
Alteryx Predictive Master資格取得を目指すシリーズです。
クラスタリングは教師なし学習でグループ化を行うことを言います。
クラスタリングは、ある特定のアルゴリズムでデータを分類するものなので、分類されたグループの解釈自体は分類されたあとに行います。様々なアルゴリズムがあり、PythonのScikit-learnなどのライブラリでは非常に多くの手法を利用することが可能です。
Alteryxで利用できるクラスタリングは、K-Means法(K平均)、K-Medians法、Neural-Gas法(ニューラルガス)の3種類ですが、基本的に距離ベースの方法なので似たような手法になります(距離の計算方法が若干異なります)。
いずれの手法もパラメータは同じ為、一つのツールにて設定の変更で使い分けることができます。
K-MeansとK-Medians、Neural-Gasの違い
K-Means
距離の計算にはユークリッド距離を用います。クラスターの決定には平均値を用います。
K-Medians
距離の計算にはマンハッタン距離を用います。そのため、離散値のクラスタリングに向いています。クラスターの決定には中央値を用います。
Neural-Gas
距離の計算にはユークリッド距離を用いますが、計算の際に重み付けを行います。クラスタに属しているポイントの重みを大きくする、というアルゴリズムです。
AlteryxのK重心クラスター分析ツールを使ってみる
分析するデータの注意
- 数値フィールドのみ対応
- 最低2つのフィールドを選択する必要があります
- Null値は含むことができません → Nullは除去するか平均値等で補完しましょう
- 外れ値の影響を受けやすいです → 外れ値を除去しましょう
ツールは3つセットです
Alteryxでクラスター分析する場合、以下3つのツールを組み合わせて使う必要があります。
- K重心クラスター分析ツール
- K重心診断ツール
- クラスター付加ツール
基本的には、「K重心診断ツール」でクラスタ数を決定し、「K重心クラスター分析ツール」でクラスタリングを行い、「クラスター付加ツール」でクラスタ番号を元データに対して付与していきます。正直、「K重心クラスター分析ツール」と「クラスター付加ツール」はまとめてほしいところです・・・。
サンプルワークフローとしては、「ヘルプ」-「サンプルワークフロー」-「Predictive tool samples」-「Predictive Analytics」の「7_K–Centroids_Cluster_Analysis_Sample」です。ただし、「K重心クラスター分析ツール」と「クラスター付加ツール」のみで構成されています。
実際に使うユースケースを考慮し、アヤメのデータを使ってサンプルワークフローを作成すると以下のようになります。
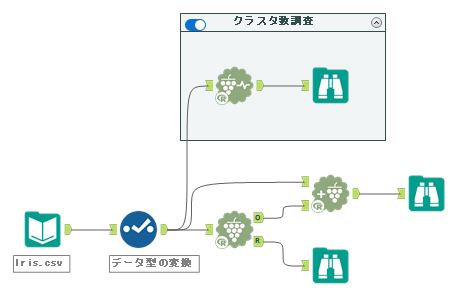
各ツールを使ってみる
K重心クラスター分析(K-Centrooids Cluster Analysis)ツール

K重心クラスター分析ツールは、K-Means、K-Medians、Neural Gasの3つのアルゴリズムを指定してデータを分類する教師なし学習のクラスタリングを行うツールです。設定は以下の通り。
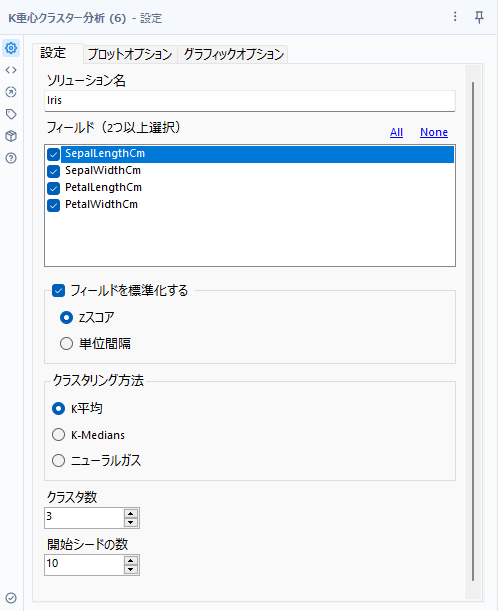
ソリューション名
モデル名を入力しましょう。
フィールド
