
このページは解答編です。
↓ネ
↓タ
↓バ
↓レ
↓防
↓止
答えと解説
設問はこちらでした。
P-013: 顧客データ(customer.csv)から、ステータスコード(status_cd)の先頭がアルファベットのA〜Fで始まるデータを全項目抽出し、10件表示せよ。
解答ワークフローは以下のようになります。今回は様々な回答が可能となっています。
基本的にはフィルターツールを使いますが、様々な手法が可能です。
- StartsWith関数
- Left関数+IN演算子
- Left関数 別解1
- Left関数 別解2
- 正規表現ツール
- 検索置換ツール
どれを選ぶべきか、というところは、条件次第です。単純な条件だと単純な方法(1~4)で問題ないですし、条件が多い場合であれば複雑な方法(6)を使った方が結果的に楽だったりします。
1. StartsWith関数
「ステータスコード(status_cd)の先頭がアルファベットのA〜Fで始まる」ということなので、StartsWith関数が利用可能です。ただ、条件としてA~Fとなると6個あるため書くのが面倒である、という難点があります。
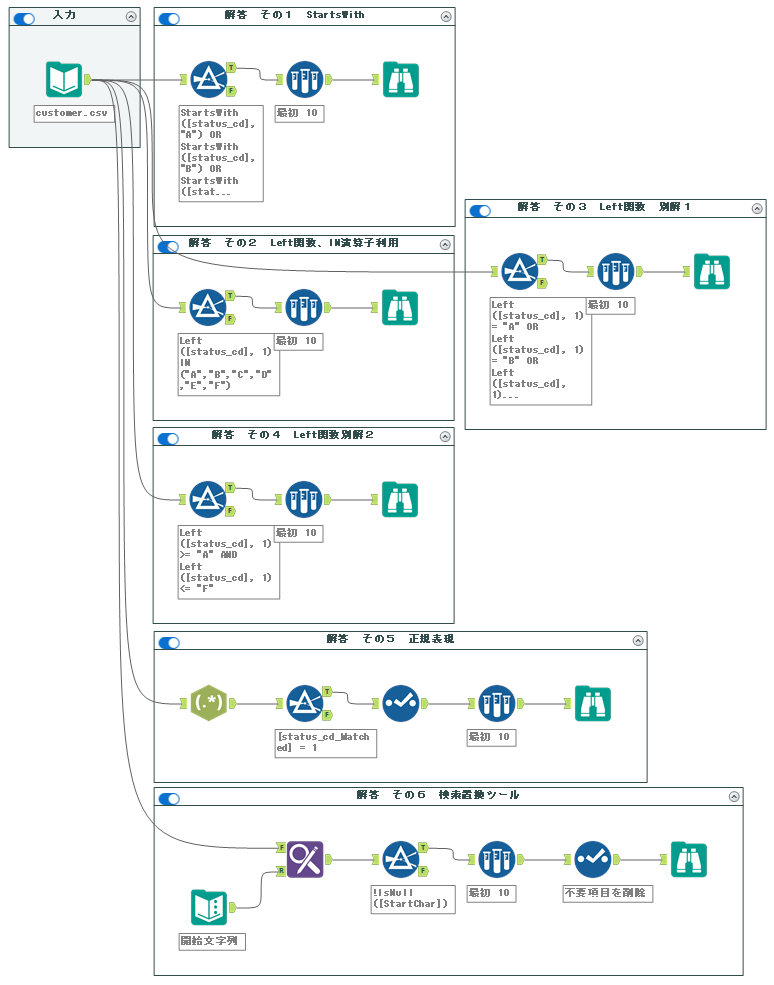
StartsWith([status_cd], "A") OR
StartsWith([status_cd], "B") OR
StartsWith([status_cd], "C") OR
StartsWith([status_cd], "D") OR
StartsWith([status_cd], "E") OR
StartsWith([status_cd], "F")実際のフィルターツール設定は以下の通りとなります。
ワークフローとしては以下の通りとなります。
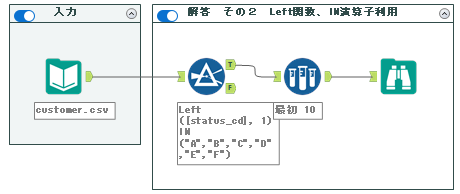
2. Left関数+IN演算子
次に少し楽をしてみたいと思います。Left関数で一文字切り取り、IN演算子で比較することが可能です。複数のもののいずれかに一致するかどうか、を評価するにはIN演算子が非常に便利です。
今回であれば、以下のようになります。
「含む」という場合はContains関数を使います。関数の使い方としては、
Contains(検索先文字列, 検索文字列)
となります。つまり、今回であれば以下のようになります。
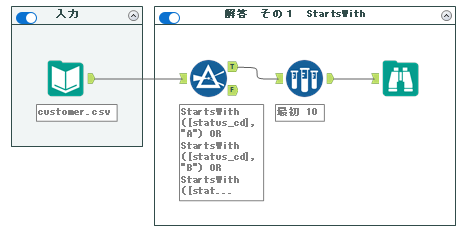
Left([status_cd], 1) IN ("A","B","C","D","E","F")このように書くことで、Left関数で切り取った文字がA~Fのいずれかに一致指定いればTrueと判断されます。
