
このページは解答編です。
↓ネ
↓タ
↓バ
↓レ
↓防
↓止
答えと解説
設問はこちらでした。
P-058: 顧客データ(customer.csv)の性別コード(gender_cd)をダミー変数化し、顧客ID(customer_id)とともに10件表示せよ。
※レコードの順序は、元の順序を保持すること
※新しく作成されるフィールド名は、「gender_cd_」に値を組み合わせたものとすること
解答ワークフローは以下のようになります。
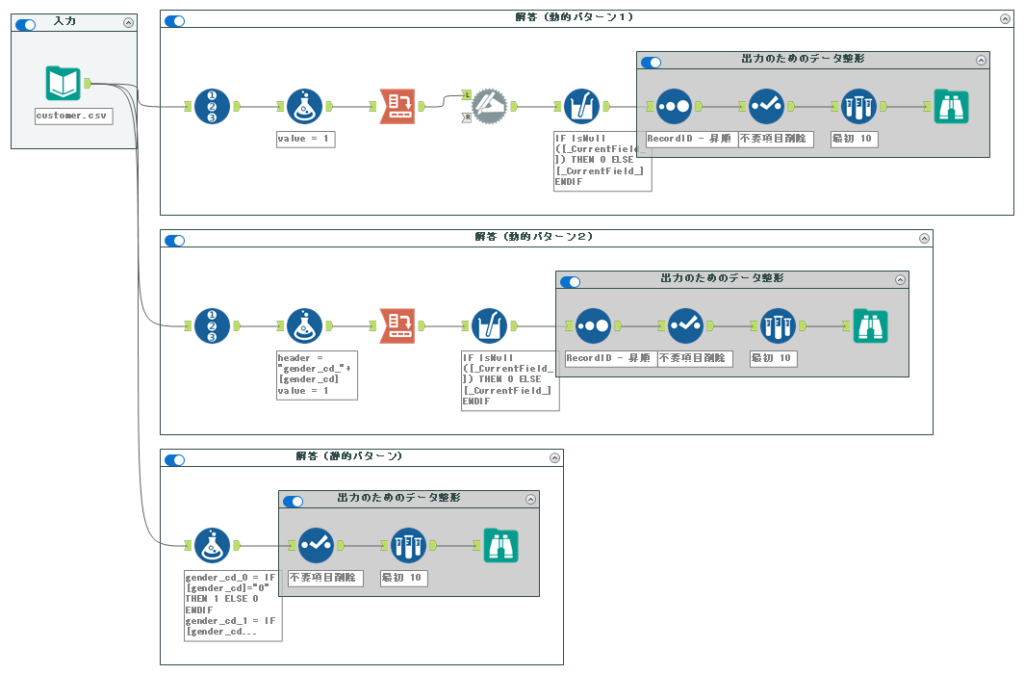
今回は、性別フィールドに対してダミー変数化する問題です。
通常、ラベルフィールド(カテゴリフィールド)は文字等で構成されるため、そのまま機械学習の予測変数(説明変数)としては利用できません。しかしながら、これを数値化することで機械学習に用いることができます。
数値化にも2タイプあり、ラベルをそのまま数字に置き換えるラベルエンコーディングと、ワンホットエンコーディング(One-Hot encoding)と呼ばれる手法があります。
今回はすでにラベルエンコーディングされているため(gender_cd列)、ワンホットエンコーディングを行います。
ワンホットエンコーディング
図で示すと以下のようになりますが、カテゴリフィールドのそれぞれの値に対して新しいフィールドを作成し、対応するフィールドに1、そうでないフィールドには0を入れるようにして作ります。
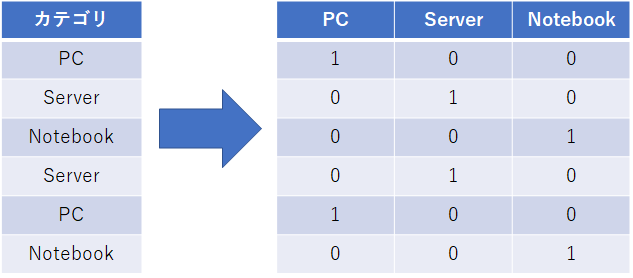
原理的には非常に単純かと思います。
それではこれを実際にAlteryxで作ってみたいと思います。やり方としては大きく分けて2通りあります。
- 静的パターン
- 動的パターン
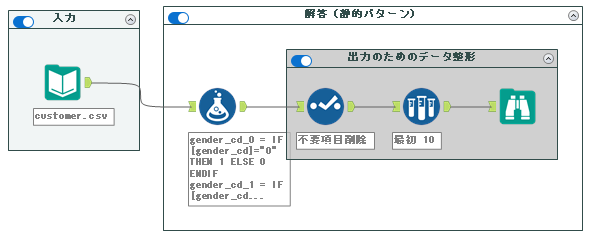
静的パターン
