上書きにならないようにするためです。
実際にフォーミュラツールに落とし込みましょう。
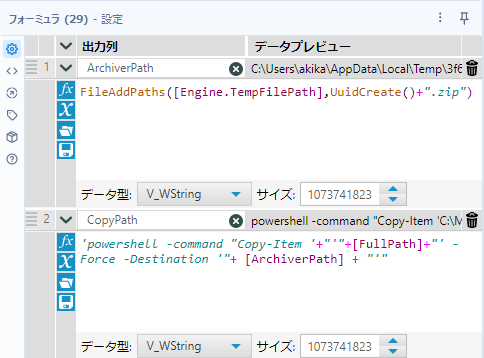
それぞれの数式は以下のとおりです。
ArchiverPath:コピー先のパスです
FileAddPaths([Engine.TempFilePath],UuidCreate()+".zip")CopyPath:PowerShellを使ったコピーコマンドです
'powershell -command "Copy-Item '+"'"+[FullPath]+"' -Force -Destination '"+ [ArchiverPath] + "'"その後の動きは以下のようなワークフローになります。
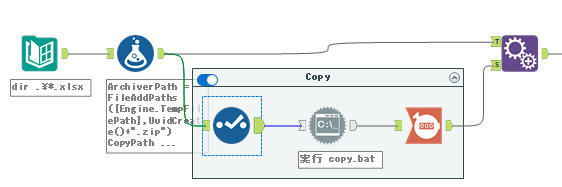
セレクトツール:不要な項目を削除
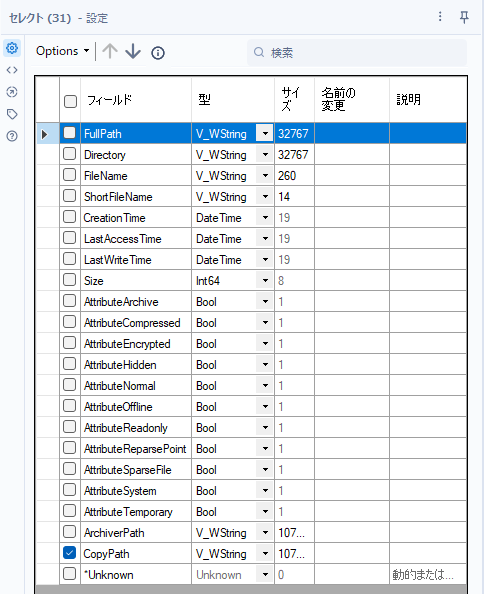
コマンド実行ツールでバッチファイルを保存するために、不要な項目を削除します。
コマンド実行ツール:バッチファイルとしてコマンドを書き出します
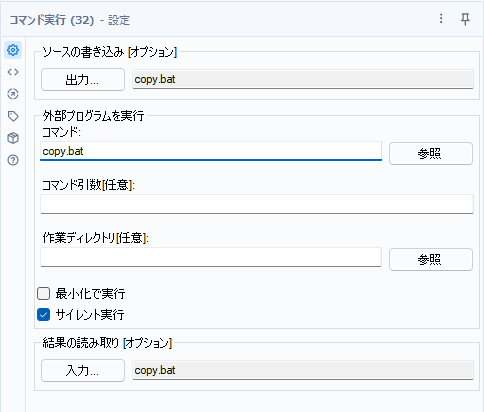
ソースの書き込みの設定は以下のようになります。バッチファイルとして書き出す際、CSVの変形バージョンとして書き出しを行います。設定すべき内容としては以下の内容になります。
- ファイル形式:CSV
- 区切り記号:\0(なし)
- 戦闘行にフィールド名を含める:チェックを外す
- コードページ:ANSI/OEM – 日本語Shift-JIS
ファイルパスは、ワークフローの直下に保存する形にしています。
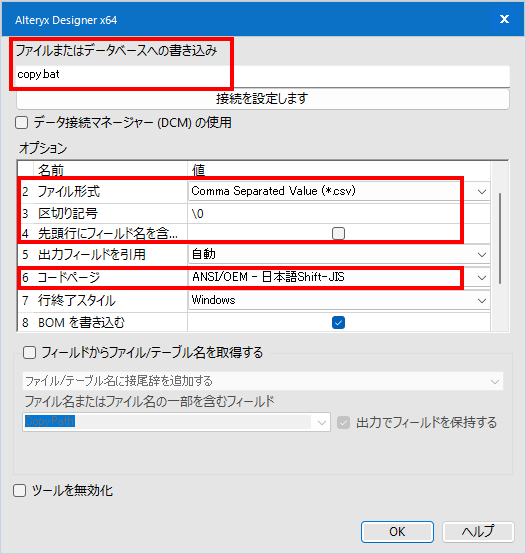
「結果の読み取り」については、そのまま継続してワークフローを流したいので、とりあえずバッチファイルを読み込んでいます。読み込めれば適当な設定で構いません。そのあとのレコードカウントツールも、ワークフローの順序制御用です。
