
本記事はe-Statの国勢調査のデータを扱うシリーズです。前回の記事は、こちら。
前回のブログで保存したデータですが、まだ縦持ちになっており使いにくい形になっています。
例えば、「男女別人口総数及び世帯総数」のデータを読み込んでみます。

ちょっと見にくいのでメタデータだけ見てみましょう。
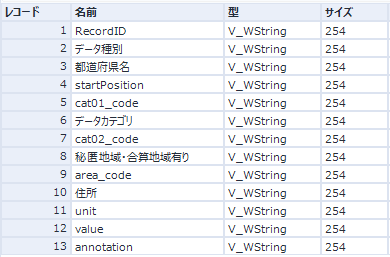
ここで、データカテゴリをグループ化してどんな項目があるのか見てみましょう。
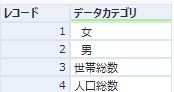
「value」フィールドの種別がデータカテゴリなのですが、つまりこのデータは「人口総数」「世帯総数」「男」「女」の4種類のデータが格納されているということになります。
ここで、「データカテゴリ」というのをフィールド名にして、値としては「value」フィールドを格納すると非常に見やすくなります(BIツールで読み込むならこのままでも問題ないかもしれません)。
それではワークフロー化していきたいと思います。
ワークフローを作成する
データ入力ツールでデータを読み込んだ後、データを横持ちにしてくわけですが、単位をどうするかまず考えたほうが良さそうです。「男女別人口総数及び世帯総数」であれば、人口と世帯で単位が異なるため、単位をどう残すか、という課題があります。
今回は、フィールド名自体に付加してしまいましょう。
フォーミュラツールでデータカテゴリフィールドと結合します。なお、「男」「女」は頭に全角空白入っているので、Trimで削除しておきます。
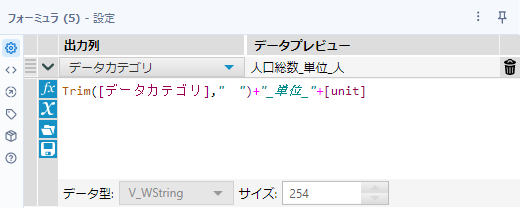
Trim([データカテゴリ]," ")+"_単位_"+[unit]次に、クロスタブツールでデータを横持ちにしていきます。「列ヘッダーの変更」は「データカテゴリ」、「新しい列の値」は「value」をセットします。
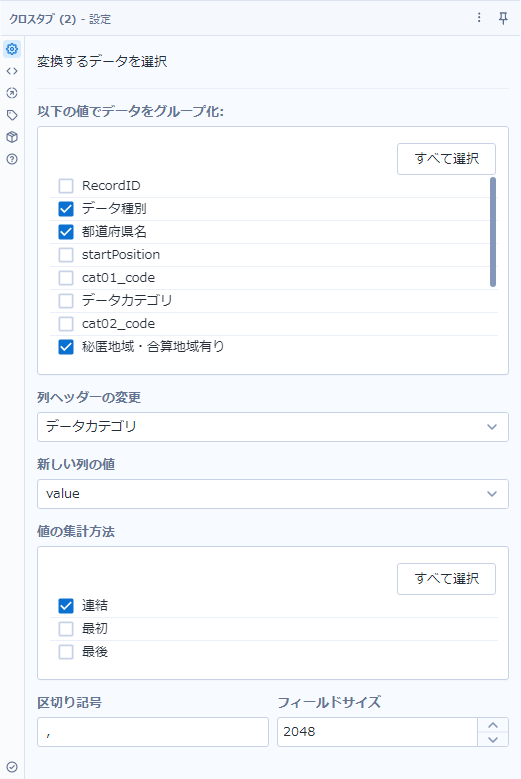
「以下の値でデータをグループ化」のところは、残したいデータをチェックしていくのですが、上のスクショではスクロールで見切れています。以下のフィールドにチェックを入れましょう。
- データ種別
- 都道府県名
- 秘匿地域・合算地域有り
- area_code
- 住所
- annotation ※空っぽなので不要かもしれません
これにより以下のようになります。ついでにarea_codeでソートしておくと良いかもしれません。

データ量も減るので、一石二鳥です。
ワークフローとしては、以下のようになります。
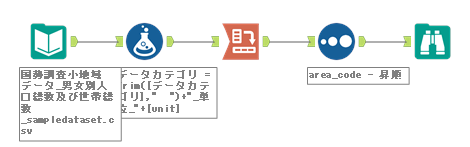
サンプルワークフロー
サンプルワークフローは、データ量を減らした入力データにしています。
コメント