
Alteryx Predictive Master資格取得を目指すシリーズです。
機械学習を行う際、機械学習モデルに入力するためにデータクレンジングを行ったり、不要なフィールドを削除する必要があります。
気をつけるべきポイントは以下のとおりです。
- 適切なデータ型にする
- Null、空白、N/Aなどの欠損値(Missing Value)の扱い
- 外れ値(Outliers)を削除
- スケール
- ID(ユニーク値)、定数(単一値)は削除
これを確認するためのツールが、フィールドサマリーツールです。
フィールドサマリーツール(Field Summary Tool)

設定はシンプルです。サマリー情報を取得したいフィールドにチェックを入れるだけです(その他、サンプリングするオプションもあります)。
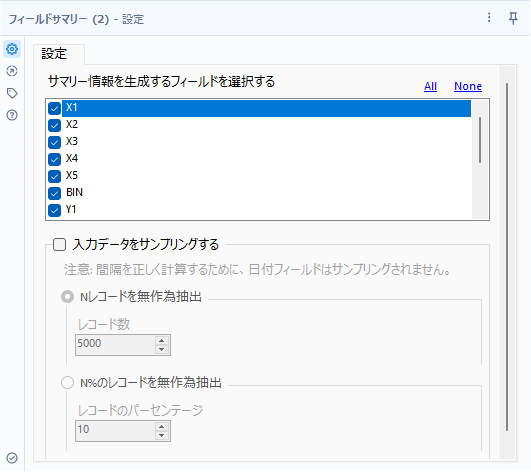
結果は、テーブル形式で確認できるO出力、レポートが見られるI出力、R出力がありますが、O出力で見てみましょう。
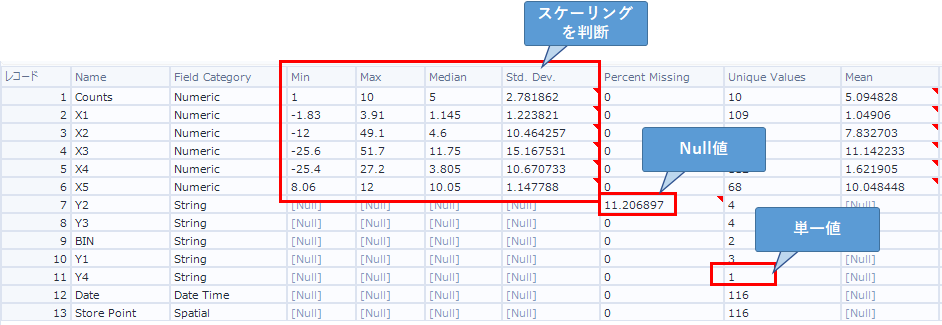
データの型によって出力される項目は異なります(ここでは特に記載しません。ヘルプを参照ください。)
例えば、数値型であれば、Min、Max、Std.Devを見て、フィールド間で差が大きいようであれば、標準化など行いましょう。
Percent Missingを見ると、Null値がどれくらいあるかわかります。Null値があるのであれば、何かしら補完を行いましょう(インピュテーションツールやフォーミュラツールを使うことになると思います)。一般的に推奨とされる補完方法は以下の通りです。
- 数値:中央値
- カテゴリ値:ユーザー定義の定数にする
- ブール値:最頻値
Unique Valuesは、ユニーク値がいくらあるかわかります。レコード数と同じ場合、すべて異なる値、ということになります。また1の場合は定数的なフィールドにあるので、これも機械学習には使えません。
なお、CSVファイルなど入力データの型が適正化できていない場合、オートフィールドツールなどで適正な型にしたあとでフィールドサマリーツールを使いましょう。
分布分析ツール(Distribution Analysis Tool)
分布分析ツールは、連続値がどのように分布しているか、正規分布(Normal)なのか、対数分布(Log-Normal)なのか、ワイブル分布(Weibull)なのか、ガンマ分布(Gamma)なのか、どのタイプの分布に近いのかを判断するためのツールです。