フィルターツールの設定は以下のとおりとなります。
ワークフローは以下の通りとなります。
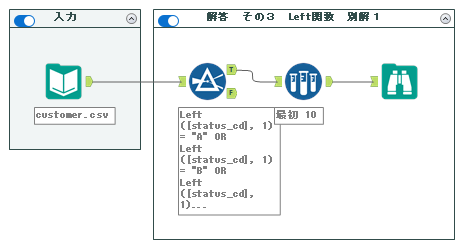
3. Left関数 別解1
もちろん、以下のように書くこともできます。
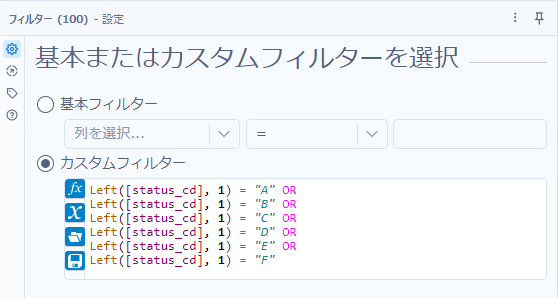
Left([status_cd], 1) = "A" OR
Left([status_cd], 1) = "B" OR
Left([status_cd], 1) = "C" OR
Left([status_cd], 1) = "D" OR
Left([status_cd], 1) = "E" OR
Left([status_cd], 1) = "F"非常に基本的な書き方ではありますが、書くのが少し面倒かもしれません。
フィルターツールの設定は以下のとおりとなります。
ワークフローは以下の通りとなります。
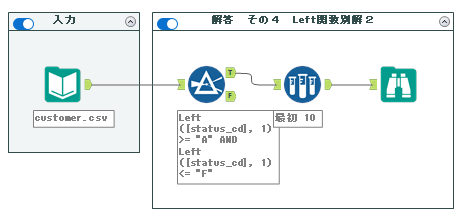
4. Left関数 別解2
その他、以下のように書くこともできます。いわゆる大小比較ですが、条件がA~Fという形で連続しているためこのような書き方ができます。
Left([status_cd], 1) >= "A" AND
Left([status_cd], 1) <= "F"
実際のフィルターツールの設定は以下の通りです。
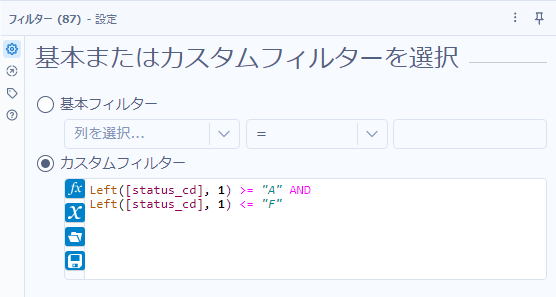
ワークフローは以下の通りとなります。
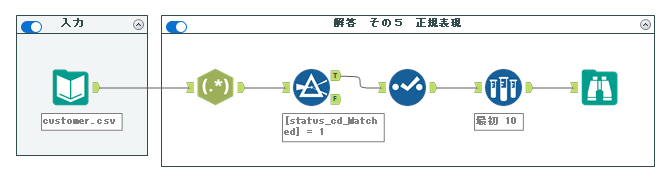
5. 正規表現ツール
若干高度な手法になりますが、正規表現ツールを使うこともできます。
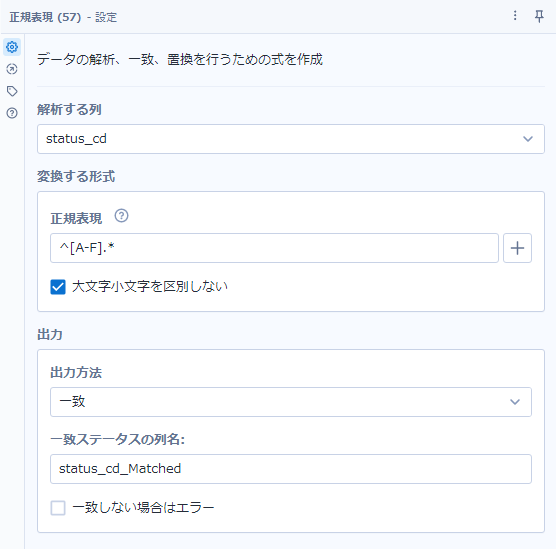
今回は、「ステータスコード(status_cd)の先頭がアルファベットのA〜Fで始まる」ということなので、「^[A-F].*」という式になっていますが、それぞれ以下のような意味となります。
^ : 行頭であることを示します
[A-F] : AからFのうちのいずれか1文字ということを示します
.* : 0文字以上の文字列を示します(「.」は文字1文字(アルファベットでも記号でも数字でもなんでもよいです)、「*」は直前の文字0以上の繰り返し、を意味します)
「^[A-F].*」により、「行頭でA~Fのいずれか一文字で開始される」という意味となります。実際のツールの設定は以下の通りです。
実際のワークフローは以下のようになります。
6. 検索置換ツール
