
国勢調査の小地域(町丁・字等)のデータをAPIでダウンロードするブログの第二回目です。1回目はこちら。
前回、「統計表ID」が手に入ったのでまずひとつダウンロードしてみましょう。
統計データ取得APIを使う
今回は、「男女別人口総数及び世帯総数」をダウンロードしていきましょう。前回取得したデータに対してフィルタをかけていきます。
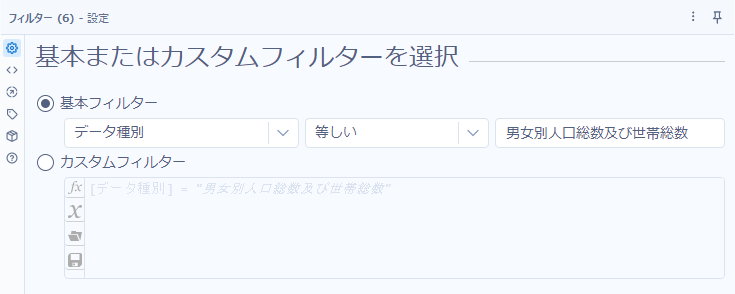
さて、まずアクセス用のURLを作っていきましょう。統計データ取得APIのエンドポイントURLは以下のようになります。
http(s)://api.e-stat.go.jp/rest/<バージョン>/app/getSimpleStatsData?<パラメータ群>今回は、CSV形式でダウンロードするためのURLです。XML形式にすると、項目数が多くなりすぎるため、XMLパースツールで項目ごとにフィールドにした際に非常にフィールド数が多くなりすぎるためあえて変えています(JSONで取得するという選択肢ならありかと思います)。
パラメータとしては以下のものを与える必要があります。
| パラメータ名 | 内容 | 与えるパラメータ | コメント |
|---|---|---|---|
| statsDataId | 統計表ID | statsDataId=[各レコードの10桁のId] | 都道府県ごとに異なります |
| startPosition | データ取得開始位置 | startPosition=[各レコードのスタート位置] | 10万行ごとにレコードの取得が必要 |
もちろん共通で必要となるappIdとlangは以前と同様必要です。
| パラメータ名 | 内容 | 与えるパラメータ |
|---|---|---|
| appId | アプリケーションID | appId=[ご自身のappId] |
| lang | 言語 | lang=J |
これにより、以下のようなURLとなります。
https://api.e-stat.go.jp/rest/3.0/app/getSimpleStatsData?appId=[appId]&lang=J&statsDataId=[id]&startPosition=[startPosition]これをフォーミュラツールにセットすると、以下のように数式化します。
"https://api.e-stat.go.jp/rest/3.0/app/getSimpleStatsData?appId="+[appId]+"&lang=J&statsDataId="+[id]+"&startPosition="+ToString([startPosition])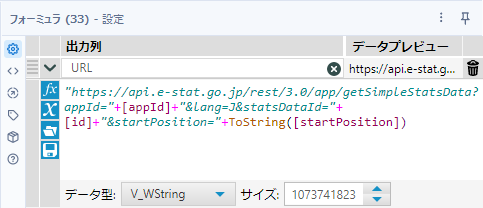