ツールの使い方としては、分析したいフィールドを選択肢、比較したい分布にチェックを入れるだけです。
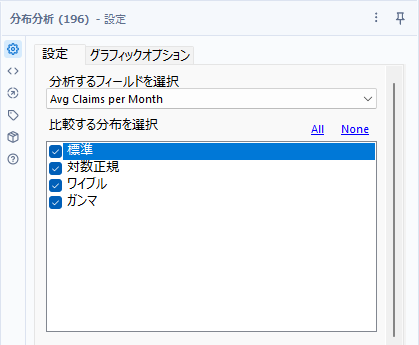
通常使うのは、正規分布(標準)、対数分布(対数正規)、ガンマ分布くらいでしょうか・・・。
これにより、以下のようなレポートが得られます。
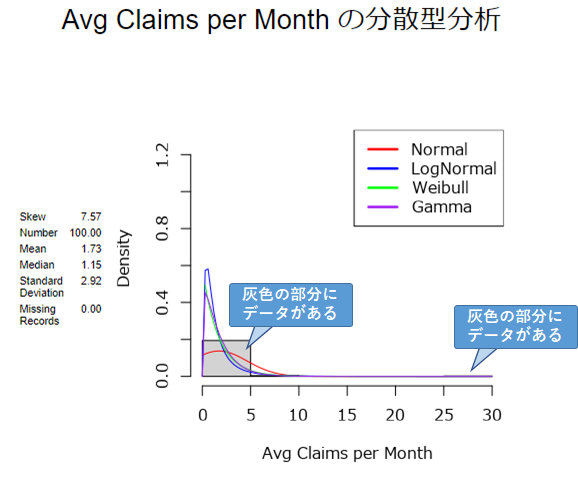
今回のデータは、x軸で見た時に0~5の間にほとんどのデータが存在し、少量のデータが25~30の間に分布しています。データが分布質いるところには、灰色でグラフが描かれます。
それ以外、線グラフは各分布がどうあるべきか、というのが比較対象として書かれており、それぞれの線グラフに近い分布になっているかどうかを判断する、ということになります。
ただ、このグラフからの判断は難しいので、レポートの続きの部分にある各検定を見てみましょう。
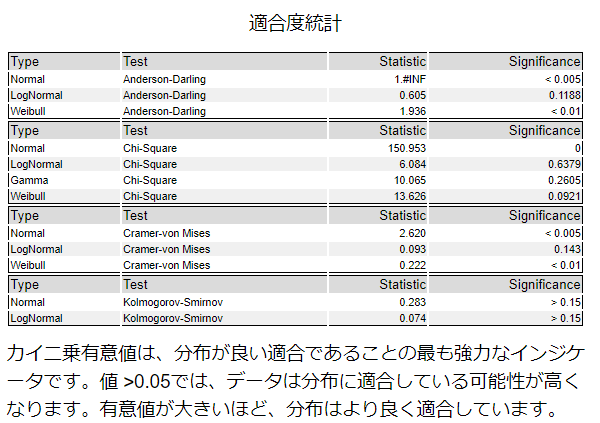
このツールでは、4つの検定方法で検定を行っています。レポートにも「Chi-Square(カイ二乗検定)がわかりやすい」とある通りChi-Squareを見てみると、Significanceの項目のLogNormal(対数)が0.63と一番大きくなっているため、対数分布に近そうです。
実際ヒストグラムを作ってみると以下のようになります。
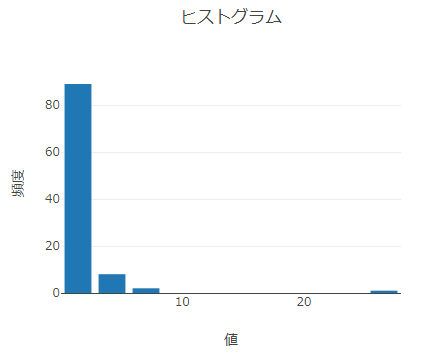
これにより、機械学習の回帰モデルを選択する際にどれにするか、という参考になります(正規分布であれば、線形回帰モデル、ガンマ分布であれば、ガンマ回帰モデルを選ぶことになるかと思います)。
度数分布表ツール(Frequency Table Tool)

テキスト、整数フィールドについてさらにデータを深掘りする際に役に立つのが度数分布表ツールです(Double、FixedDecimal、Date、Time、DateTime、Blob、SpatialObj型には対応していません)。
これは、データの各値が何回あるか、というのを表にしたものです。そのため、基本的にはカテゴリデータ(整数、テキスト)に対して、どのような値が何度出現しているか、というデータの散らばりを確認できるツールです。フィールドサマリーツールでは、あくまでフィールドのサマリーを表示していましたが、度数分布表ツールはさらに踏み込んでデータを確認するツールです。