クラスタリングに使うフィールドを指定します。
フィールドを標準化する
入力されたデータを標準化します。K-Centroidsで使うK-Means、K-Medians、Neural-Gasは距離ベースでクラスタリングを行うため、入力された値の範囲の影響を大きく受けます。そのため、基本的には標準化を行い、すべての入力されたフィールドを同じような値の範囲にしてクラスタリングを行うことで精度を向上させます。ただし、緯度、経度など標準化しない方が良いものもあるので、入力するデータに応じて設定しましょう。
Zスコア
Zスコアは、(各値-平均値)÷標準偏差で求めます。すなわち平均値が0、標準偏差が1となるようなフィールドにスケーリングされます。データサイエンス100本ノックでも標準化として出てきました。
単位間隔
(各値-最小値)÷(最大値-最小値)で求めます。すなわち、0から1の値の範囲に収まるようにスケーリングされます(最小値が0、最大値が1)。データサイエンス100本ノックでは正規化と呼んでいました。
クラスタリング方法
先に説明したよう、K平均(K-Means)、K-Medians、ニューラルガス(Neural Gas)の三種類から選択可能です。
クラスタ数
クラスタ数を設定します。2~70までが設定可能です。
基本的にK-Means、K-Medians、Neural-Gasについては最初にクラスタ数を決めて計算する必要があります(初期ポイントの数=クラスタ数になり、そこから計算を行っていきます)。最適なクラスタ数は、K重心診断ツールを使って検討することが可能です。
クラスタ数自体も自動的に決めさせたい、ということであれば全く別のアルゴリズムを使う必要があります。その場合は、Alteryxの標準ツールには実装されていないため、RやPythonツールで実装する必要があります。
開始シードの数
クラスタリングでは初期のポイントを決める際にランダムで決まります。この最初に選んだポイントが影響を与えることがあり、この影響をなくすために複数回初期ポイントを選び直してその中から良いものを選択する、ということを行っています。もちろん値が大きいとその分計算量が増えるため時間がかかります。
クラスター付加(Append Cluster)

クラスター付加ツールは、K重心クラスター分析ツールで作成したモデルを使って、元のデータに対してクラスタ番号を付加するためのツールです。
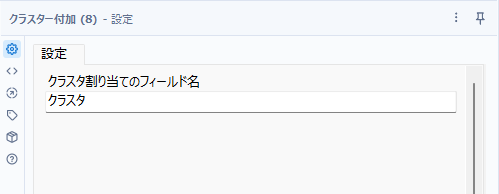
設定は、クラスタ番号が割り当てられるフィールド名のみとなります。
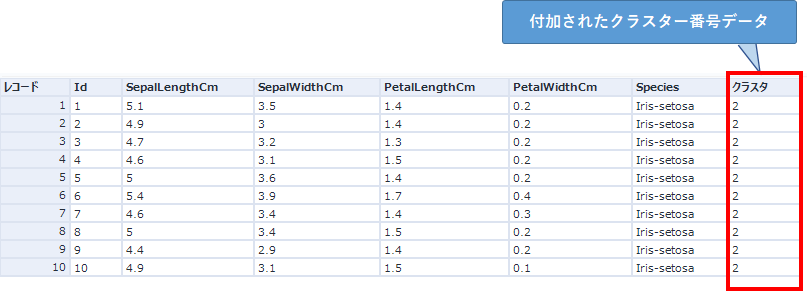
入力が2つあり、何も書かれていないのでわかりにくいのですが、上側の入力は元のデータ(K重心クラスター分析ツールに入力したデータ)、下側の入力は、K重心クラスター分析ツールのO出力のデータを入力します。(2023/11/23に修正)
入力は2つありますが、元のデータ(K重心クラスター分析ツールに入力したデータ)とK重心クラスター分析ツールのO出力のデータを入力します。特にどちらのインプットがどちらという決めはありません。
つまり、以下のように接続します。
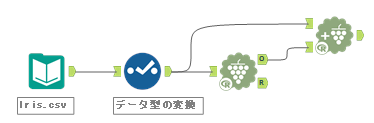
これにより、以下のようにデータが付加されます。
K重心診断(K-Centroids Diagnostics)ツール

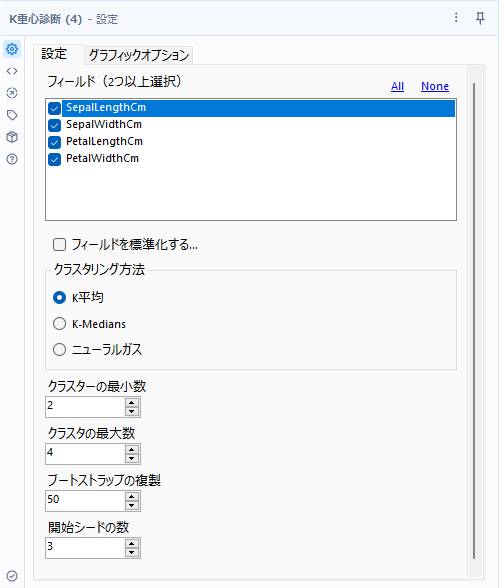