2.コピーしたZIPファイルを展開する
1の続きです。
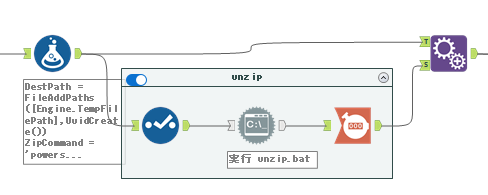
フォーミュラツールにて、ZIPファイルの展開先、展開用バッチファイル用のコマンド、読み込むxmlファイルのパスを作っています。
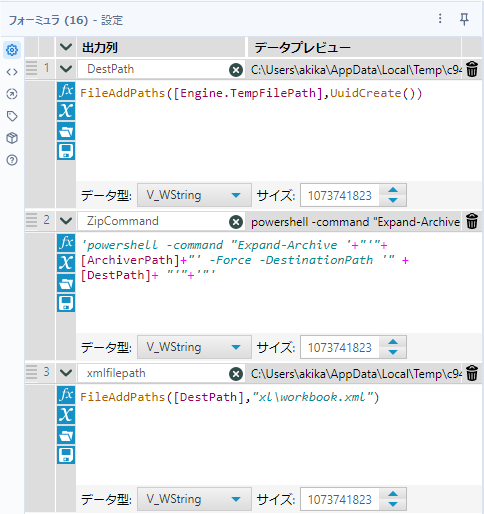
DestPath:ZIPファイルの展開先の出力パスです
FileAddPaths([Engine.TempFilePath],UuidCreate())UuidCreate関数を使って、ファイルごとに1意のフォルダを作成し、そこに展開するようにしています。
ZipCommand:ZIP展開用バッチファイルのコマンドの内容です
'powershell -command "Expand-Archive '+"'"+[ArchiverPath]+"' -Force -DestinationPath '" +[DestPath]+ "'"+'"'xmlfilepath:workbook.xmlのパスです
FileAddPaths([DestPath],"xl\workbook.xml")ZIPの展開は、1と同じくコマンド実行ツールでコマンドをバッチファイルにして実行するだけです。そのため、コマンド実行ツールの設定はほぼ1と同様です。
3.workbook.xmlを読み込む
1,2まででファイルが展開されworkbook.xmlを読み取れる状態になります。
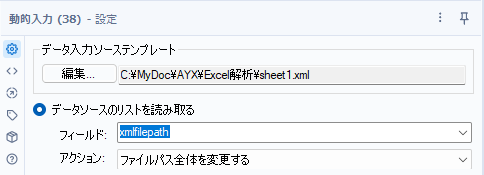
「データソースのリストを読み取る」オプションは、事前に作成したxmlfilepathフィールドを読み込みたいので、フィールドを「xmlfilepath」に設定し、アクションは「ファイルパス全体を変更する」にします。
データ入力ソーステンプレートについては、以下のように設定します。
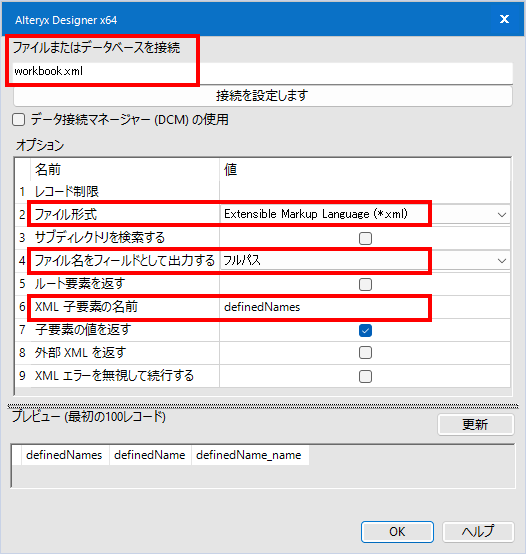