静的パターンは非常に単純な方法になります。IF文を使って該当していれば1、そうでなければ0を入れる方法です。これはフォーミュラツールで行います。
つまり、gender_cdが0であれば、
IF [gender_cd]="0" THEN 1 ELSE 0 ENDIFとなり、gender_cdが1であれば、
IF [gender_cd]="1" THEN 1 ELSE 0 ENDIFとします。残りはgender_cdが9なので、
IF [gender_cd]="9" THEN 1 ELSE 0 ENDIFとなります。
違いは、フィールド名と値です。実際のワークフローは以下の通りとなります。
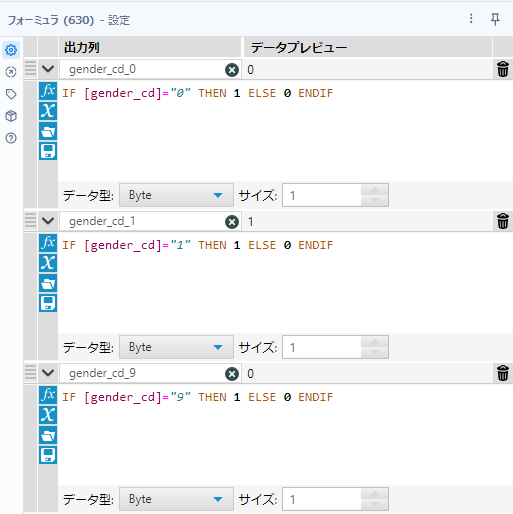
データ型は0~9の範囲なので、Byte型で十分です。この方法は非常にワークフローがシンプルになりますが、新しいコード値が入ってくると、手動でまた計算式を追加しなければなりません。また、コード値が多い場合は計算式が大量に書かないといけません。
ワークフロー全体としては以下の通りとなります。
動的パターン
次に動的なパターンをご紹介します。ワークフローは少し複雑になりますが、カテゴリ値が増えたりしても動的に対応が可能です。若干やり方の異なる2つのパターンがあるため、それぞれ紹介したいと思います。
パターン1
まず、レコード順の保存のため、レコードIDツールを接続します。その後、フォーミュラツールを追加します。このフォーミュラツールは、各カテゴリフィールドの1に該当するものです。以下のような設定となります。
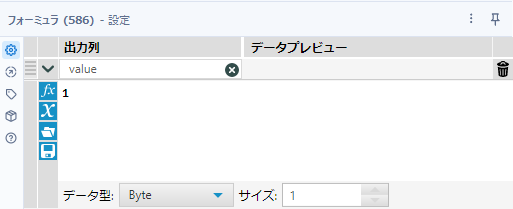
フィールド名は「value」、式は「1」、データ型は「Byte」としています。
