
このページは解答編です。
↓ネ
↓タ
↓バ
↓レ
↓防
↓止
答えと解説
設問はこちらでした。
P-088: 087で作成したデータを元に、顧客データに統合名寄IDを付与したデータを作成せよ。ただし、統合名寄IDは以下の仕様で付与するものとする。
・重複していない顧客:顧客ID(customer_id)を設定
・重複している顧客:前設問で抽出したレコードの顧客IDを設定
顧客IDのユニーク件数と、統合名寄IDのユニーク件数の差も確認すること。
解答ワークフローは以下のようになります。
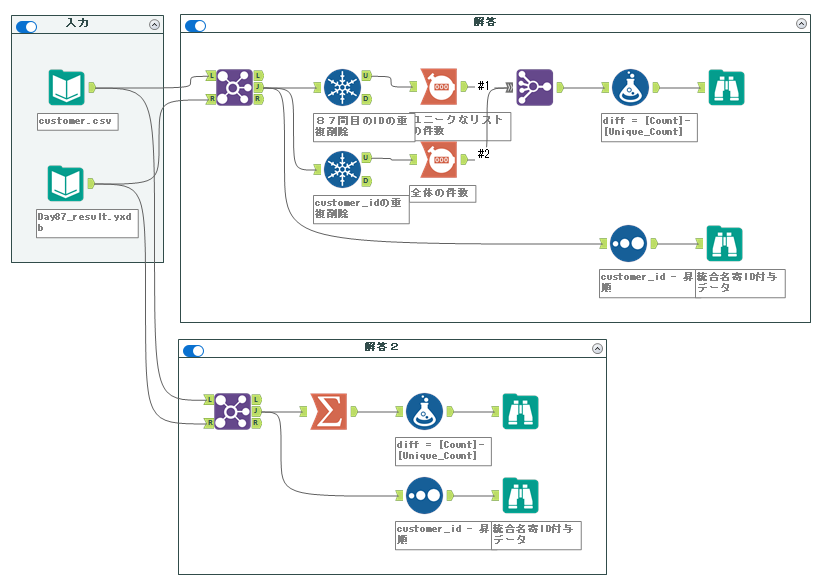
87問目の続きの問題で、元のcustomer.csvに対して87問目で求めたユニークなcustomer_idを付与する問題です。
87問目では、名前(customer_name)と郵便番号(postal_cd)が同じ顧客は同一の顧客とみなしていました。そのため、customer.csvとの結合は、customer_nameとpostal_cdを用います。これにより87問目の結果のcustomer_idがcustomer.csvにひも付き、この時のcustomer_id(unique_idとしましょう)は各顧客に対してユニークになります。