- ファイルまたはデータベースを接続:適当な名前付き範囲を設定したExcelファイルのworkbook.xmlを読み込みます
- ファイル形式:xml
- ファイル名をフィールドとして出力する:フルパス(どのファイルの名前付き範囲なのか紐付けるため)
- XML子要素の名前:「definedNames」(子要素は指定したほうが安定します)
これにより、以下のような情報が得られます。
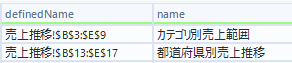
ところで、名前付き範囲を持つシートをコピーすると、スキーマが変わります(localSheetIdというフィールドが増えます)。こうなると動的入力ツールは使えなくなるので、バッチマクロにする必要があります。ここでは一旦バッチマクロは使わないこととします(次の「ZIPファイルから直接読み込む場合を参照してください)。
ZIPファイルから直接読み込む場合
ワークフロー全容は以下のとおりです。
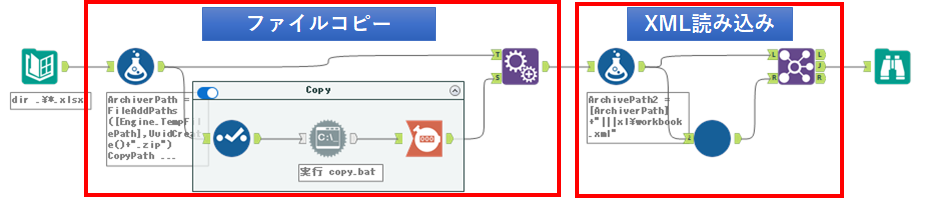
1.該当のExcelファイルの拡張子をZIPにリネームしながらコピーする
これは、先程解説した「ZIPファイルを展開する場合」と同様のやり方になるので、省略します。
2.コピーしたZIPファイル内のworkbook.xmlを読み込む
AlteryxはZIPファイルから直接ファイルを読み込むことができます(できない形式もあります)。ZIPファイルから読み込む場合、動的に読み込む場合はファイルパスの与え方に特徴があります。結論としては、Excelファイルと同様の与え方になります。つまり、ファイル名+「|||」+ZIPファイルの内部のパス名となります。例えば、「C:\zipfile.zip」の「workbook.xml」を読み込む場合は、以下のように指定します。
C:\zipfile.zip|||xl\workbook.xmlつまり、フォーミュラツールで以下のようにします。
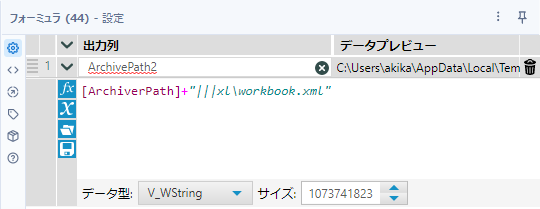