次に、クロスタブツールを使います。グループ化フィールドは「RecordID」「customer_id」です。列ヘッダーは「gender_cd」、新しい列の値は先程作った「value」、集計方法は「合計」もしくは「平均」でも構いません。
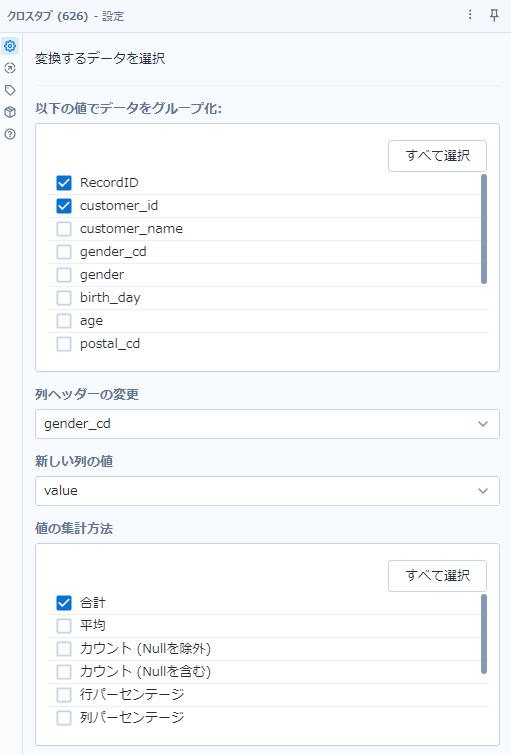
つまり、下図の左のようなデータが右のようになります。

ここまでくれば、あとはNullを0で埋めて、フィールド名を変更するだけです。
フィールド名を変えるのはセレクトツールでも地道にできますが、今回は動的にやってみたいと思います。ここでは、動的リネームツールを使います。
動的リネームツール

動的リネームツールは、開発者カテゴリにあるツールで、一見とっつきにくそうですが、開発者カテゴリにあるツールの中では親しみやすいツールです。このツールは、計算式や対応表を使ってフィールドの名前をリネームすることができます。つまり、動的にフィールド名を変更できるツールです。
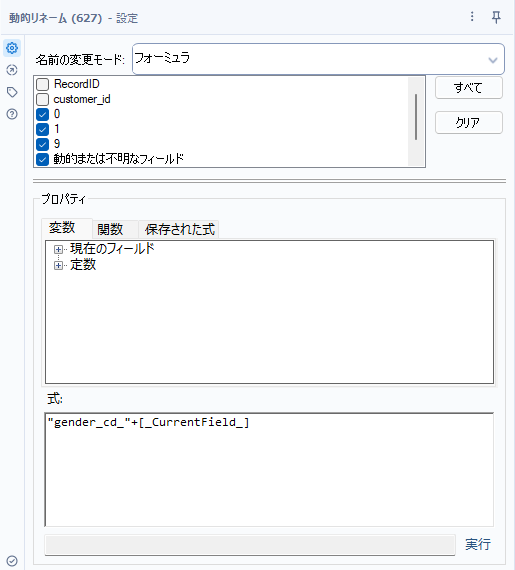
基本的にはチェックを入れたフィールドに対して同じ処理を行います。「名前の変更モード」で処理内容を変えることができますが、例えば、フィールド名の前になにかワードを付加したり、削除したり、1行目をフィールド名として採用したり、対応表などからフィールド名をつけたり、などですが、今回は「フォーミュラ」というオプションを使いましょう。これは、計算式を使ってフィールド名を変更することができます。なお、この「名前の変更モード」を変えると大きく設定画面が変更されます。
今回であれば、以下のように設定しています。名前の変更モードは「フォーミュラ」、フィールドについては「0」「1」「9」と「動的または不明なフィールド」にチェックを入れます。これがミソで、gender_cdフィールドに新しい値が追加されても対応可能です。