実際の結合ツールの設定は以下のようになります。キーフィールドは、customer_nameとpostal_cdの2つとなります。あとでわかりやすくするように、Right側入力(87問目の結果)のcustomer_idは「unique_id」としておきます。
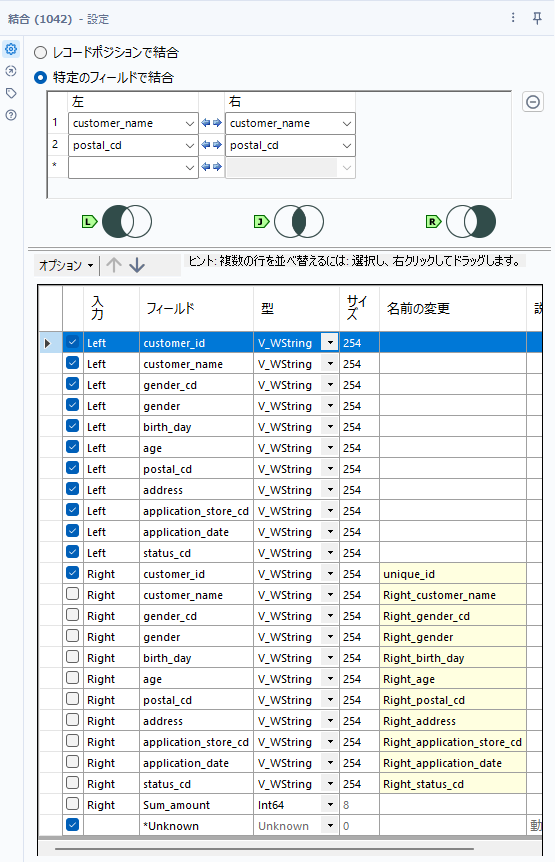
これで欲しいものは得られています。
あとは、87問目と同じように件数を出していきましょう。
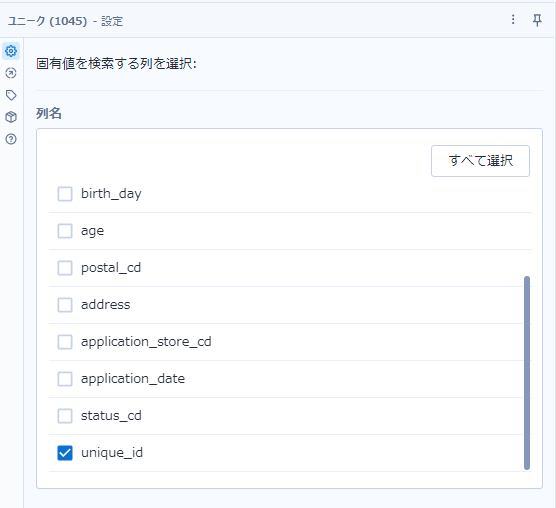
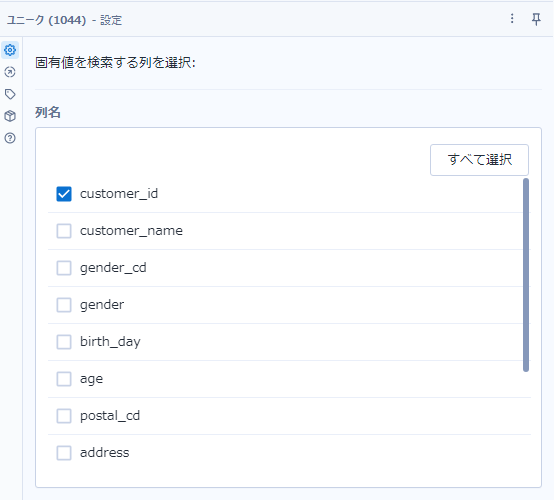
結合ツールのJ出力からユニークツールを2つ接続します。設定はそれぞれ以下のとおりで、87問目で求めたユニークなID(unique_id)から重複を弾いたものと、もう一つは全レコードに対して念のため重複を弾きます。
これらについてそれぞれレコードカウントツールを接続します。その後、87問目と同様に複数結合ツールを使っていきます。このように1レコードのデータを結合する際は、「レコードポジションで結合」を選択します。
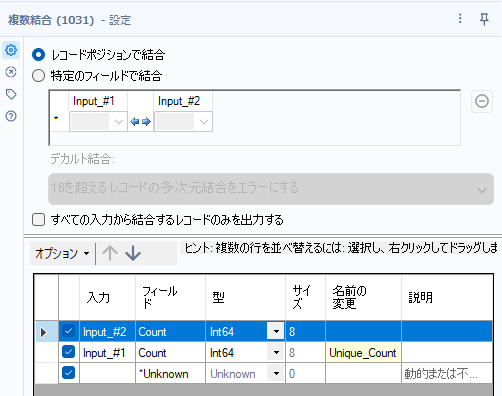
この時点では以下のように接続されているはずです。
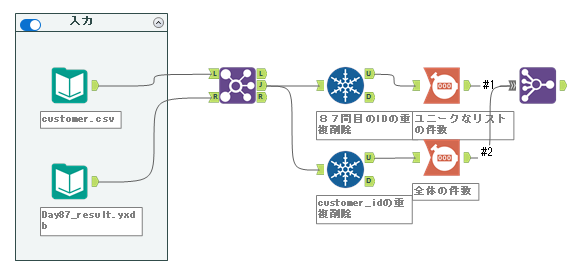
その後、フォーミュラツールで差分を取ります。フィールド名は「diff」、データ型は数値型にしましょう。
