
今回は、Alteryxでクラスタリング(K重心クラスター)する際に、フィールドを標準化する効果を見てみたいと思います。
前提
今回使うデータは、scikit-learn付属のワインの区別のデータセットを使いたいと思います。こちら(uci大学)からダウンロード可能です。
データの中身としては、以下のようになっています。
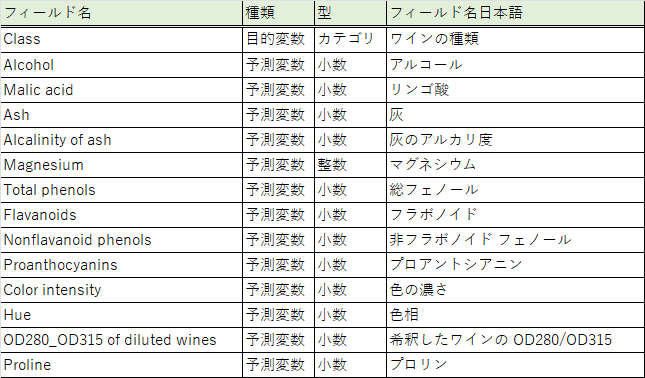
Classはいわゆる答えですね・・・。
さて、これをセレクトツールでデータ型を整えてから、K重心診断ツールに突っ込んでみましょう。

ワークフローとしては以下のようになります。
K重心クラスターではクラスタ数を決めなければなりませんが、クラスタの決定にはK重心診断ツールを使います。
フィールドを標準化しない場合
まず、フィールドを標準化するオプションを使わずにやってみましょう。オプションとしては以下のようになります。
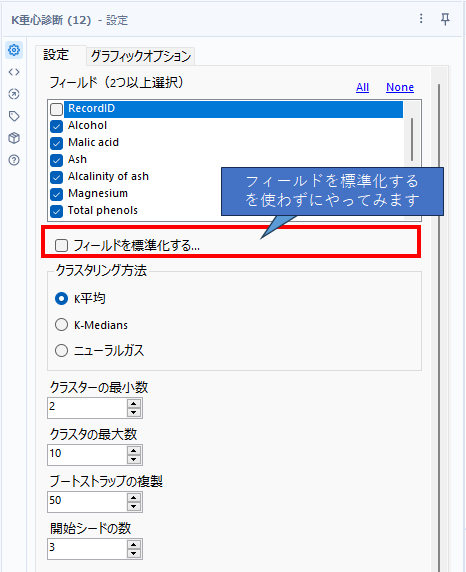
クラスタの最大数は今回は多めにして10にしておきましょう(我々は答えを知っていて、Classが3つあるので正解は3なのですが・・・)。
この結果として、レポートが得られます。以下の「調整ランド指数」と「Calinski-Harabaszインデックス」を見てクラスタ数を決めます。