ここで作成したURLを使ってダウンロードツールでデータをダウンロードすればOKです。統計表情報取得APIと設定は同じです。

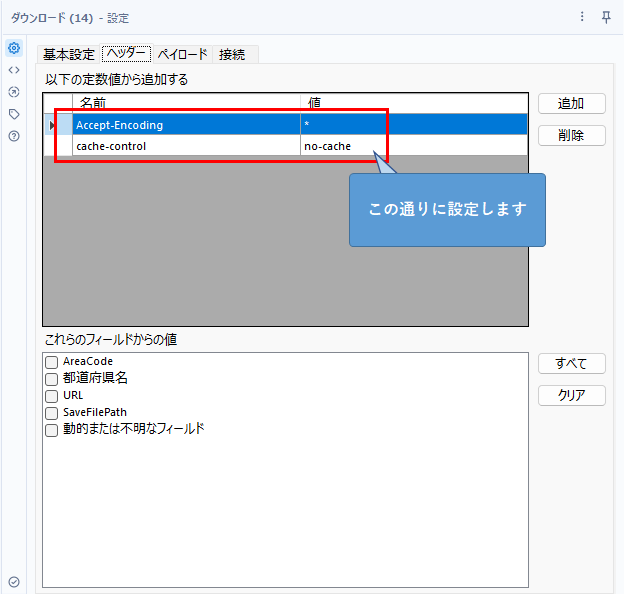
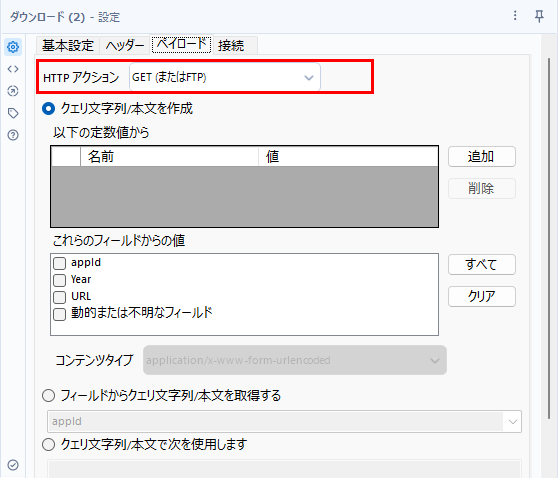
ダウンロードしたデータを加工する
CSV形式でダウンロードすると、レスポンスコードやメタデータなどが先頭に付加した形でデータがダウンロードされます。
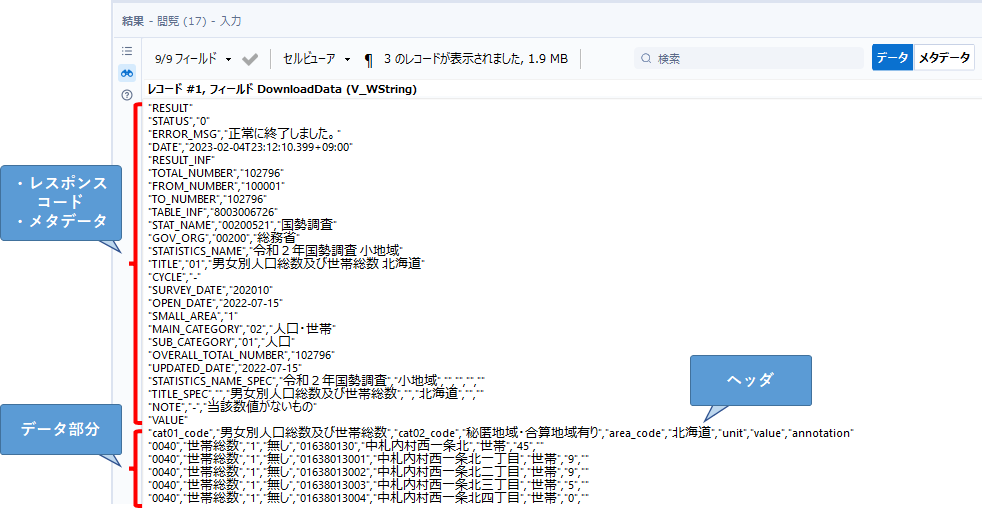
実際のデータ部分は「”VALUE”」の次の行から始まります。ヘッダ、そして実際のデータが続きます。
これを使えるように加工していく必要があります。
まず、最初の段階で、1つのレコードの中にすべて押し込まれていますが、このような場合は、最初に改行で分割する必要があります。これを行うには、列分割ツールを使います(列分割なのに行分割できるすぐれものです!)。
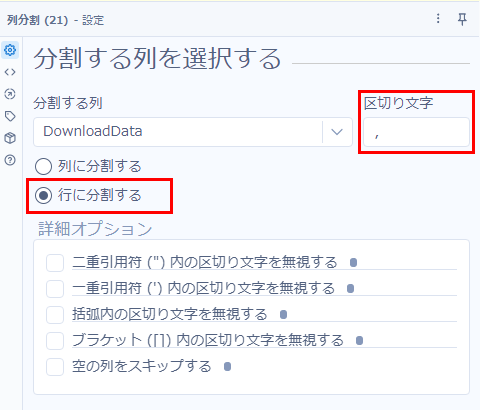
設定としては以下のような形で、区切り文字に「\n」を指定し、「行に分割する」を選択するだけです。

次に、最初に来ている不要なレスポンスコードなどを取り除いていきましょう。「”VALUE”」以降が欲しいデータなので、「”VALUE”」が出現するまで複数行フォーミュラで不要フラグをつけていきます。
設定は以下の通りで、新しいフィールドを作成し、データ型は「Bool」としています。また、複数のファイルを落としているので、グループ化を行い、各レコードごとに実施します。
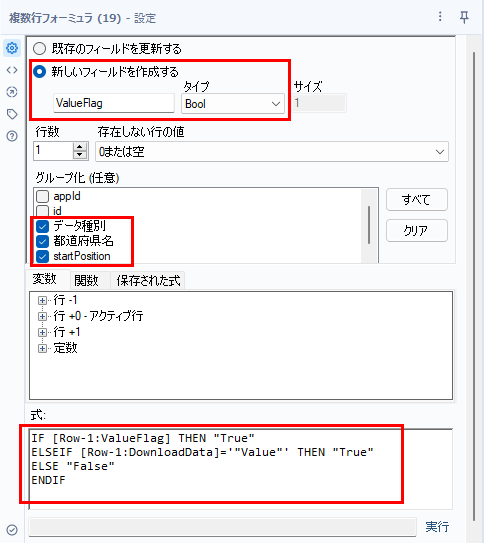
IF [Row-1:ValueFlag] THEN "True"
ELSEIF [Row-1:DownloadData]='"Value"' THEN "True"
ELSE "False"
ENDIF計算式の意味は、新しく作成したValueFlagフィールドがTrue(「”VALUE”」がすでに来ている状態)であれば、Trueを継続、DownloadDataフィールドが「”VALUE”」であれば、Trueにする。そうでなければFalseとする、といった内容です。
その後、フィルタツールでValueFlag=Trueを残すと、以下のようなデータが得られます。