例えば、以下のようなレポートを確認できます。
各フィールドごとにテーブルがレポートとして出力されていますが、各値ごとに頻度と占める割合、表の上からの累計数・割合が表示されています。
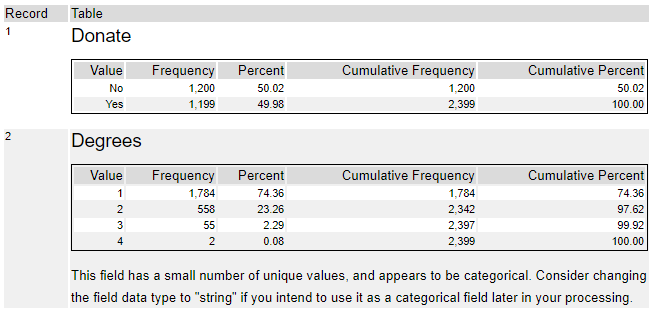
また、Record2のDegreesというフィールドに対しては、これは少ない数のユニークな数値になっているので、カテゴリ変数ではないか?ということを示唆しています。
また、インタラクティブ出力(I出力)では、グラフでも出力してくれます。
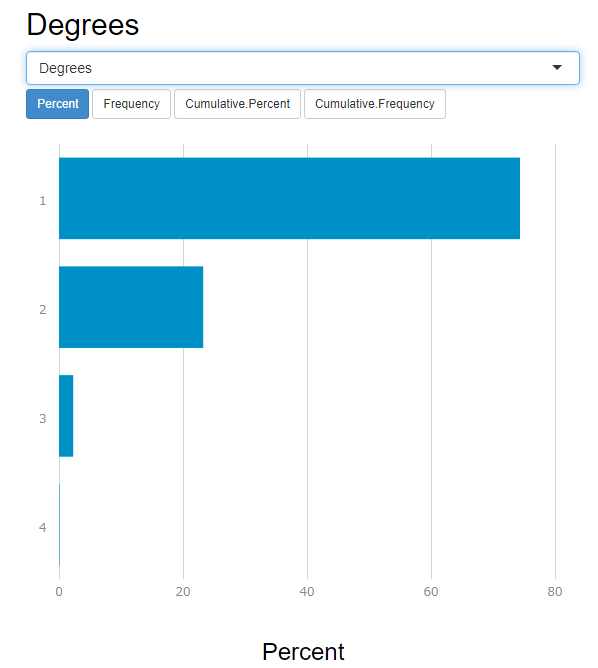
こちらの方が分布のイメージは湧きやすいかもしれません。
参考資料
Data Investigation Concepts
Data Investigation Conceptsは、インタラクティブレッスンです。英語しかありませんが、データ調査の重要性について解説されています。
Data Investigation Techniques
Data Investigation Techniquesはインタラクティブレッスンです。F1のデータを使って実践的な解説が行われます。
How To: Complete Data Preparation And Investigation For Predictive Modeling
How To: Complete Data Preparation And Investigation For Predictive Modelingは、ナレッジベースです。予測モデルのためのデータ調査です。多重共線性(マルチコ)や統計的に有意かどうかということにも触れられています。
Pre-Predictive: Using the Data Investigation Tools – Part 2 of 4
Pre-Predictive: Using the Data Investigation Tools – Part 2 of 4は、度数分布表ツール、分割表ツール、分布分析ツールについて解説されています。
次回は、予測モデルのために、どのようにして予測変数を選択するか、を見ていきたいと思います。
※2023/02/26に度数分布表ツール、分布分析ツールの説明を追加しました
コメント