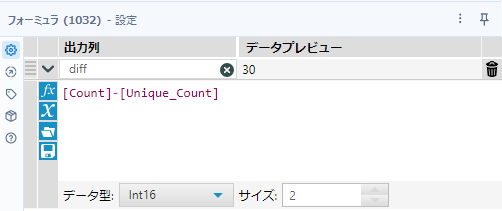
[Count]-[Unique_Count]これで完了です。最終的なワークフローはこちらです。
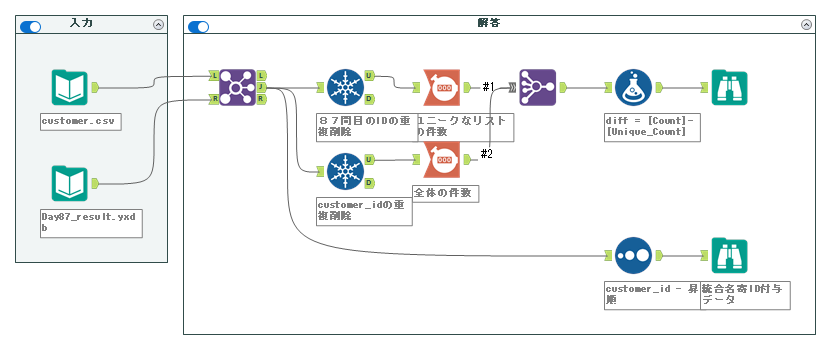
解答その2(2022/11/13追加)
結合ツールで結合するところまでは同じですが、カウントをもっとシンプルにしてみました。
集計ツールで重複を除いてカウントする機能を使うことでシンプルなワークフローにすることができます。つまり以下のように接続します。
設定は、以下の通りで、customer_id、unique_idともに「重複を除いてカウント」します。
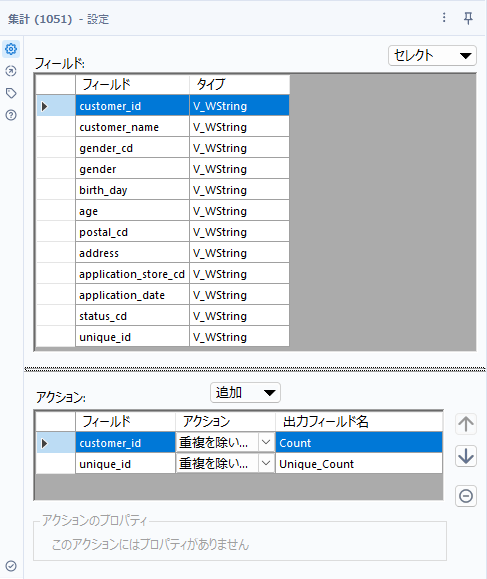
フィールド名はそれぞれ「Count」と「Unique_Count」と変更しておきましょう。
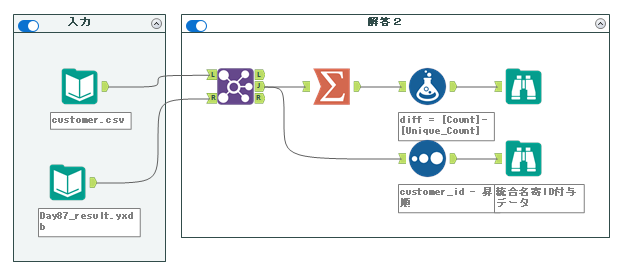
あとは、元の解答と同じく、フォーミュラツールで差分を取ります。
最終的なワークフローはこちらです。
まとめ
87問目の続きの問題で、名寄したデータの顧客IDを元のデータに付与する問題でした。現実的によくやる処理だと思いますので、参考にしていただければと思います。
解答ワークフローダウンロード
2022/11/13に別解追加と統合名寄ID付与データを追加しました。

コメント