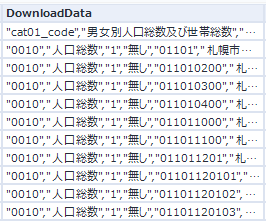
ここまでで以下のようになっています。
ここからフィールドに分割していきましょう。各行を特定できるよう、レコードIDツールでレコード番号をつけておきます。
次に、フィールドに分割していきたいのですが、特定のデータであればフィールドの数は決まっていますが、毎回フィールド数を変更するのは面倒です。そこで、フィールド数が異なっても動くように動的なワークフローにしていきたいと思います。
基本的な考え方としては、一度行に分割し、タイルツールや複数行フォーミュラツールで列のポジションを特定し、クロスタブでもとに戻す、というのが定石です。
ということで、再度列分割ツールの出番です。今回は、区切り文字を「,」(カンマ)として、行に分割しています。
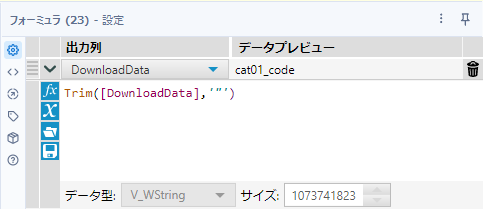
その後、ダブルクオテーションがじゃまなので、フォーミュラツールで削除しましょう。Trim関数に文字列指定オプションがあるので、これを使います。
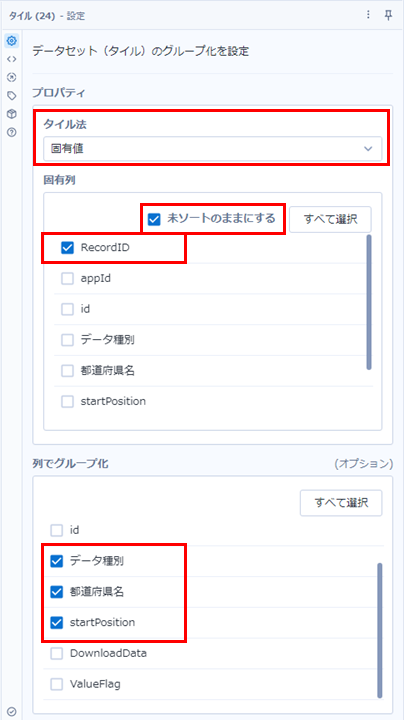
次に、タイルツールでフィールドの位置を取得します。これはマルチフィールドフォーミュラでも構いません。タイルツールの場合は、タイル法に「固有値」を選択します。固有列に何を選択するか、がポイントですが、「RecordID」を選択します。グループ化はダウンロードした際のレコード単位で行うため、「データ種別」「都道府県名」「startPosition」でグループ化します。
一つ忘れないように、「未ソートのままにする」はオンにしておきます。グループ化を使うと並び替わってしまうので。
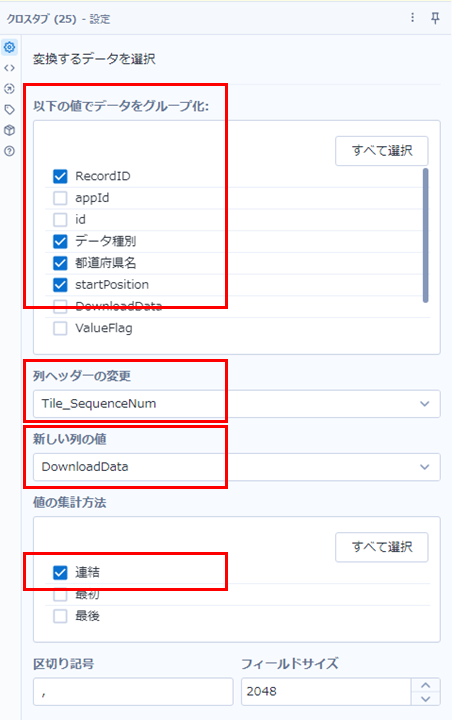
これにより得られるTile_SequenceNumは、固有値(各行番号が今固有値となっています)の中で先頭からどこにあるか、というのを取得しているため、これがクロスタブツールでの新しいフィールド名になります。
ということで、クロスタブで横持ちにしていきます。
グループ化オプションは、RecordIDはかならず必要ですが、それ以外は残しておきたいフィールドがあれば問題ありません。列ヘッダーは「Tile_SequenceNum」、新しい列の値は「DownloadData」、値の集計方法は、「連結」でオッケーです(実質なんでもオッケーです)。
ここまででほぼデータはできあがりましたが、フィールド名をつける必要があります。以下のようにクロスタブで横持ちにした部分は、フィールド名が番号になってしまっています。