次に、実際にZIPファイルから読み込む部分を構築します。スキーマが変化することがあるので、バッチマクロにします。

データ入力ツールで最初にZIPファイルを開こうとすると、以下のようなメニューがでます。
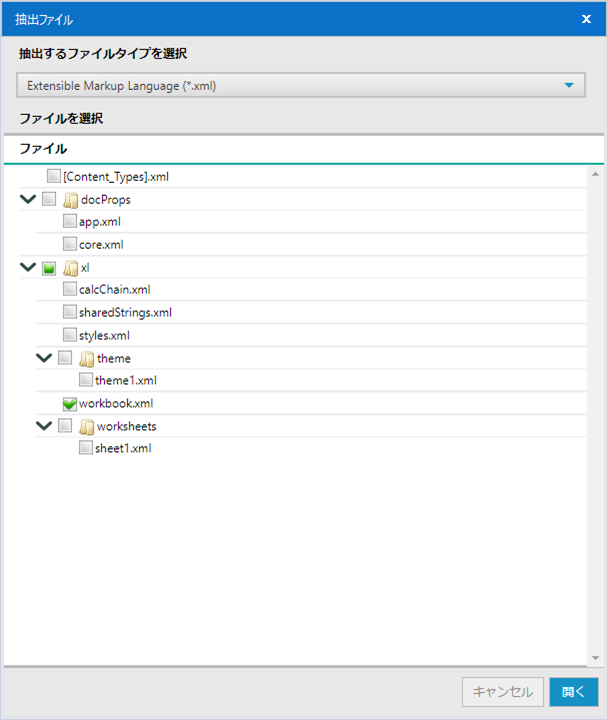
ここで、抽出するファイルタイプを選択し、読み込みたいファイルにチェックを入れることで読み込みが可能になります。
その他細かい設定は以下のとおりです。
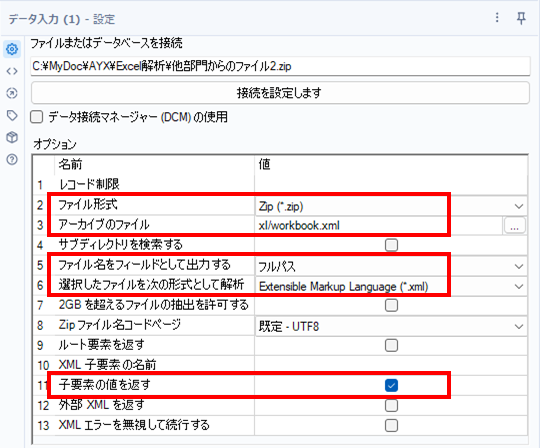
デフォルトではない設定は、「ファイル名をフィールドとして出力する」を「フルパス」にしているところです(元のファイルとの紐づけのためです)。また、今回は子要素の値はデフォルトのままにしています。
アクションツールの設定は、「値を更新」で「File – value」を選択するだけです。
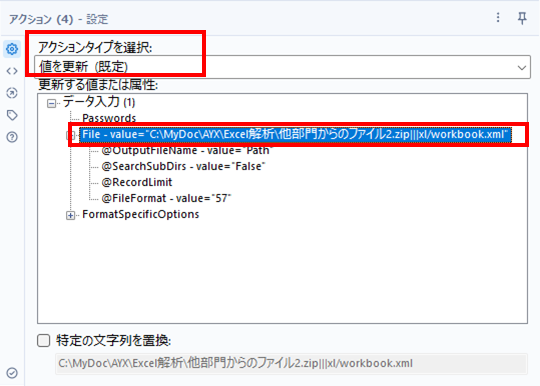
それ以外の部分、少しロジック的に作成しています。これは、名前付き範囲があるシートをコピーしたときに出てくるフィールド「localSheetId」に対応するため、フィールド名のみを格納したテキスト入力ツールをユニオンで最初に読み込むことで、フィールド数が変化しないようにしています。また、「localSheetId」は、最初のレコードはNullになってしまうので、フォーミュラツールでNullを0にしています。
サンプルワークフロー
まとめ
この手法を応用すると、Alteryxの基本機能でできないところを、XMLを参照して実現することができます。若干複雑なのと、XMLを解析しながら行っているので、Microsoftの都合で急にXMLのフォーマットが変更される可能性もあるので気をつけて運用しましょう(とはいえ、互換性の話もあるので、そんな急に変わることはないと思います)。
なお、今回は情報を取るだけだったので、ZIPから直接読み込む方法で問題ないのですが、ZIPを展開する方法であれば、Excelファイルの中身をXMLベースで編集して戻すことも可能です。

コメント