設定は上のスクリーンショットの通りで、基本的なパラメータはほぼK重心クラスター分析ツールと同様です。違いは、「クラスタの最大数」「ブートストラップの複製」の2つです。
クラスタの最大数
クラスタ数を調べるために使うツールですので、クラスタがとりうる最大数を設定し、そこまでの数に対して計算を行います。
ブートストラップの複製(Bootstrap Replicates)
2つのインデックスを計算するためのブートストラップ複製の数。50~200が指定可能です。デフォルトでは最低値の50となっていますが、推奨としては100以上とヘルプに記載されています。ただし、このパラメータは計算量を大幅に増やすので利用する際は気をつけましょう。
※日本語のWEBのヘルプより英語のヘルプの方が正確なのでヘルプを見る時は英語版で見ることをおすすめします
レポートを読み解く
レポートは、テーブルデータと箱ひげ図の二種類で提供されます。中身としては、以下の二種類が提供されます。
- 調整ランド指数(The adjusted Rand index)
0~1間の数値を取り、2つのクラスタリングの類似性を示す。1に近いほど2つのクラスタリングが似ている、ということになります。と言われてもよくわからないので、2回クラスタリングした際に各レコードが同じクラスタに入るかどうか、ということで良いと思います。ここで、2つ、というのは同じデータセットの異なるサンプルで行うようです。クラスターの再現性を図っているようです。
- Calinski-Harabasz指数(Calinski–Harabasz index)
0~1間の数値を取り、各クラスターが十分離れているか、という指標です。
さて、テーブルデータは箱ひげ図の元データなので、箱ひげ図を見ていきましょう。
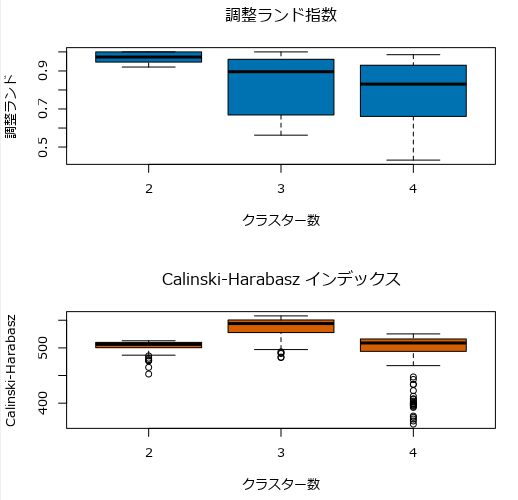
選択基準としては以下のとおりです。
- 値が大きい
- 箱ひげの箱のサイズが小さい方が良い
この基準に沿うと、クラスター数は3が妥当ではないかと思います。正直2と3どっちを選ぶのか、難しいところです。経験的には、Calinski-Harabasz指数が最も大きいものが良さそうです。
サンプルワークフロー
サンプルワークフローは、アヤメ(Iris)を使ったクラスタリングです。機械学習の入門でよく見るデータセットです。
このデータセットには、3種類のアヤメの品種(setosa、versicolor、virginica)が含まれており、それをSepal(がく片)、Petal(花びら)の幅と長さで見分ける、ということが可能です。

参考記事
Tool Mastery | K-Centroids Cluster Analysis
ツールマスタリーは非常に良い記事となっています(英語記事ですが、翻訳でなんとかなります)。これがあれば、インタラクティブレッスン見なくても良い感じです。
Predictive Grouping
インタラクティブレッスンです。3分と短いです。予測グルーピングカテゴリについての概要の説明です。クラスタリング(K重心クラスター分析)、主成分分析(PCA)、最近傍探索の3つについて触れられています。なお、同じ予測グルーピングのMBについては触れられていません。
Clustering in Designer
インタラクティブレッスンです。16分間で、みっちりK重心クラスター分析等の3ツールについて説明されています。
コメント