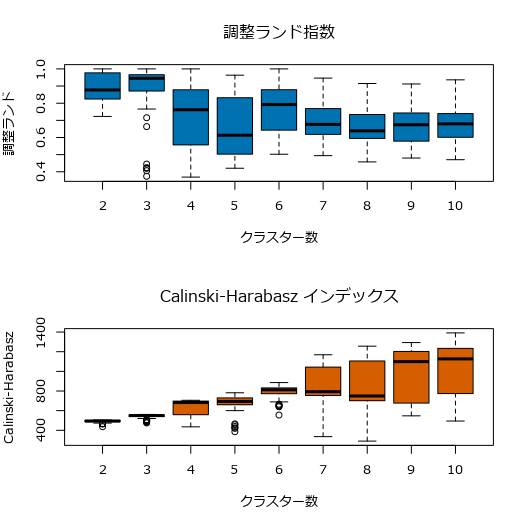
両方のグラフとも値が大きく、箱ひげ図の縦の幅(オレンジもしくは青い部分)が小さいものがベストなクラスタ数と言われています。今回の結果では、下側の「Calinski-Harabaszインデックス」からは非常に判断しづらいです。一方、「調整ランド指数」からは3あたりかな?という気はします。
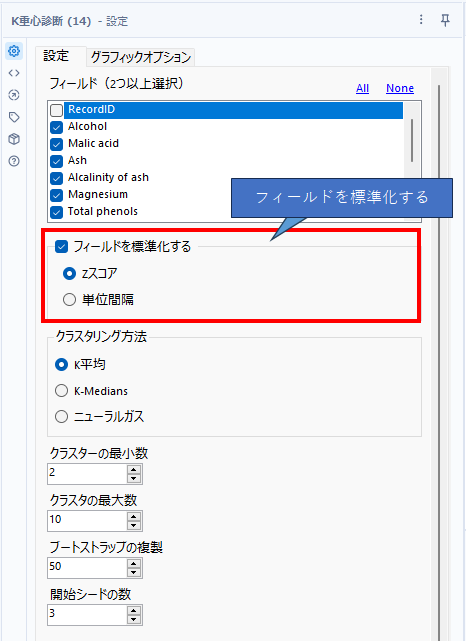
「フィールドを標準化する」オプションを利用する
次に、「フィールドを標準化する」オプションを使ってみましょう。zスコアと単位間隔が選択できますが、今回はzスコアを使ってみましょう。
これにより、以下のような結果が得られます。
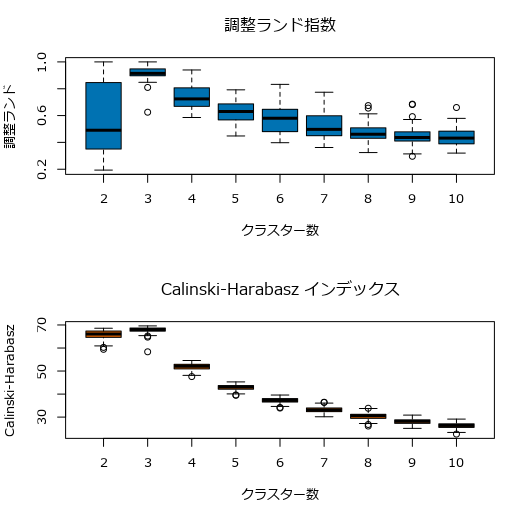
これは「やらせ」なのか?というくらいいい感じのグラフが得られています。この結果ですと、クラスター数は3以外ありえません。
最終的な結果を出力する
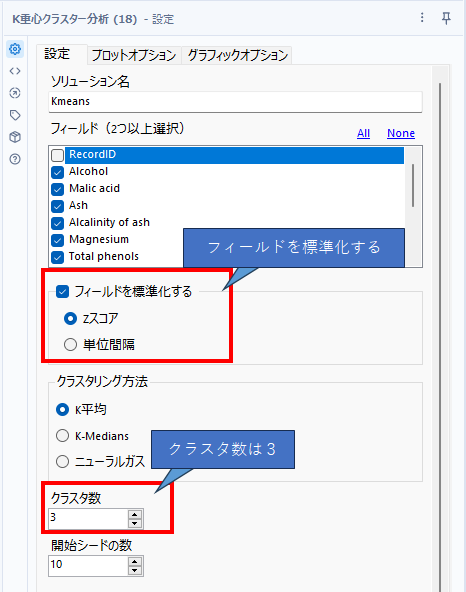
ということで、実際にK重心クラスター分析ツールに同じようにセットします。

