
このページは解答編です。
↓ネ
↓タ
↓バ
↓レ
↓防
↓止
答えと解説
設問はこちらでした。
P-076: 顧客データ(customer.csv)から性別コード(gender_cd)の割合に基づきランダムに10%のデータを層化抽出し、性別コードごとに件数を集計せよ。
解答ワークフローは以下のようになります。
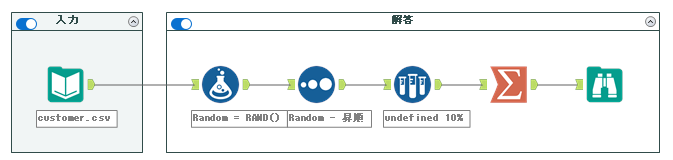
75問目に続き、ランダム抽出の問題です。
75問目で使ったランダム%サンプリングツールは各レコードのグループに対して実行することができないため、そのまま使えません。しかしながら、75問目の別解であれば、簡単に解決が可能です。
層化抽出とは
ところで、層化抽出という言葉に慣れていない方もいらっしゃるかと思います。
層化(Stratification)というのは、母集団を相対的に同質なグループに分けるプロセスで、分けられた母集団ごとに抽出を行うのが、層化抽出です。
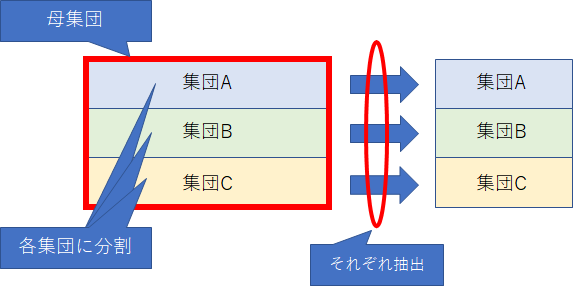
これによると、今回の場合は、gender_cdごとに10%のレコードをランダムに抽出できればオッケーです(そして、最終的にはそのカウントを取ることになります)。
ワークフロー
75問目の設定を少しだけ変えることで実は実現できます。
まず、フォーミュラツールでRAND()関数を使い、ランダムな値を取得します。フィールド名は「Random」、データ型はDouble型にします。
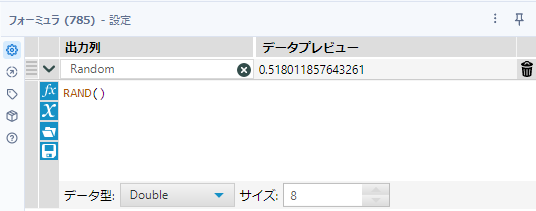
RAND()次に、取得したランダムな値(フィールド名「Random」)に対して、ソートツールを使って昇順(降順でも構いませんが)に並び替えます。
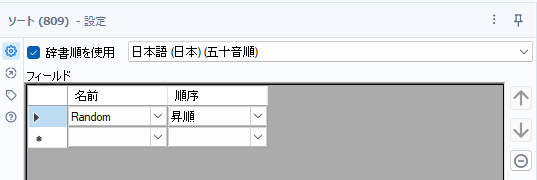
最後に、サンプリングツールを使って、「最初のN%の行」のオプションに10を指定し、10%のレコードを取得します。この時、75問目と大きく異なるのは、「列でグループ化する」オプションの「gender_cd」にチェックを入れることです。これで、チェックを入れたフィールドの値にもとづいてグループ化され、各グループごとに抽出が行われます。
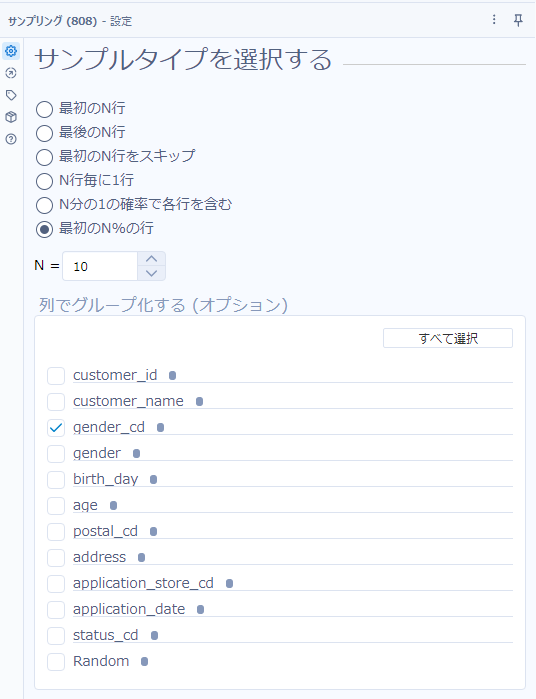
今回は解答としてカウント数が必要とのことなので、集計ツールでカウントを取っていきましょう。gender_cdでグループ化し、customer_idなどでカウントを取ればオッケーです(単純なカウントならどの項目でも結果は同じです)。
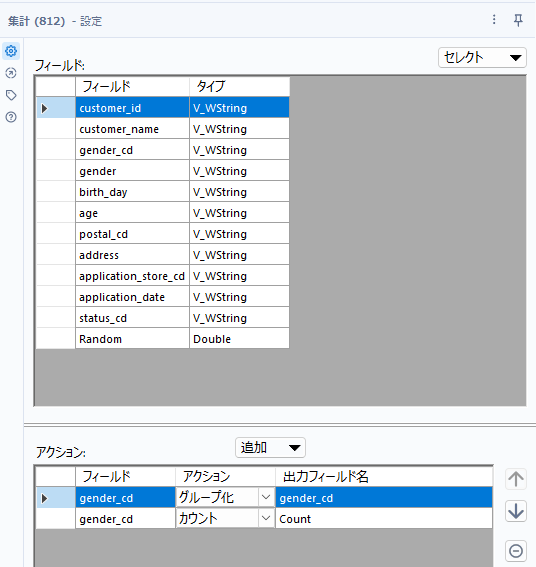
実際のワークフローは以下の通りとなります。
まとめ
今回は、75問目に続いてランダムにデータを抽出する問題でした。75問目の別解がほぼそのまま流用可能ということでした。

コメント