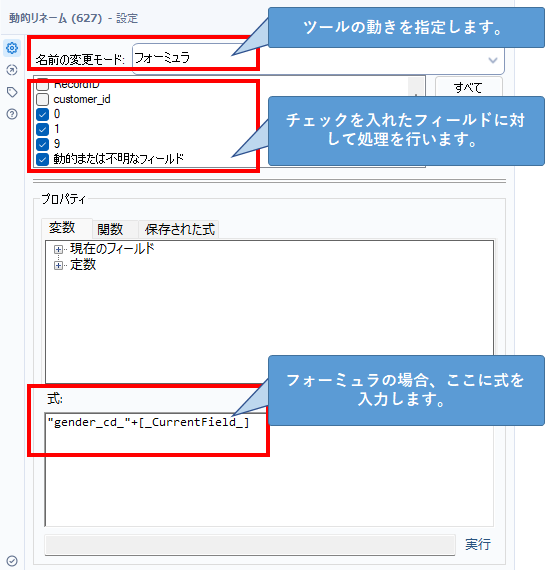
今回の場合は、以下の式です。
"gender_cd_"+[_CurrentField_]これは、「gender_cd_」にチェックを入れたフィールド名を結合するものです。つまり、「0」フィールドを処理するときは、「gender_cd_」+「0」となるため、最終的なフィールド名は「gender_cd_0」となります。
最後は、Nullを0で埋めていきます。これには複数フィールドフォーミュラが最適です。このツールは、一度に複数のフィールドに対してフォーミュラツールを適用できるツールです。
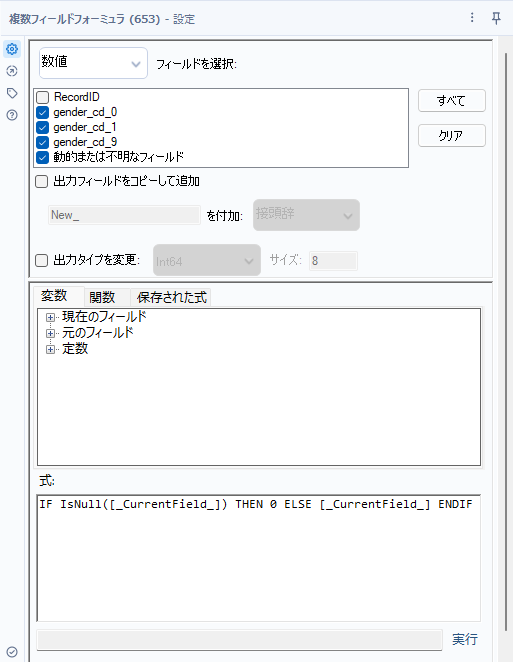
先程リネームした3つのフィールドにチェックを入れましょう。また、ここでも「動的または不明なフィールド」にチェックを入れます。式は以下のとおりです。
IF IsNull([_CurrentField_]) THEN 0 ELSE [_CurrentField_] ENDIFこれは、処理しているフィールドがNullであれば0を入れ、そうでなければそのフィールドの値をそのまま残す、という設定です。ですので、Nullなら0が入り、1ならそのまま1が残ります。
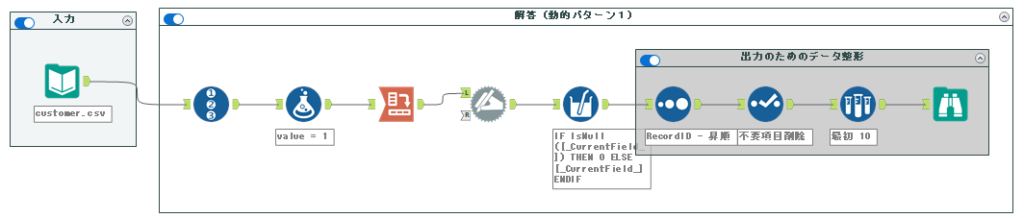
ここまで来ると、後はソートツールで、レコードIDの昇順に並べ、不要項目を削除し、サンプリングツール等で先頭から10行取れば完了です。
実際のワークフローは以下のとおりです。
パターン2
パターン2もパターン1と似ています。
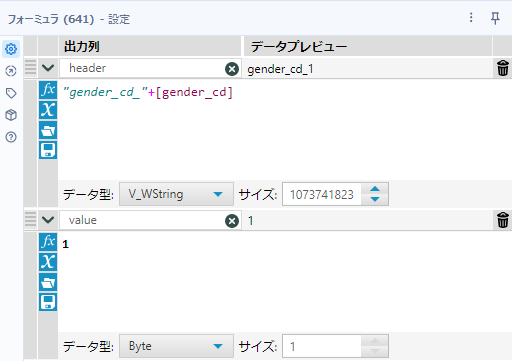
まず、レコード順の保存のため、レコードIDツールを接続します。その後、フォーミュラツールを追加します。今回はこのフォーミュラツールに2つの役割があります。すなわち、パターン1と同じく対応している「1」を示すフィールド「value」の作成と、もう一つはヘッダー列を作ることです。