「フィールドを標準化する」にチェックを入れ「zスコア」を選択(デフォルト)。クラスタ数は3とします。
そして、そのまま一度実行してから「クラスター付加」ツールも接続しましょう。

K重心クラスター分析ツール内でクラスター付加までやってくれると助かるんですが、なぜか別のツールになっています。ちなみに、設定はクラスタとして付加するフィールド名だけです。これにより、各レコードにクラスタが割り当たります。ワークフローとしては以下のようになります。
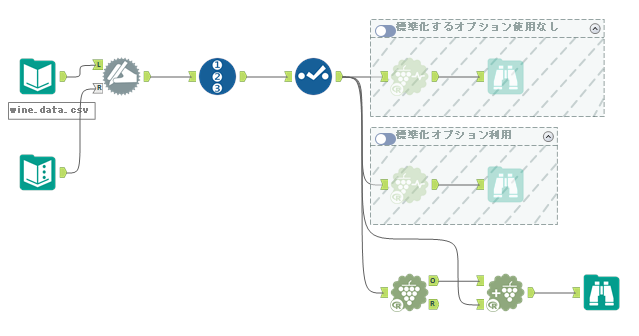
このままだと単に各レコードにクラスタ番号がつくだけで、結果のサマリーがわかりにくいので、混同行列にしてみましょう。以下のようなワークフローになります。
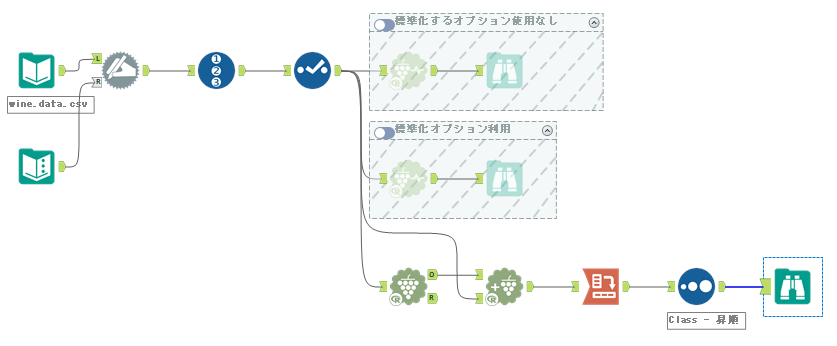
クロスタブの設定は以下のような形です。「以下の値でデータをグループ化」は正解である「Class」です。「列ヘッダーの変更」はK重心クラスター分析ツールで割り当てた「クラスタ」。値としては、そのカウントを取っています。
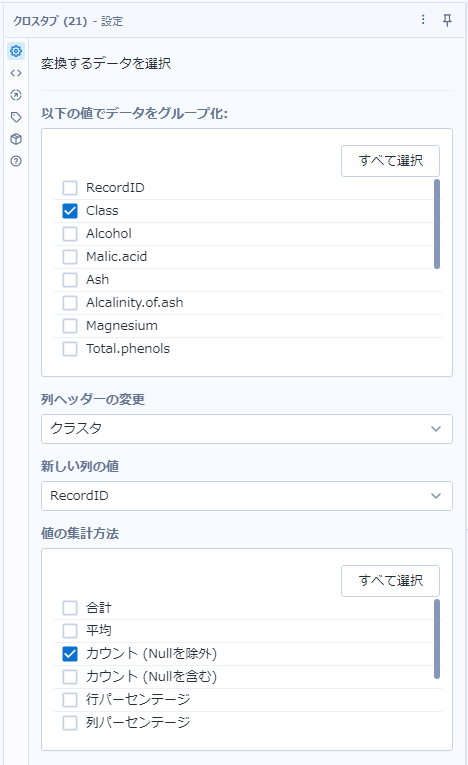
これにより、以下のようになります。
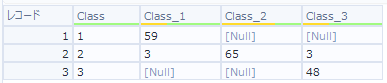
なお、クラスの番号は一致してないので、わかりやすくするためにラベルを変えています。
class=2のレコードで、6レコードほど他のクラスとして誤認識されているということになります。
正しく割り当たった(Accuracy)のは、172/178 = 96.6%ということになります。
今度は、フィールドを標準しなかった場合どうなるか見てみましょう。
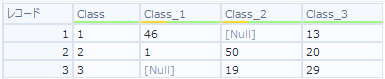
ぱっと見た目でかなり誤認識が多いように思います。Accuracyを計算すると、70.2%と精度もかなり落ちています。
これは、、、フィールドサマリーツールでデータを改めて見てみたいと思います。

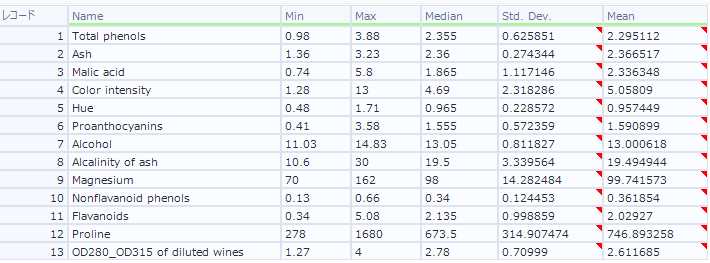
この結果によると、Prolineなどはかなり大きな値になっている一方、HueやNonflavanoid phenoisなどはかなり小さい値を取っています。このように様々なスケールの数値をそのままクラスタリングで使ってしまうと、思ったような結果がでないことがあるので、このように数値のスケールがあっていない場合は、フィールドを標準化しましょう。
まとめ
- K重心クラスターの入力データは、値のスケールが異なる場合には「フィールドを標準化」オプションを使用する
- 各フィールドのスケールは、フィールドサマリーツールなどで確認する

コメント