
このページは解答編です。
↓ネ
↓タ
↓バ
↓レ
↓防
↓止
答えと解説
設問はこちらでした。
P-093: 商品データ(product.csv)では各カテゴリのコード値だけを保有し、カテゴリ名は保有していない。カテゴリデータ(category.csv)と組み合わせて非正規化し、カテゴリ名を保有した新たな商品データを作成せよ。
※結果は、product_cdの昇順でソートし、先頭から10レコードを取得すること
解答ワークフローは以下のようになります。
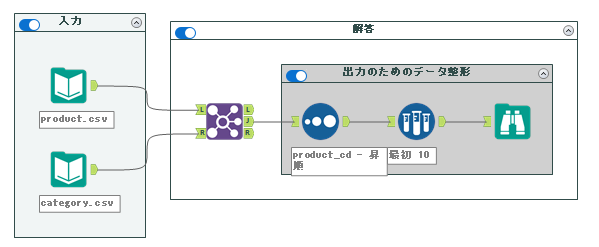
今回はリレーショナル・データベースで標準的に行われている正規化されたテーブルを非正規化する問題です。データベースに格納されているデータを分析する際、基本的には正規化されているため複数のテーブルのデータを扱わなければ分析ができないことが多いです。本問ではそのような際の処理方法を行う問題となります。
とはいえ、これまで普通にやってきた結合を行うだけです。結合ツールでキーフィールドをcategory_small_cdとします。
ちなみに、category_cdには三種類あり、カテゴリの粒度に応じたコードがあります。大きい方からcategory_major_cd、category_medium_cd、category_small_cdの三種類があります。それぞれ単体で機能するようになっているため、category_small_cdのみキーフィールドに指定すれば十分です。
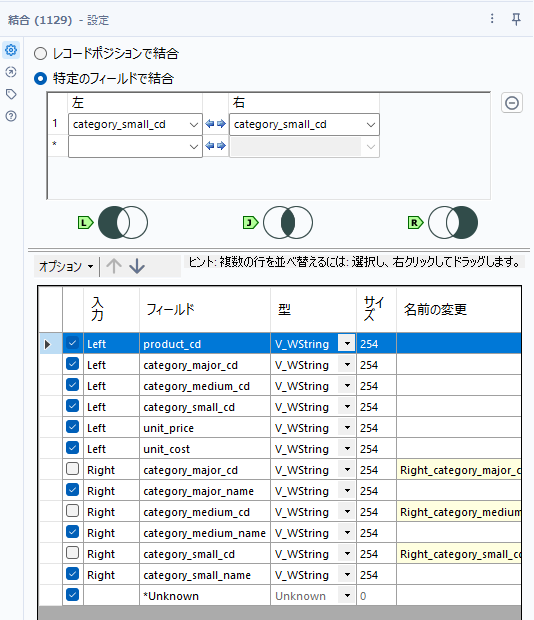
結合した時に重複する3つのフィールドcategory_major_cd、category_medium_cd、category_small_cdは削除しておきましょう。ちなみに、フィールド名が重複しているものがある場合は、自動的にフィールド名が変更されるようになっており、そのため「名前の変更」のところに黄色く変更される名前が記載されるため見た目にわかりやすくなっています。これらのみフィールドを削除したい場合は、オプションから「重複するフィールドの選択を解除」ボタンを使うのが便利です。
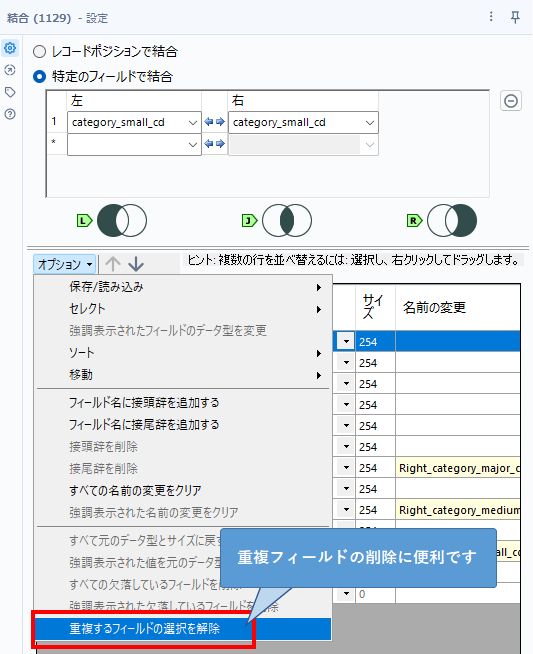
あとは、product_idの昇順に並べ替え、セレクトツール等で先頭から10レコード抽出すれば完了です。
まとめ
今回は非正規化を行う問題でした。データベースのデータを扱う場合は標準的に行われている内容となりますが、特に難しいものでもないかと思います。

コメント