
Alteryxで大量のデータを扱うような際、処理を終わらせるのがなるべく早いワークフローを作りたい、といった要望が出ることがあると思います。処理時間は効率に直結しますが、大量のデータだとワークフローの作り方で処理速度に大きく差が出ることがあります。
しかしながら、どのツールのどの処理が重いのか?というのを知らないと効率的なワークフローを作るのは難しいですが、Alteryxでは幸いなことに「パフォーマンスプロファイリング」という機能が備わっています。
これは、ワークフロー設定の「ランタイム」タブからアクセスすることができます。デフォルトではこのオプションはオフになっています。
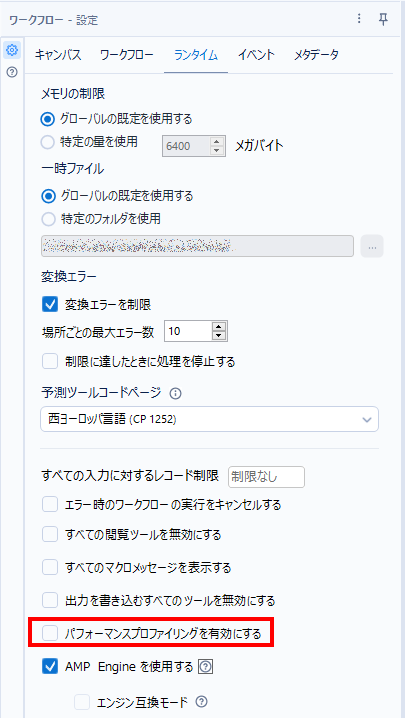
これをオンにすることで、各ツールで処理を行うのにどれくらいの時間がかかっているのか、というのを記録してくれるのですが、これによりDesignerの処理速度は低下します。そのため、ワークフローのチューニングの際のみオンにし、各ツールのかかった時間を見ながらワークフローをチューニングしていくのがポイントです。
これをオンにすることで、以下のようなレポートが結果ウィンドウに表示されます。
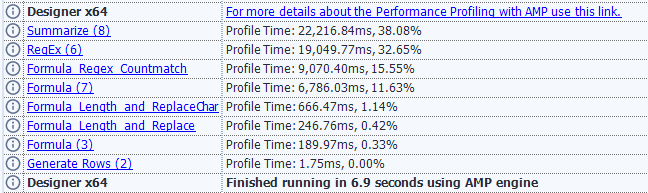
各ツールの時間が「Profile Time」としてミリ秒単位で出力されます。また、全体の処理に占める割合も表示されます。
これは、以下のようなベンチマーク用のワークフローですが、右端の3つのフォーミュラツールは同じ結果がでるような処理をしています。処理の内容としては、文字列の中から#が何文字あるかを計算しています(文字列は、#もしくは.のみで構成されています)。
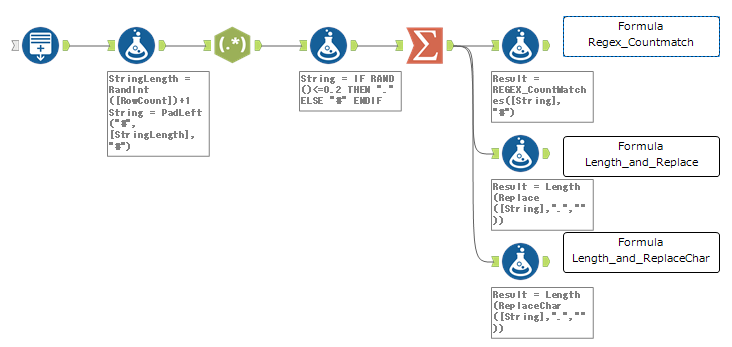
一番上の「Formula_Regex_Countmatch」と記載のあるものは、以下のような計算を行っています。
REGEX_CountMatches([String], "#")2つ目の「Formula Length_and_Replace」は以下のような計算を行っています。
Length(Replace([String],".",""))3つ目の「Formula Length_and_ReplaceChar」は以下のような計算を行っています。
Length(ReplaceChar([String],".",""))これによるパフォーマンスプロファイリングの結果を改めて見てみましょう。
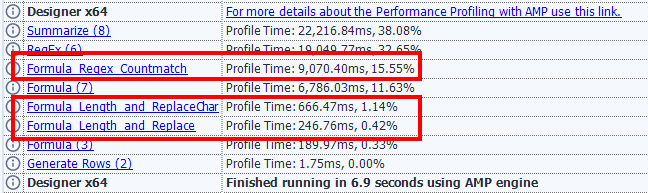
REGEX_CountMatch関数を使ったものが15.55%、一方ReplaceCharとLengthを組み合わせたものは1.14%。ReplaceとLengthを組み合わせたものは0.42%という結果になっており、明らかにREGEX_COUNTMATCH関数は遅いことがわかります。
なお、AMP Engineをオンにした場合の時間は実際の時間とならないようなのでご注意ください。
※参考:「AME Engineでのパフォーマンスプロファイリング」
もちろん、今回はたまたまReplace関数などで簡単に実装できる内容だったので、REGEX_COUNTMATCHを使わない、という選択を取ることができますが、REGEX_COUNTMATCHは非常に使い勝手が良いため、多少遅くてもこちらを使うという選択を取ることもあるかと思います。ケースバイケースで判断するようにしてください。
なお、ワークフローのチューニングが終わったら、必ずパフォーマンスプロファイリングオプションはオフにしましょう。
サンプルワークフローダウンロード
次回
次回は、ツールではなく関数の話題にしようと思います。

コメント