こちらは、開始文字列が複雑な場合でも対応できる応用的な内容となります。今回のようにA~Fで始まる、程度であればわざわざこのようなワークフローを作る必要はありませんが、開始文字列が数多くあったり、文字数もバラバラといった場合に使用できる方法となります。
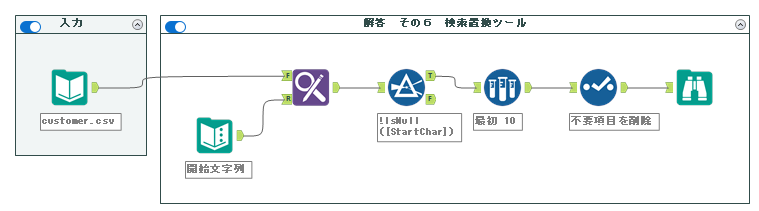
ワークフローの方針としては、開始文字列のリストを作っておき、検索置換ツールを使ってそのリストと比較します。先頭一致したレコードだけデータが付加され、先頭一致しなかったレコードの値はNullとなります。先頭一致しなかったレコードをフィルターツールで「Nullではない」という設定で除去することで先頭一致しているレコードが得られます。
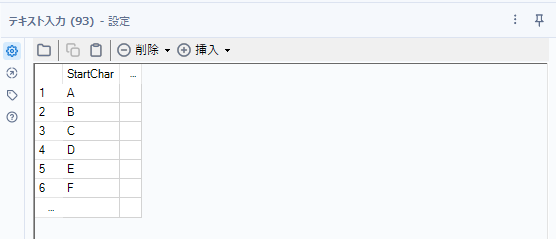
今回であれば、以下のようなリストをテキスト入力ツールで作っています(もちろんExcelファイルなどで作成しておき、データ入力ツールで読み込むことも可能ですが、このようなちょっとしたリストを作成したい場合は、テキスト入力ツールが便利です)。
検索置換ツールは、ExcelのVlookup関数みたいなツールで、F入力にメインの入力をインプットし、R入力側に置換リスト、もしくは今回は付加用のリストを入力します(今回はテキスト入力からの出力をインプットします)。
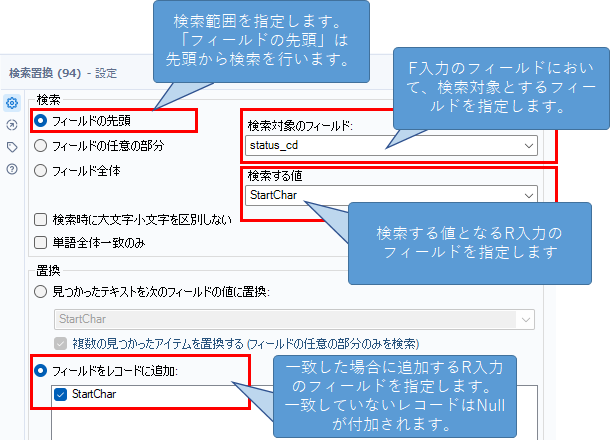
実際の設定は以下の通りとなります。検索条件は、「フィールドの先頭」を選択しましょう。検索対象のフィールドは、F入力のキーとなるフィールドですので、「status_cd」となります。
検索する値の方は、R入力のキーとなるフィールドなので、「StartChar」を選択します。
また、今回の置換オプションは、「フィールドをレコードに追加」とします。これにより、一致しないレコードについてはNullとなります。
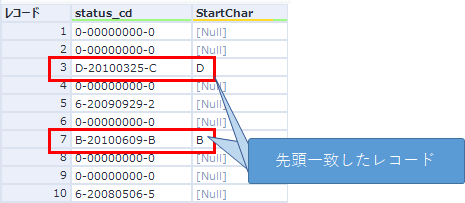
つまり、上のような設定で、status_cdに対してStartChar(A~F)を先頭一致させると、以下のようになるので、StartCharがNullになっているレコードをフィルタで削除します。
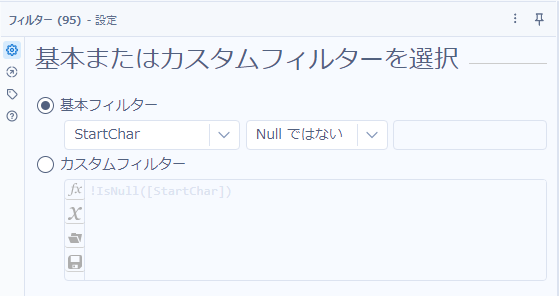
最後にNullとなるデータを取り除くためにフィルターツールを設定します。基本フィルタで「Nullではない」となります。
以上となります。
今回の問題は様々なパターンでの解答が可能で、内容的にも盛りだくさんとなりました。一度に覚える必要はないので、基本的な内容から抑えましょう。複雑な方法は将来的に使う可能性があるので、頭の片隅にでもおいといていただければと思います。

コメント