ヘッダー列は最終的なフィールド名となりますが、今回は「gender_cd_」+「コードの値」となるため、gender_cdの値が0なら「gender_cd_0」という名称のフィールドを作る必要があります。これを実現するには、以下のような数式が必要です。
"gender_cd_"+[gender_cd]実際のフォーミュラツールの設定は以下の通りとなります。
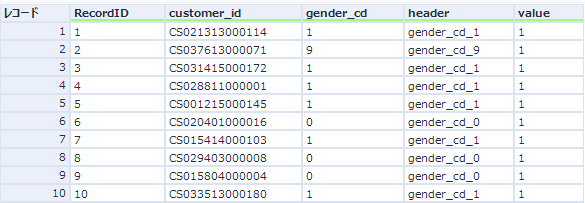
これにより、以下のようなデータができます(必要なフィールドのみ抽出しています)。
この後、クロスタブツールで、ヘッダ列に「header」、新しい列の値に「value」を指定します。グループ化はパターン1と同様「RecordID」「customer_id」となります。
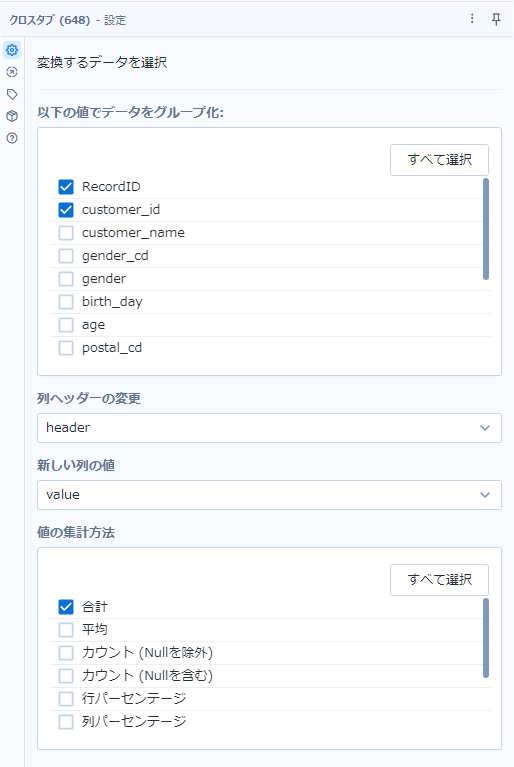
集計方法もパターン1と同じで「合計」などです。
これにより以下のようになります。パターン1とは異なり、フィールド名が最終的なものになっています。
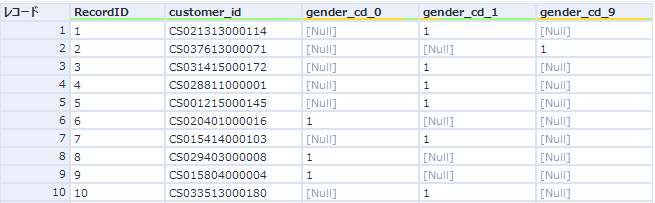
ここまでくれば、パターン1と同様、複数フィールドフォーミュラでNullを0にします。
最終的なワークフローは以下のとおりです。
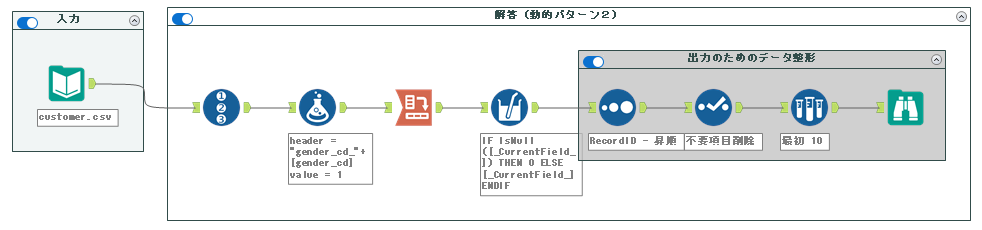
まとめ
今回は、ダミー変数を作る問題でしたが、その中でもOne-Hot encodingという手法となります。単純に作るのであればフォーミュラツールで作れるのですが、クロスタブツールを活用することで動的に動作するワークフローが作成可能です。これはぜひ覚えておきたい手法です。

コメント