セレクトツールで固定でリネームしてもいいのですが、動的リネームで最初の行からフィールド名を拾ってみましょう。設定は以下の通りで、「データの最初の行からフィールド名を取得」を選択します。すでに名前がついているフィールドのチェックは外します。
「2」はデータ種別によって名前が変わるため、これは固定で変えます。
「6」は都道府県名が1行目になぜか入っているので(これも元のデータの作り方のセンス悪いですよね)、1行目から取得せずあとで固定で名前をつけます(本来は動的にやりたかったのですが、「男女別人口総数及び世帯総数」以外のデータも同じ構成だったので固定で問題ないと思います)。

最後に、都道府県ごとにフィールド名が取得されてしまっているのですが、最初のデータのみフィールド名として使っており、残りのフィールド名部分が残ってしまっています。そのためフィルタで削除します。「unit」フィールドから値が「unit」以外のデータを残していきます。
これでワークフローとしては完成です。最後にデータ出力ツールなどで保存していきましょう。データ種別ごとに保存しておきたいと思いますので、以下のように設定します。
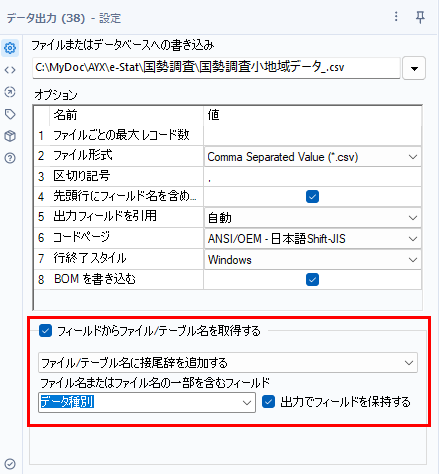
ポイントは、下の赤い部分で、「フィールドからファイル/テーブル名を取得する」オプションにチェックを入れ、「ファイル/テーブル名に接尾辞を追加する」を選択、フィールドとしては「データ種別」を選択します。これにより、「データ種別」フィールドの値に応じてファイルが分割されて保存されます(その際、ファイル名の最後にデータ種別のフィールドの値が付加されます)。
例えば、データ種別が「世帯の家族類型別一般世帯数」の値ものがあれば、これが1つのファイルにまとまって「国勢調査小地域データ_世帯の家族類型別一般世帯数.csv」のような形で保存されます。
ここまでの部分で以下のようなワークフローになっています。

前回の記事も含めてのワークフローの全容としては以下のようになります。

実は、この状態でも縦持ちのデータになっており、次回は、人間が見やすいデータに加工していきます。
サンプルワークフローダウンロード
おまけ
最初、単一のデータ種別「男女別人口総数及び世帯総数」に対してデータ処理を行っていったのですが、データ種別は複数存在しています。データ種別によってデータの構成が異なると想定して進めたので一度バッチマクロ化しました。保存結果を調べてみると、基本的なデータ構成は同じだったので最終的にはバッチマクロなしのワークフローとなりました。
コメント